DeepSeek-R1-Distill-Qwen-1.5B 模型推理
在进行了这一章的学习后,我们学会了如何对模型进行推理。
在前两章的基础上,我们学习了环境的配置和lora的微调训练,我们来进行推理。
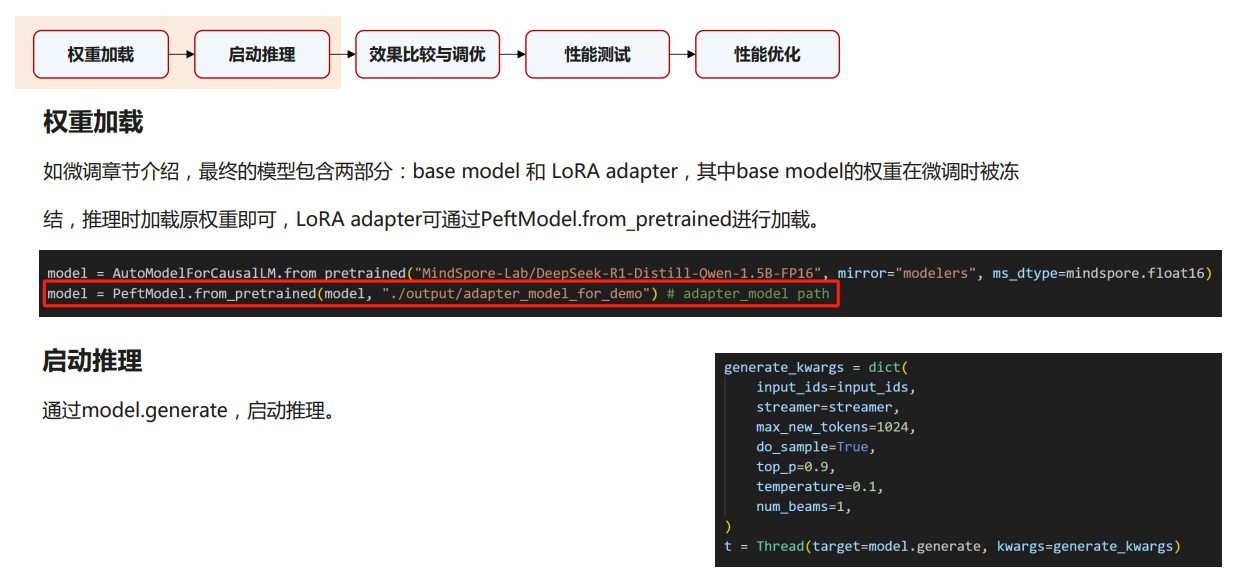
首先是权重的加载:
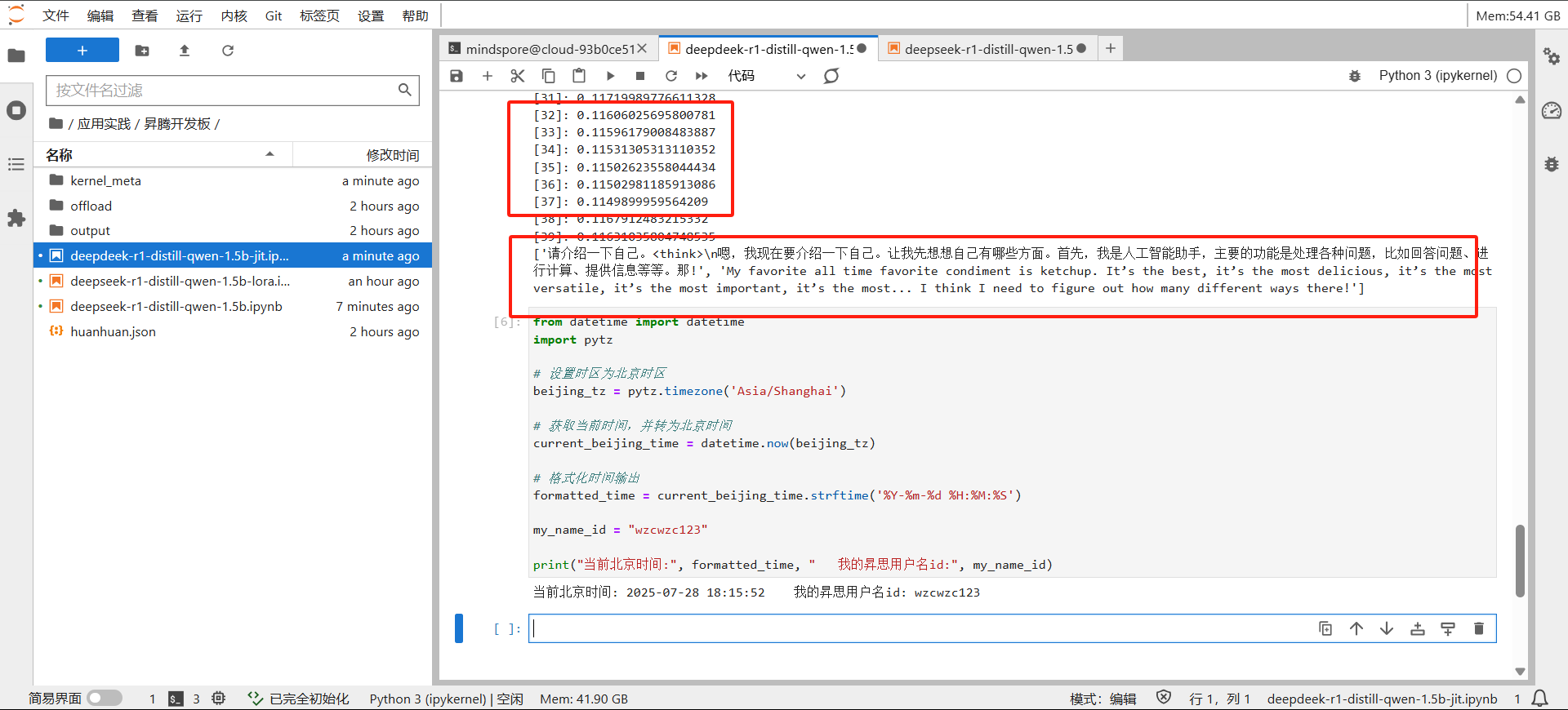
这个是用了lora微调之后的模型,来看一下效果对比:

可以看到效果非常明显了。
效果调优
