昇思+昇腾开发板:软硬结合玩转DeepSeek开发实战(学习打卡第三天)
1.DeepSeek-R1-Distilll-Qwen-1.5B模型推理
推理流程:

权重加载
base_model(第二天的蓝色部分)是冻结的,对橙色部门(loRA adapter)进行微调,最后蓝色部门和橙色部分相加输出
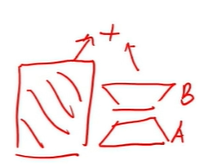
最终模型包含两个部分:base model 和LoRA adapter,其中base model的权重在微调是被冻结,推理时直接加载原权重加载即可,LoRA adapter可通过from_pretrainted进行加载。
超参的修改
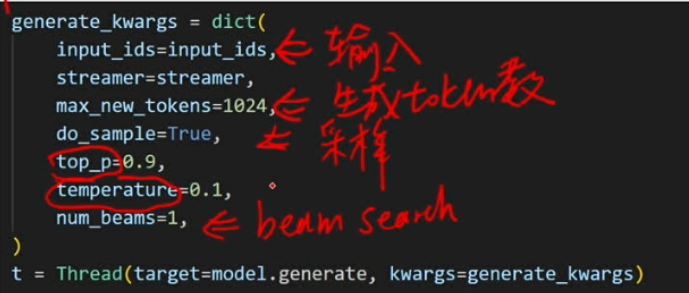
model最终会生成一个logits(词表——每一个词对应一个可能性,可能性高的就会作为下一个词输出),通过贪心算法搜寻可能性最高的
num_beams是束搜索的beam数
启动推理
model.generate
效果优化与调优
微调后,模型可以实现模仿甄嬛的语气,但是输出回答到一定长度后模型会输出重复内容;
解决方案:在generate_kargs中添加一个参数**repetition_penalty(对重复进行一个惩罚)**来限制重复输出。

性能测试
export INFERENCE_TIME_RECORD=True
配置上述变量,即可获取每一个token的推理时长和平均时长(可以直观的查看模型的性能)
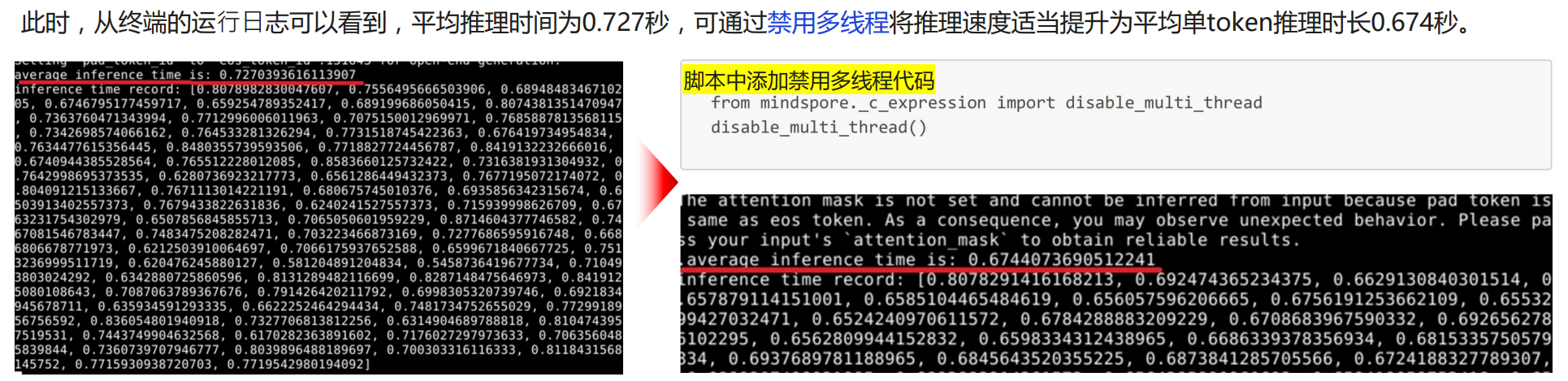
正常代码运行的平均推理时间为0.727秒,禁用多线可以提升0.05秒,如何禁用:看下图在脚本中添加相应的代码。
性能优化
a.jit即时编译
JIT 即时编译是一种动态编译技术,在程序运行时,将频繁执行的代码(热点代码)从字节码或中间代码实时编译为机器码,从而提升程序执行效率。
jit修饰器修饰python函数或者Python类的成员函数使其被编译成计算图,通过图优化等技术提高运行速度
我们可是使用jit修饰器修饰模型decode的函数,但这里有一个问题,就是源代码封装的太好了,logits计算和解码过程封装成了model.generate函数;因此不好进行优化,所以需要手动实现解码逻辑
前序准备:
1.实现解码逻辑(decode函数,prefill-decode阶段)
在大语言模型的工作流程中,decode(解码)和 prefill(预填充)是两个关键阶段,二者配合完成从输入到输出的生成过程:
