DeepSeek-R1-Distill-Qwen-1.5B 模型推理
推理的步骤如下:

加载训练之后权重

通过model.generate启动推理:
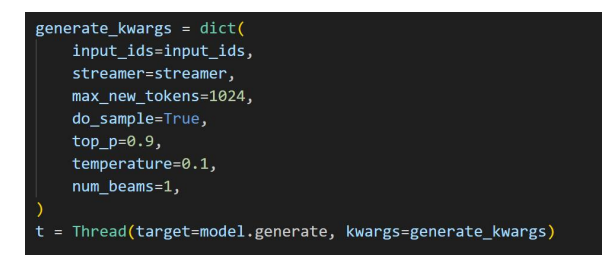
没有优化之前的效果与优化之后的效果进行对比:

效果调优
在进行长文本输出的过程当中,输出回答到一定长度后模型会输出重复内容,如下图所示,可在generate_kwargs中添加repetition_penalty=1.2,解决长文本输出重复问题

性能测试:
凡是在推理过程中涉及采样(do_sample=True)的案例,可以通过配置如下变量,注释掉之前添加的同步模式代码,再运行代码,即可获取每个token的推理时长和平均时长:
export INFERENCE_TIME_RECORD=True
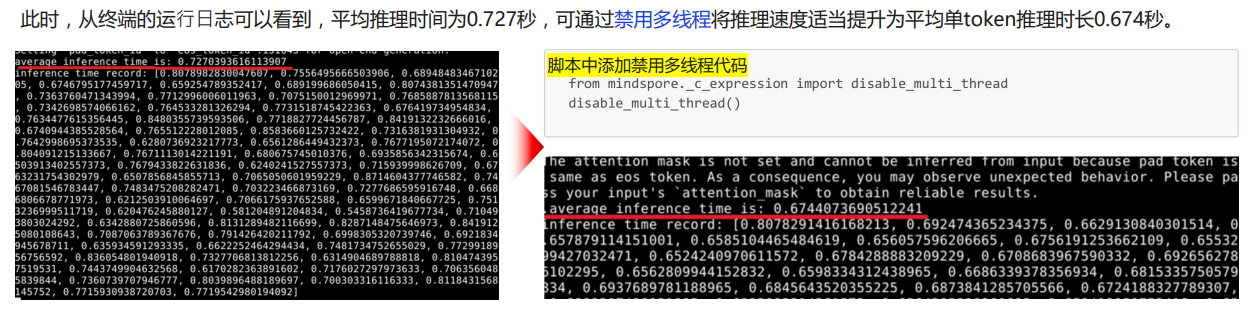
进行jit优化之后的:
与传统的静态编译(AOT,Ahead-Of-Time)不同,JIT 编译器不会在程序启动前就将所有代码编译为机器码,而是在程序运行过程中,按需编译那些被频繁执行的代码段(称为“热点代码”)。程序开始通常以解释器方式运行,解释器逐条执行字节码。同时,JIT 编译器会监控代码的执行频率(称为“ profiling”),当发现某段代码被执行多次(即成为“热点”),就会触发 JIT 编译。虚拟机通过计数器(如方法调用次数、循环回边次数)来识别热点代码。一旦达到阈值,该方法或代码块就会被提交给 JIT 编译器进行编译。
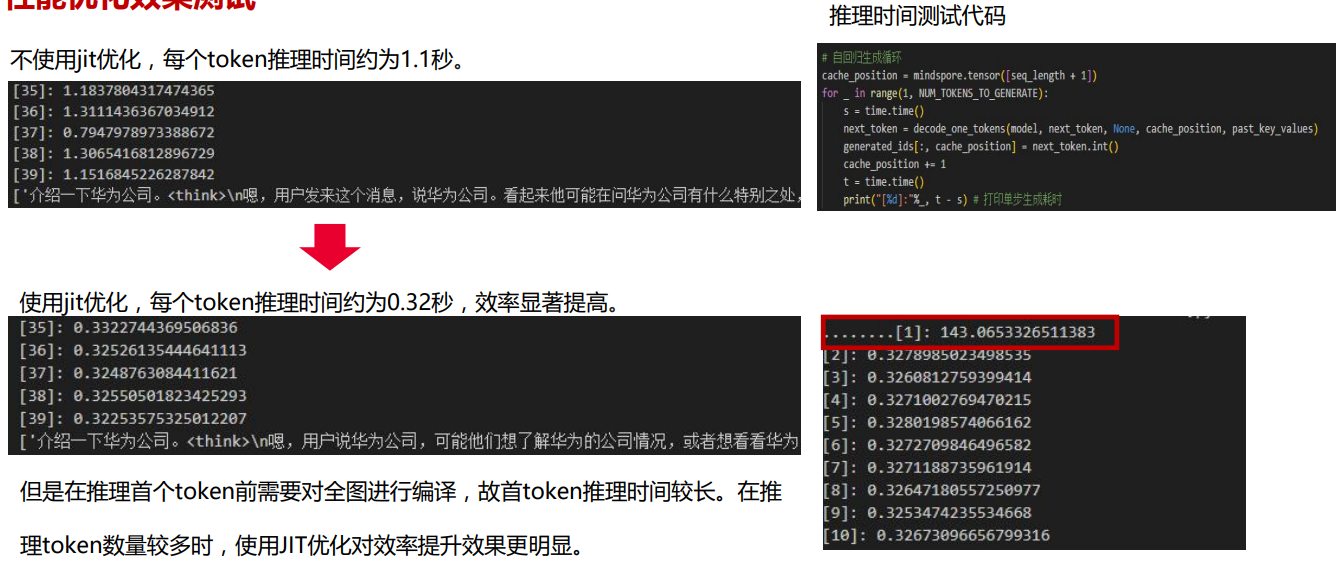
进行推理:
jit优化推理:
可以看除了第一个在编译时耗时73s,其他每个token的推理时间都在0.1s以内。