在进行长文本输出的过程当中,输出回答到一定长度后模型会输出重复内容,如下图所示,可在generate_kwargs中添加repetition_penalty=1.2,解决长文本输出重复问题

对性能做一下测试:
凡是在推理过程中涉及采样(do_sample=True)的案例,可以通过配置如下变量,注释掉之前添加的同步模式代码,再运行代码,即可获取每个token的推理时长和平均时长:
export INFERENCE_TIME_RECORD=True
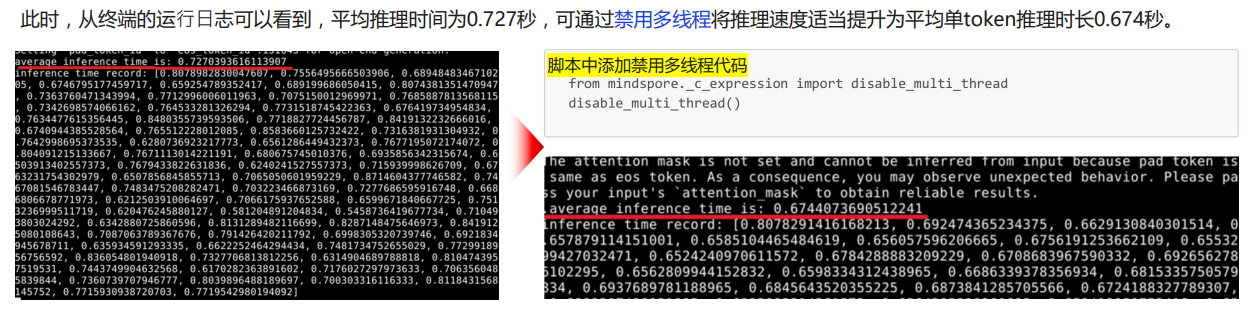