prefill(预填充)阶段:可理解为 “准备阶段”,模型会先对输入的完整提示文本(如问题、指令等)进行一次性处理。它会同时计算整个输入文本的上下文信息,将所有输入内容转化为模型可理解的表示形式并存储起来,为后续生成输出做准备。这一阶段的计算量与输入文本长度相关,通常一次性完成,耗时相对固定。
decode(解码)阶段:类似于 “写作过程”,是模型生成输出内容的阶段。它基于 prefill 阶段处理好的上下文信息,逐词生成回答:每次只生成一个token(词),且每个新词的生成都依赖于之前所有生成的内容(包括输入文本和已生成的输出部分)。这一阶段具有顺序执行、依赖记忆的特点,其总耗时与最终生成的回答长度直接相关,回答越长,所需时间也越长。
2.实例化StaticCache,动态Cache无法成图
StaticCache是事先,我们会申请一块很大的空间,这块空间可以存下输出数据,之后只需在对应的位置修改数据即可;
动态Cache会随着计算进行更新,长度是会变化的
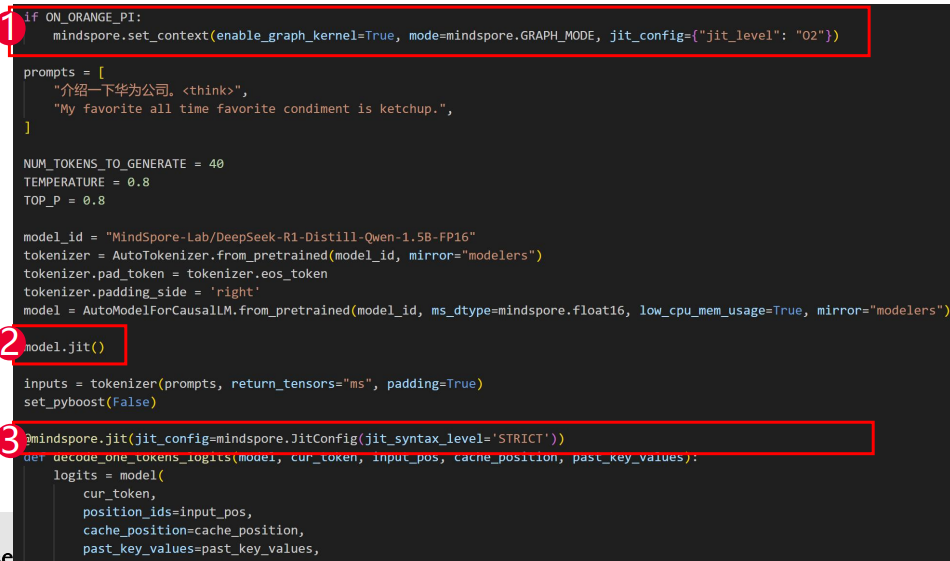
添加jit装饰器:
1.设置O2d整图下沉进一步优化
2.model.jit()
3.mindspore.jit装饰decode函数
b.top_p函数的实现
出于效率的考虑,优先使用numpy进行函数的实现 而在gather函数的实现上,基于mindspore.mint的实现方式会出现报错,故使用mindspore.ops来实现
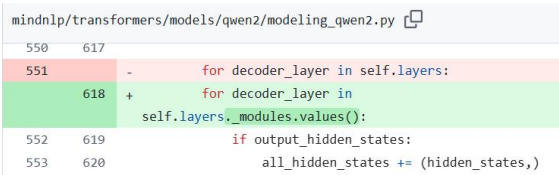
c.decoder_layer修改
在modeling_qwen2.py的decoder_layer中,添加_modules.values()
性能测试
经过上述的性能优化后,尤其是使用了jit优化后,时间得到大大的缩减,效果显著提高

2.实操
首先进行一个环境的安装和配置,由于每次都需要进行mindspore和MindNLP组件的下载和安装,因此,直接将环境安装写入脚本,通过运行bash run.sh,进行环境的安装。
# 克隆仓库
git clone https://openi.pcl.ac.cn/MindSpore/mindnlp.git
# 进入仓库目录
cd mindnlp || { echo "进入 mindnlp 目录失败"; exit 1; }
# 查看所有分支
git branch -a
git checkout 0.4
# 执行构建并重新安装脚本
bash scripts/build_and_reinstall.sh
# 返回上一级目录
cd ..
pip install openmind_hub
# 检查 mindspore 是否正确安装并运行测试
python -c "import mindspore; mindspore.set_context(device_target='Ascend');
mindspore.run_check()"
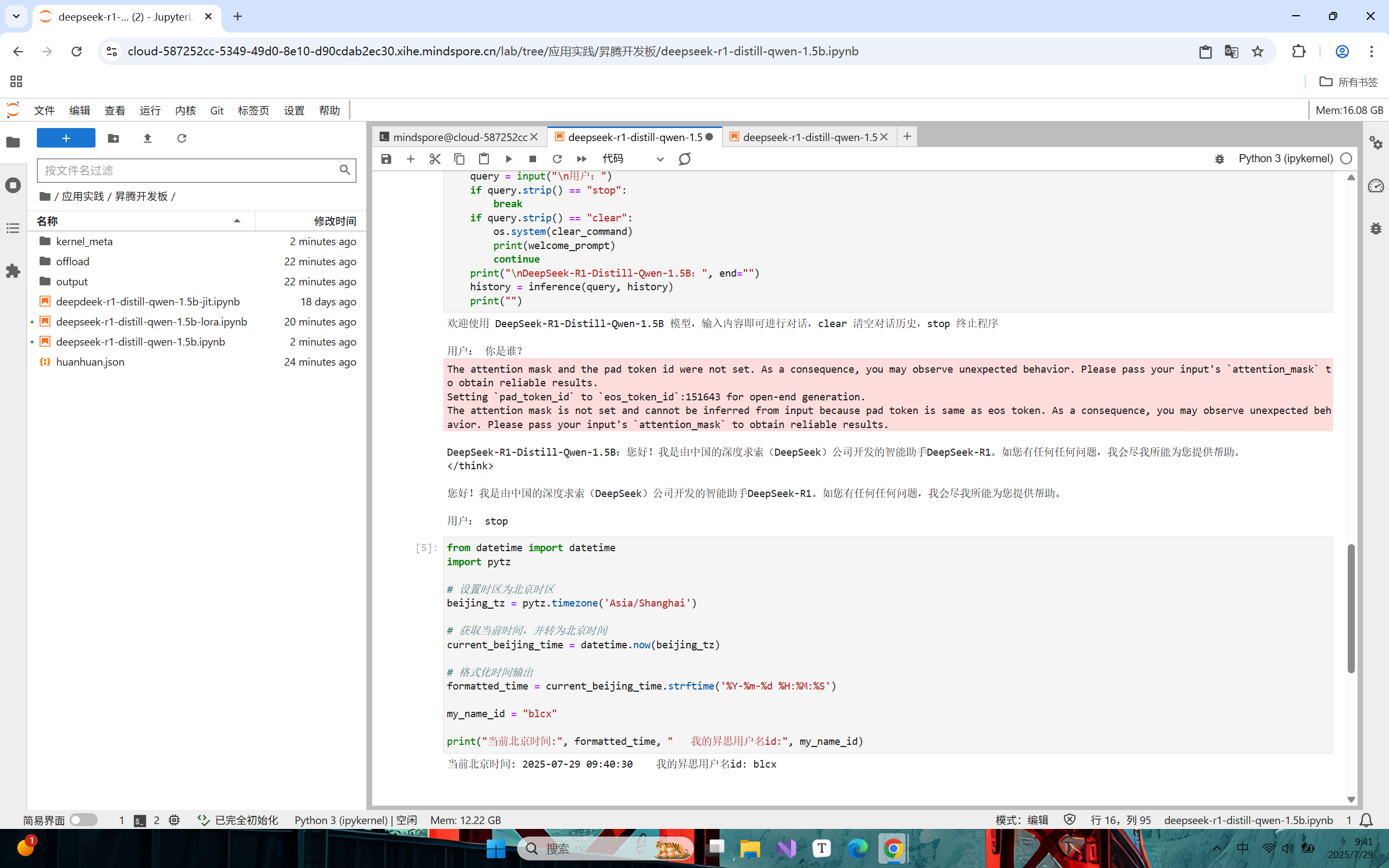
模型推理的结果
可以看到可以进行简单的一个互动和交流
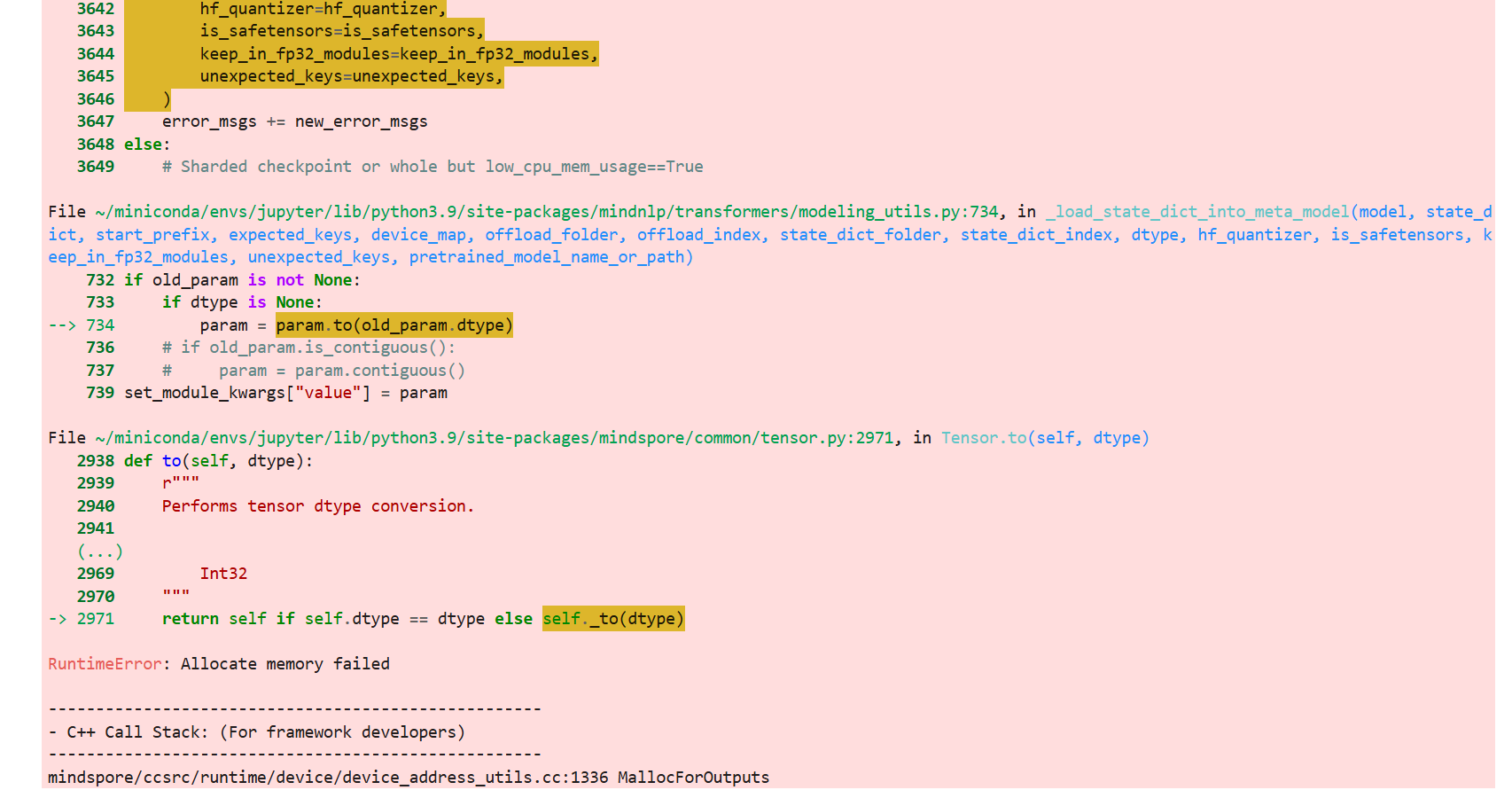
问题处理
如果遇到下述allocate memory failded的问题报错,其原因是内存分配失败,意味着程序在尝试分配内存时,系统无法提供足够的内存资源
通过npu-smi info指令可以查看NPU使用情况,像我就是有两个进程占用了NPU,没有多余的空间。

这时只需将所有的进程kill掉就可以,成功运行了
kill 3570
kill 3932
jit优化后的模型推理结果