对新能做一下优化:
通过上述禁用多线程的方式,可以适当减少平均单token的推理时长,但效果不明显。在此基础上,还可以通过jit即时编译的方式进一步加速jit即时编译通过jit修饰器修饰Python函数或者Python类的成员函数使其被编译成计算图,通过图优化等技术提高运行速度。在本章节的场景下,jit修饰器应该修饰模型decode的函数,但由于原代码将模型的logits计算、解码等过程整体封装成了一个model.generate函数,不好进行优化,所以需要手动实现解码逻辑。
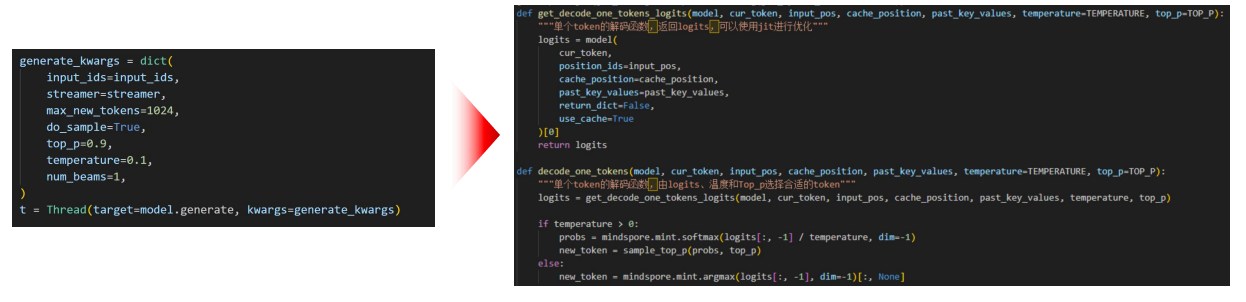
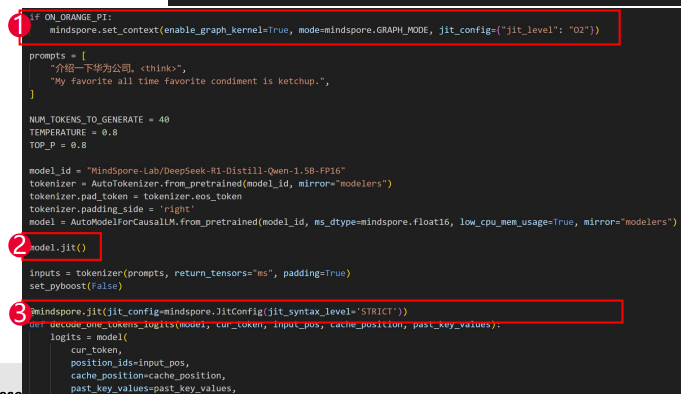
其中主要的思想是:
添加jit装饰器
- 设置O2整图下沉进一步优化
- model.jit()
- mindspore.jit装饰decode函数
优化效果:
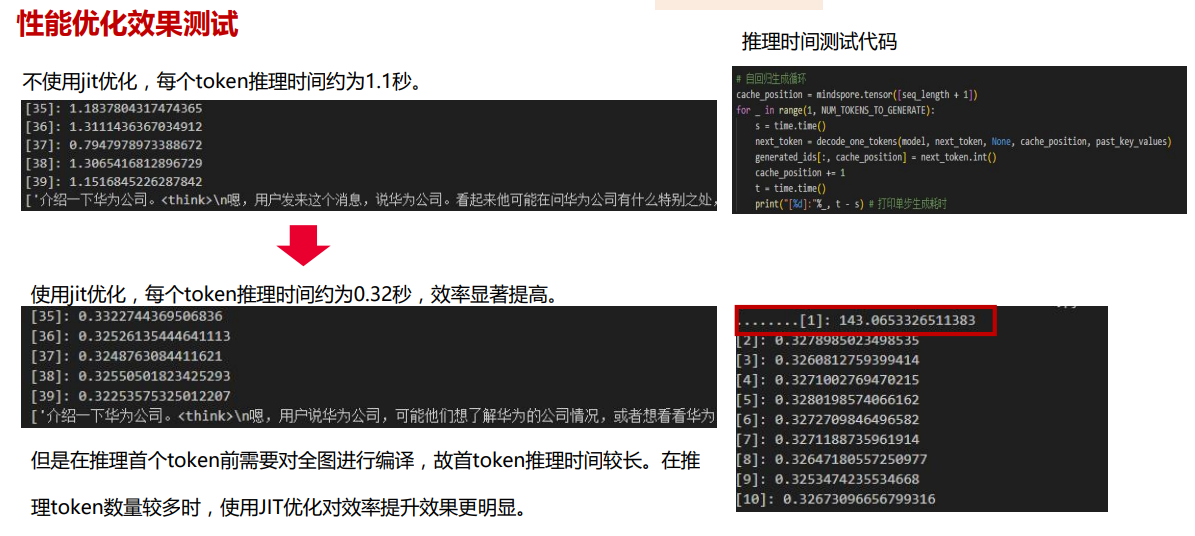
性能优化-经验分享:
- Top_p函数的实现 出于效率的考虑,优先使用numpy进行函数的实现 而在gather函数的实现上,基于mindspore.mint的实现方式会出现报错,故使用mindspore.ops来实现。
- modeling_qwen2.py的decoder_layer中,需添加_modules.values()
实操推理:
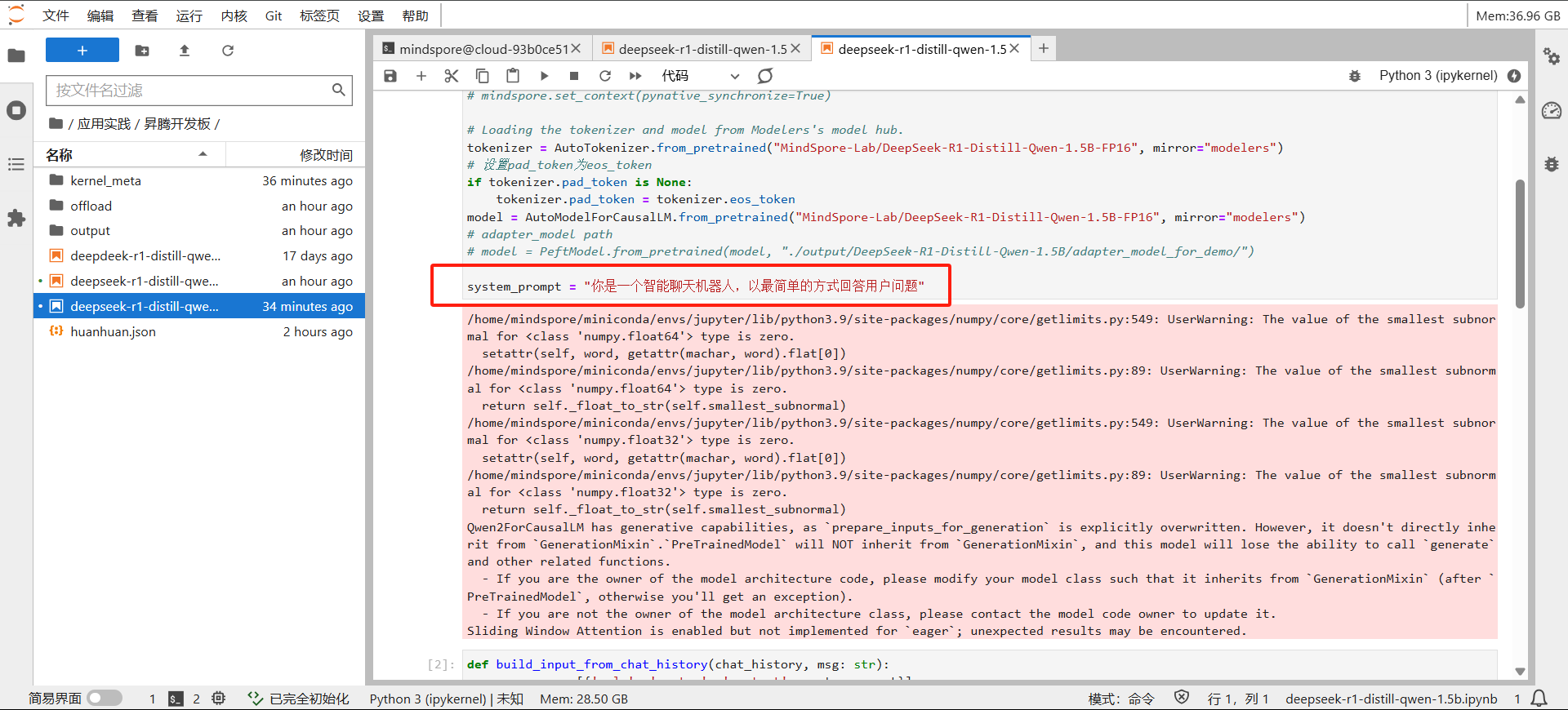
设置prompt:
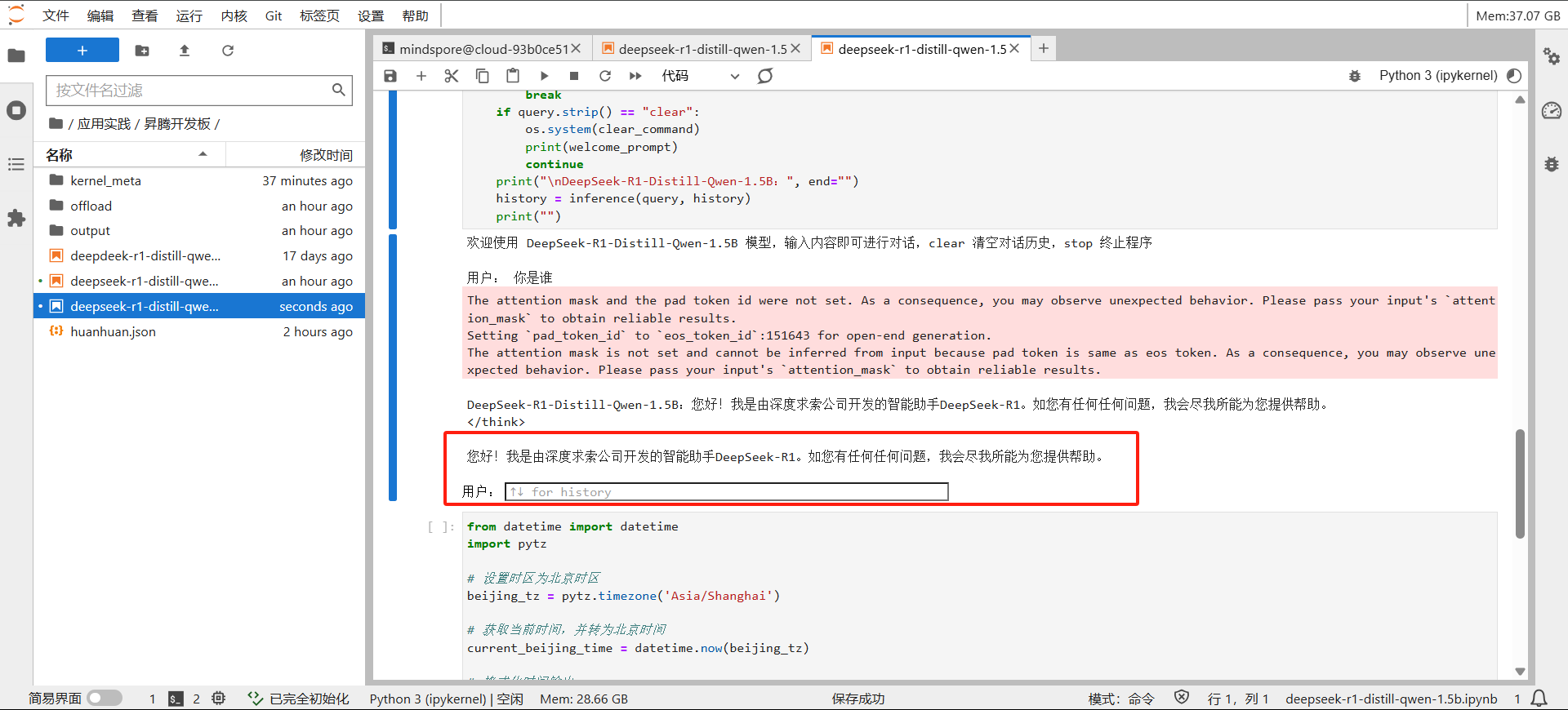
进行对话:
jit优化实操:
开启O2级别的jit优化,开启图算融合:
设置prompts:
完成每一步时间推理计算: