昇思学习营第七期·昇腾开发板 学习打卡 第三次(模型推理和性能优化)
DeepSeek-R1-Distill-Qwen-1.5B模型推理和性能优化
DeepSeek-R1-Distill-Qwen-1.5B模型推理
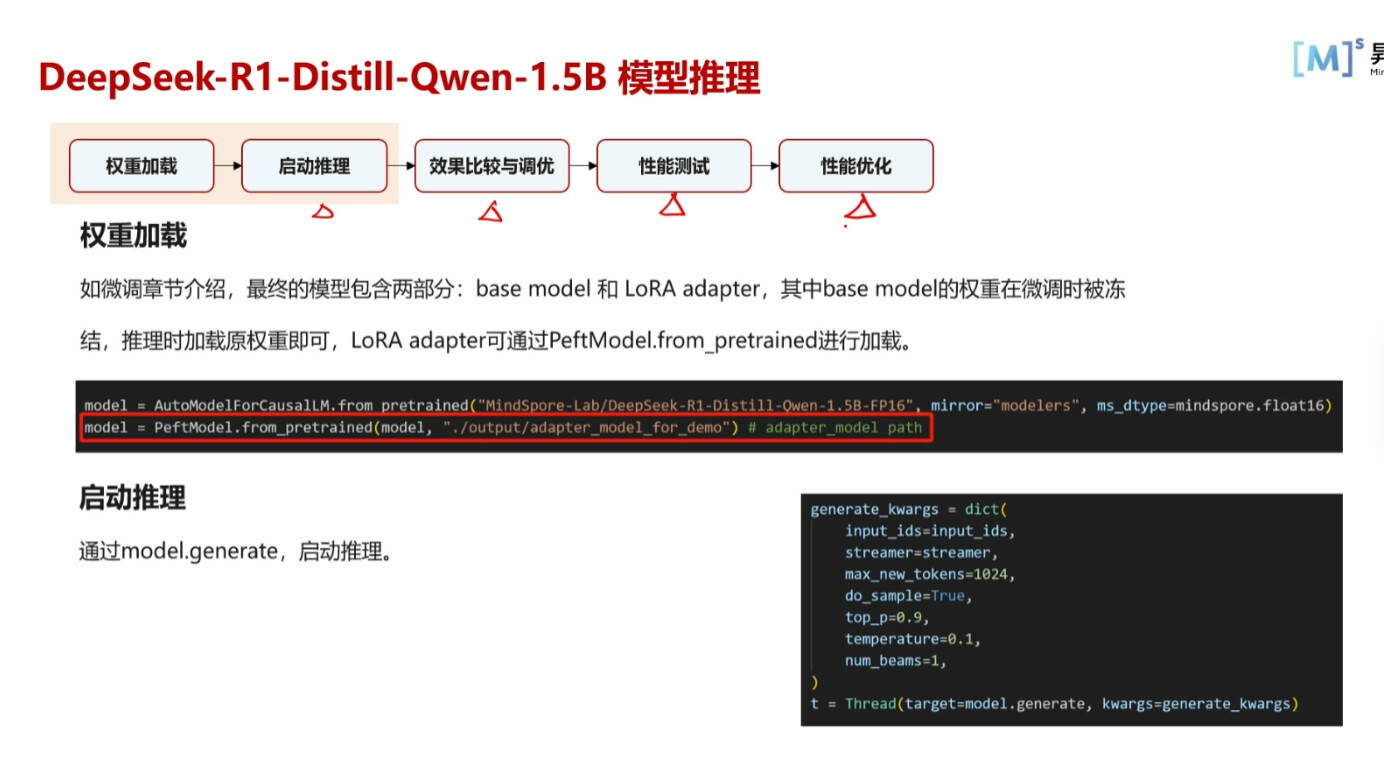
第一步是加载的base model中的权重
第二步是我们的LoRA adapter权重
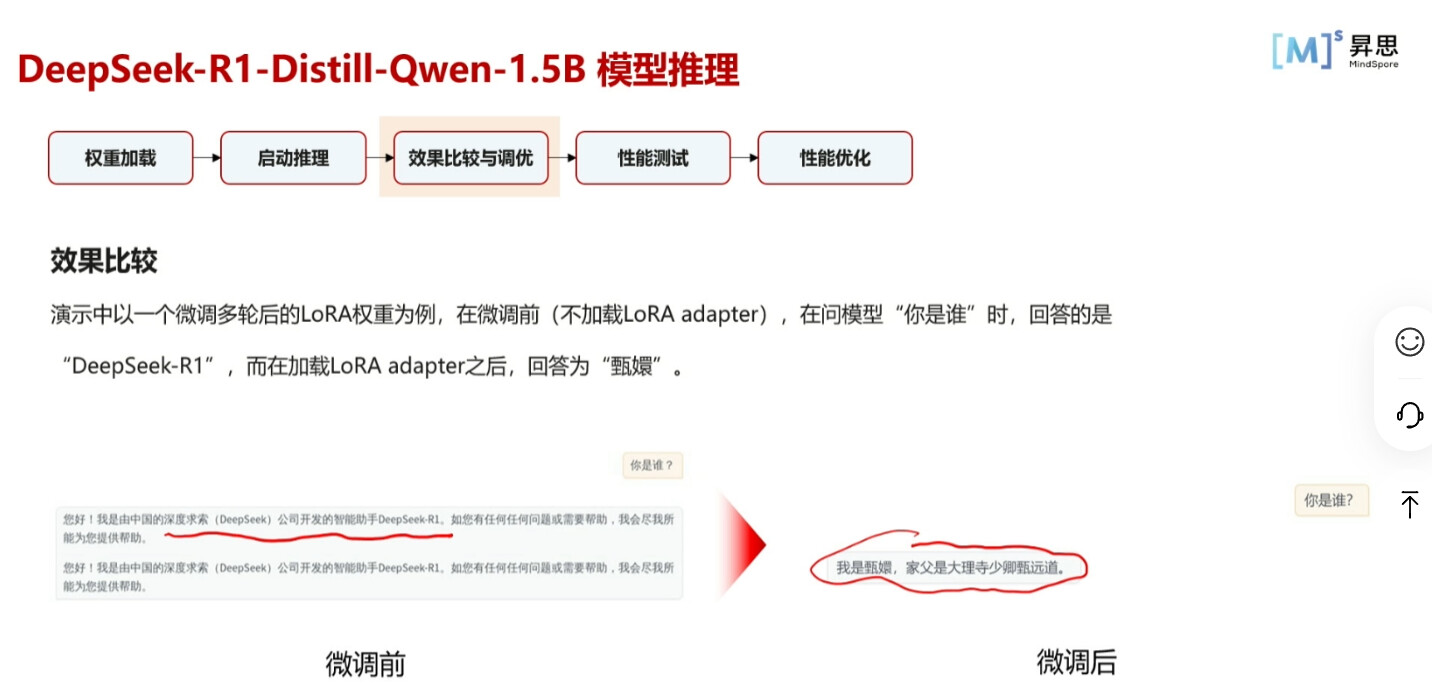
模型微调前后的推理区别
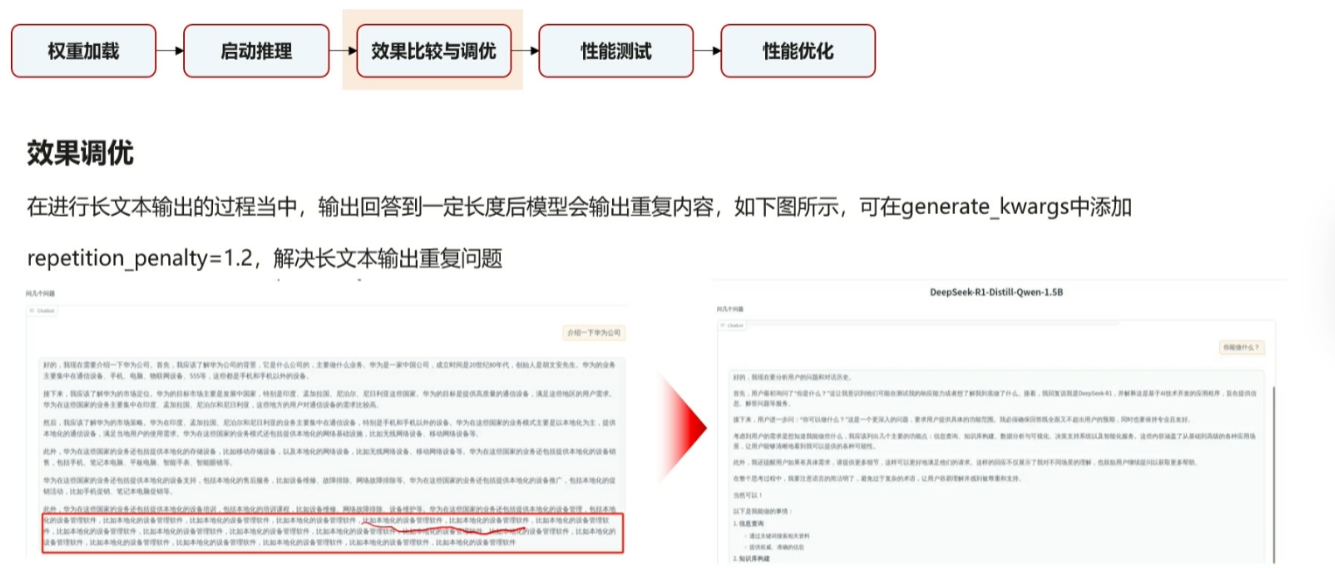
之前在微调过程中遇到过类似的问题现在也终于会解决了
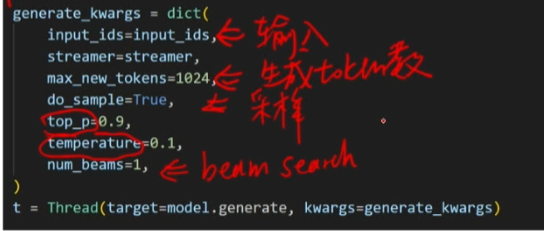
如何获取每个token的推理时长和平均时长
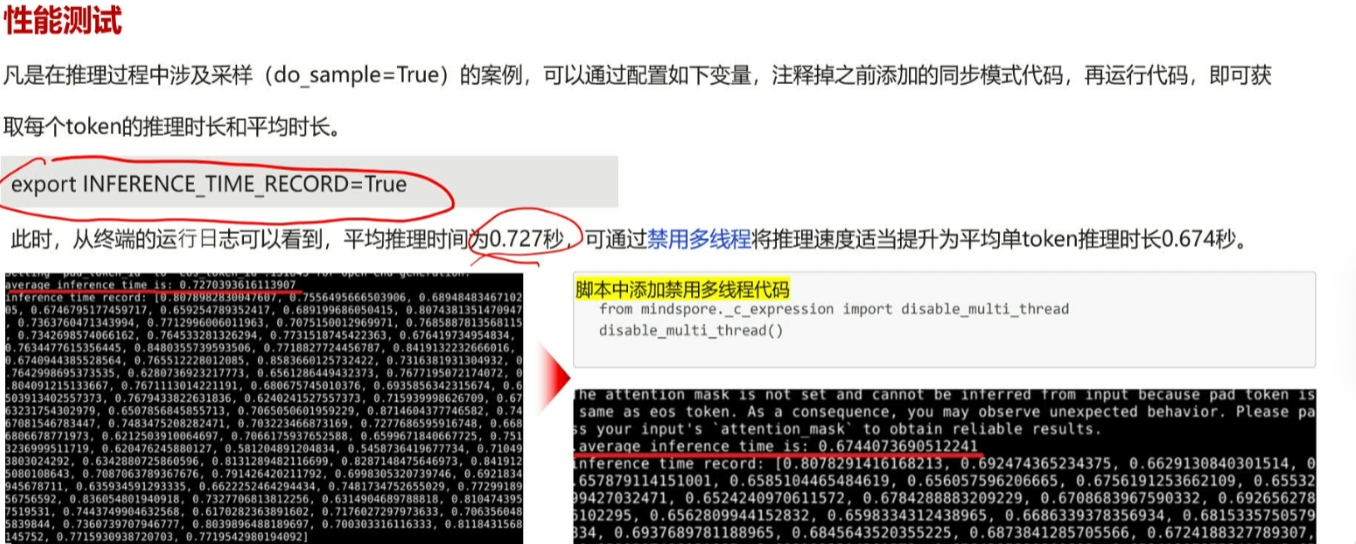
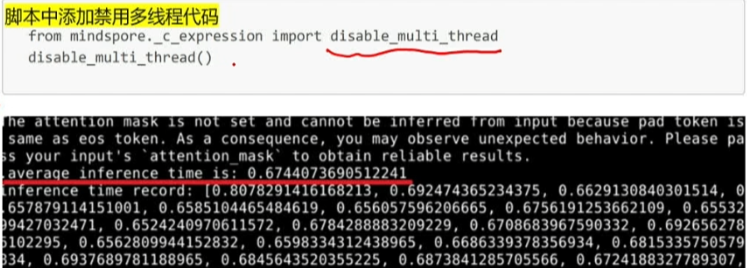
开发板推理的开销NPU其实很快所以禁用多线程会节省时间
动态图可以即时调整,开发调试以动态图为主,在进行性能提升时再切换成静态图。
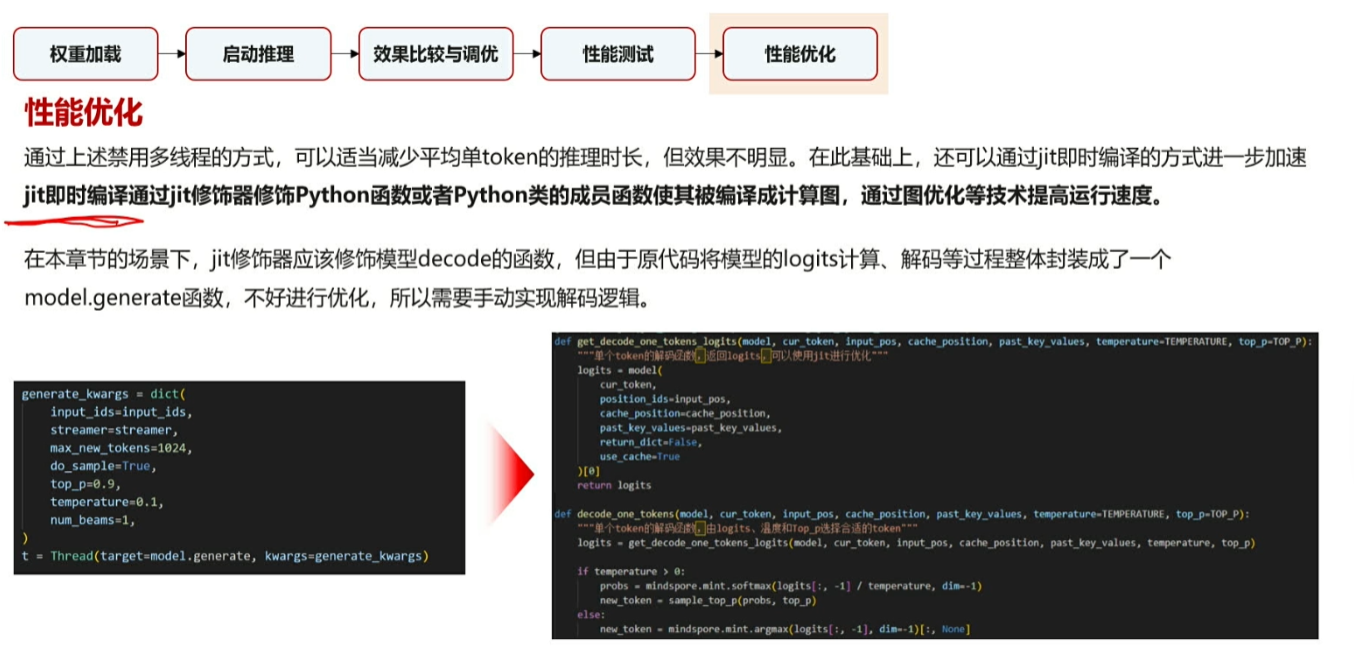
通过mindspore.jit做即时编译
性能进行进一步优化,添加jit装饰器
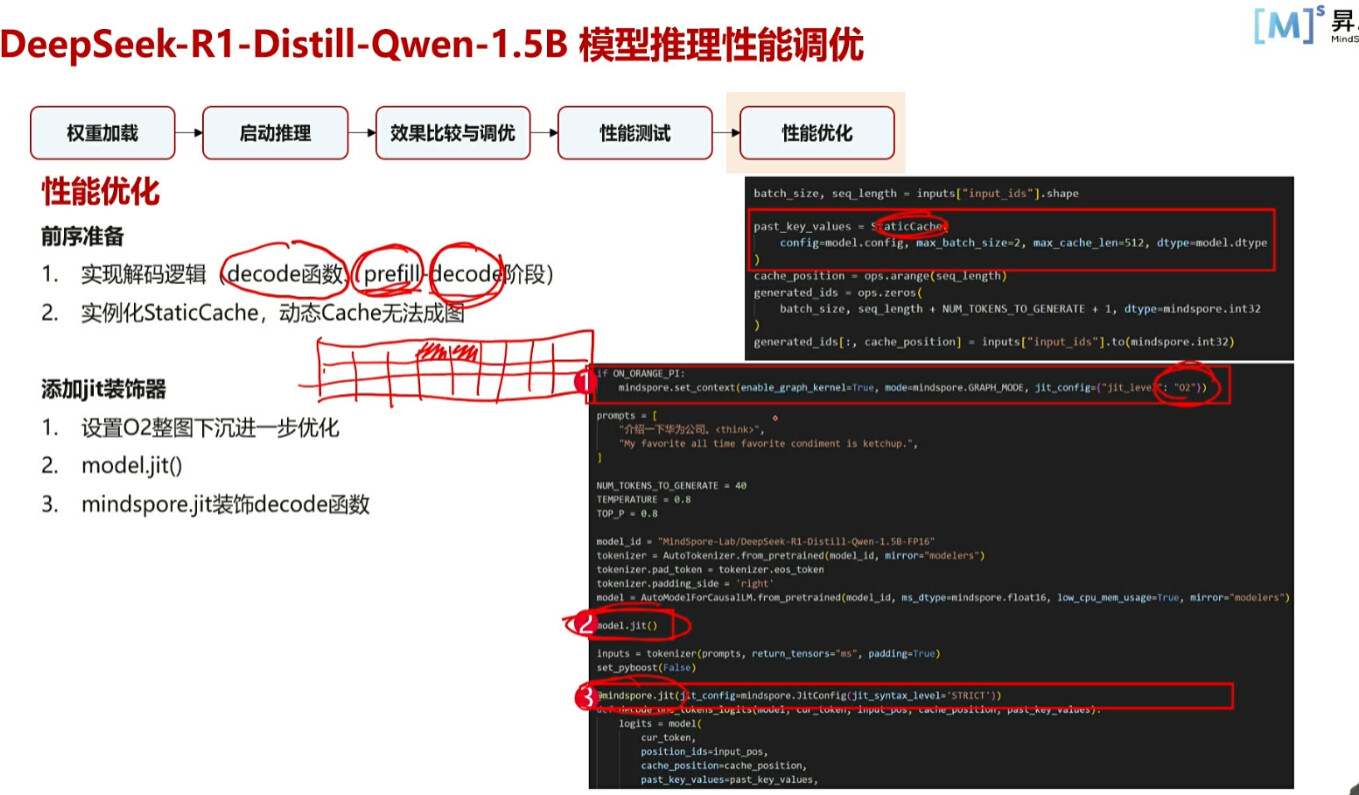
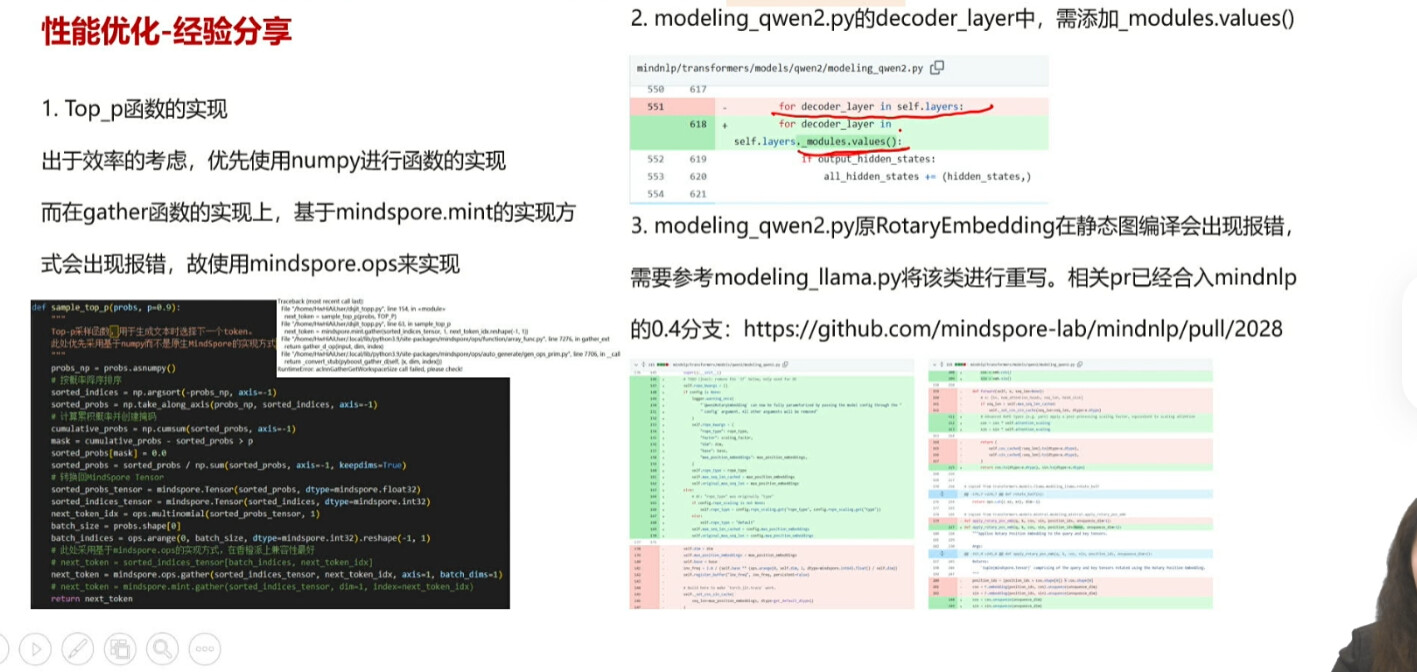
在编译成图的情况下要完成2,RotaryEmbedding为旧的写法,可能在新版环境会报错,所以可以进行重写
做完优化后的性能优化效果测试
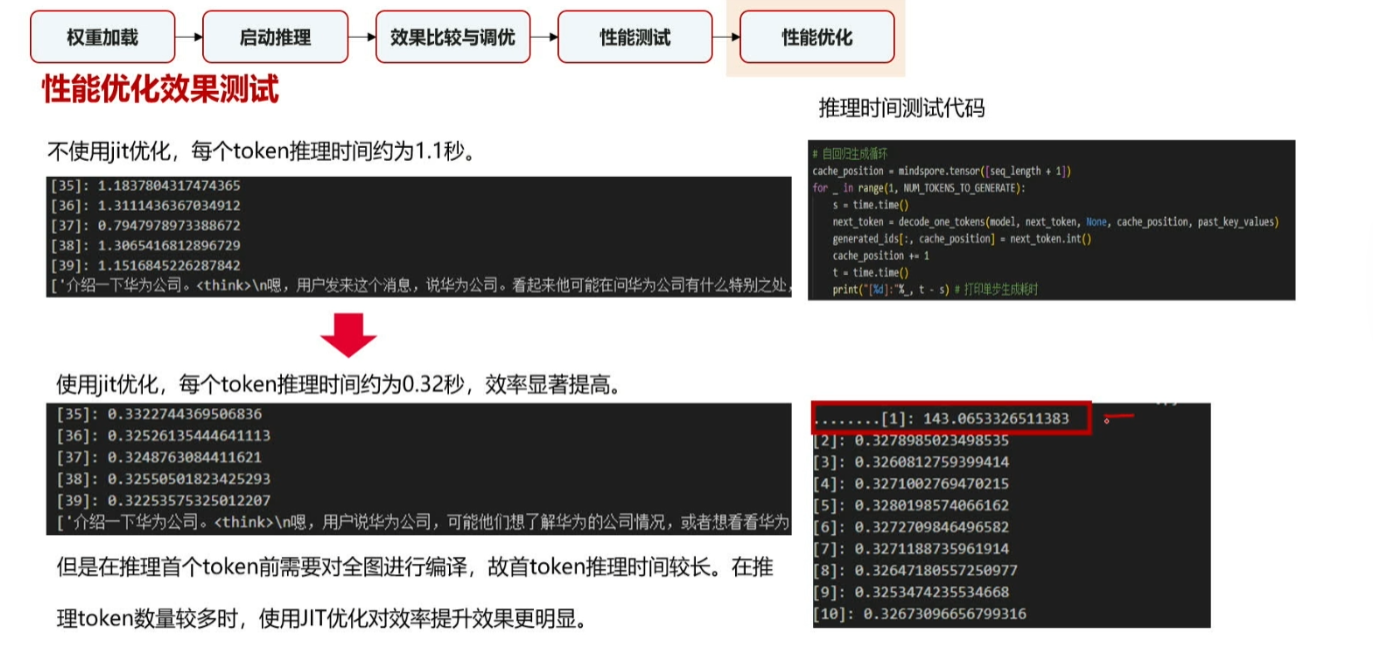
第一个token需要编译时间即冷启动时间,所以时间比较长,但之后的速度会很快
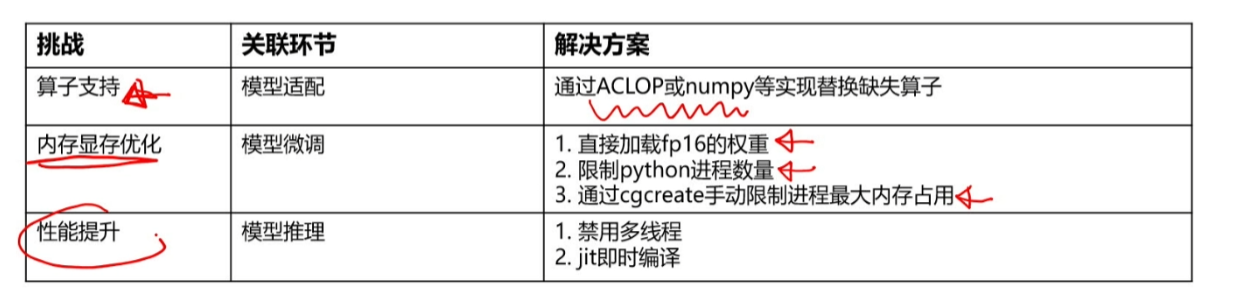
本次课程学习到了模型推理以及性能调优,其中模型推理在之前进行模型迁移时候就有过很充分的涉及,主要在课后需要掌握性能优化,其中对于图编辑的内容之前没有接触过,可能在后续需要重点掌握,另外Mindspore.jit也需要实践锻炼
现在我们在Jupyter中实操一下推理过程以及调优过程
我们先在终端中配置好环境然后找到模型推理python块,添加上自己的用户名id块后运行此程序就可以得到推理结果,当然我们还可以更换模型目录来用其他模型就行推理
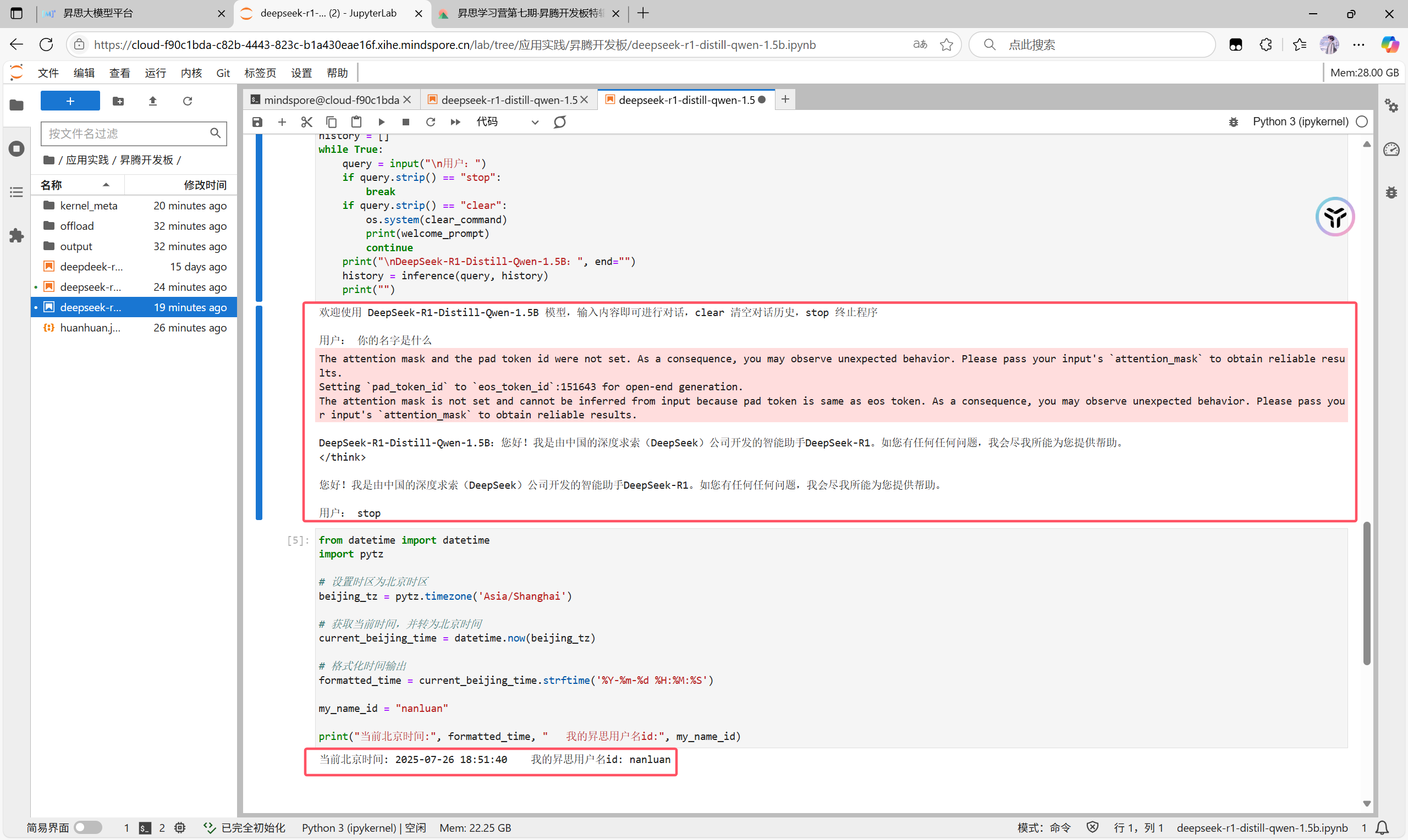
之后我们进行调优的实操,我们找到此板块
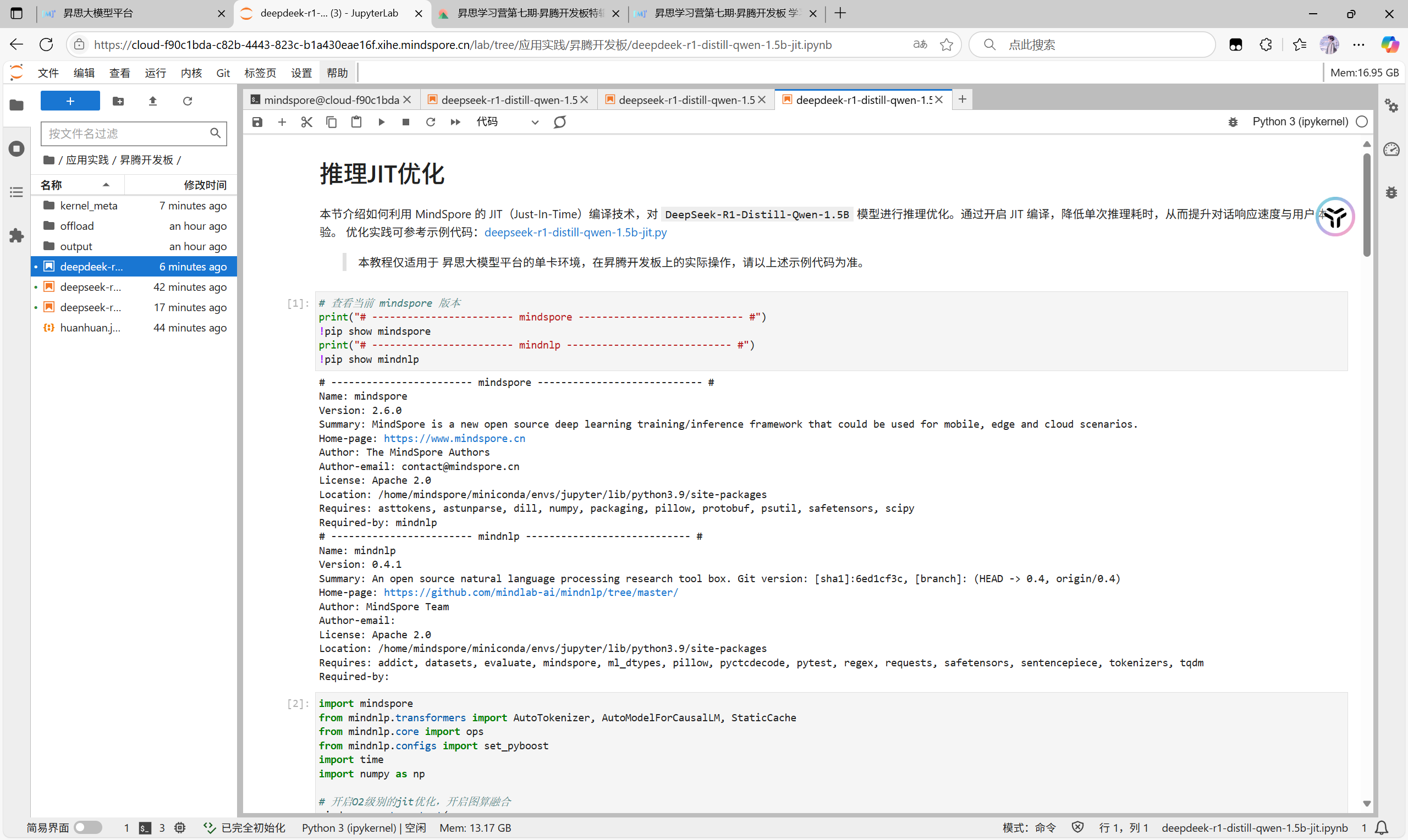
也是和之前一样的操作加上自己的id块然后运行
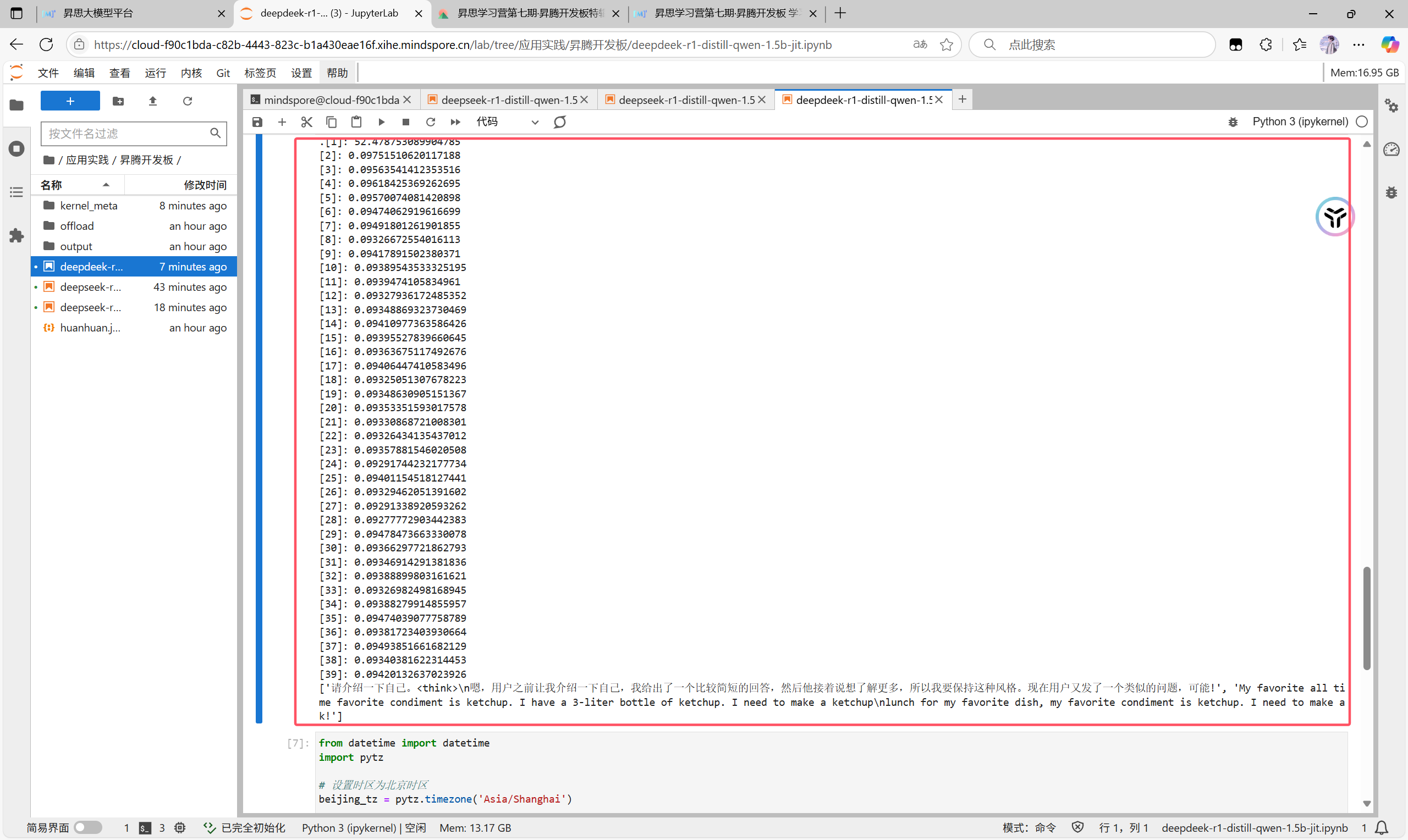
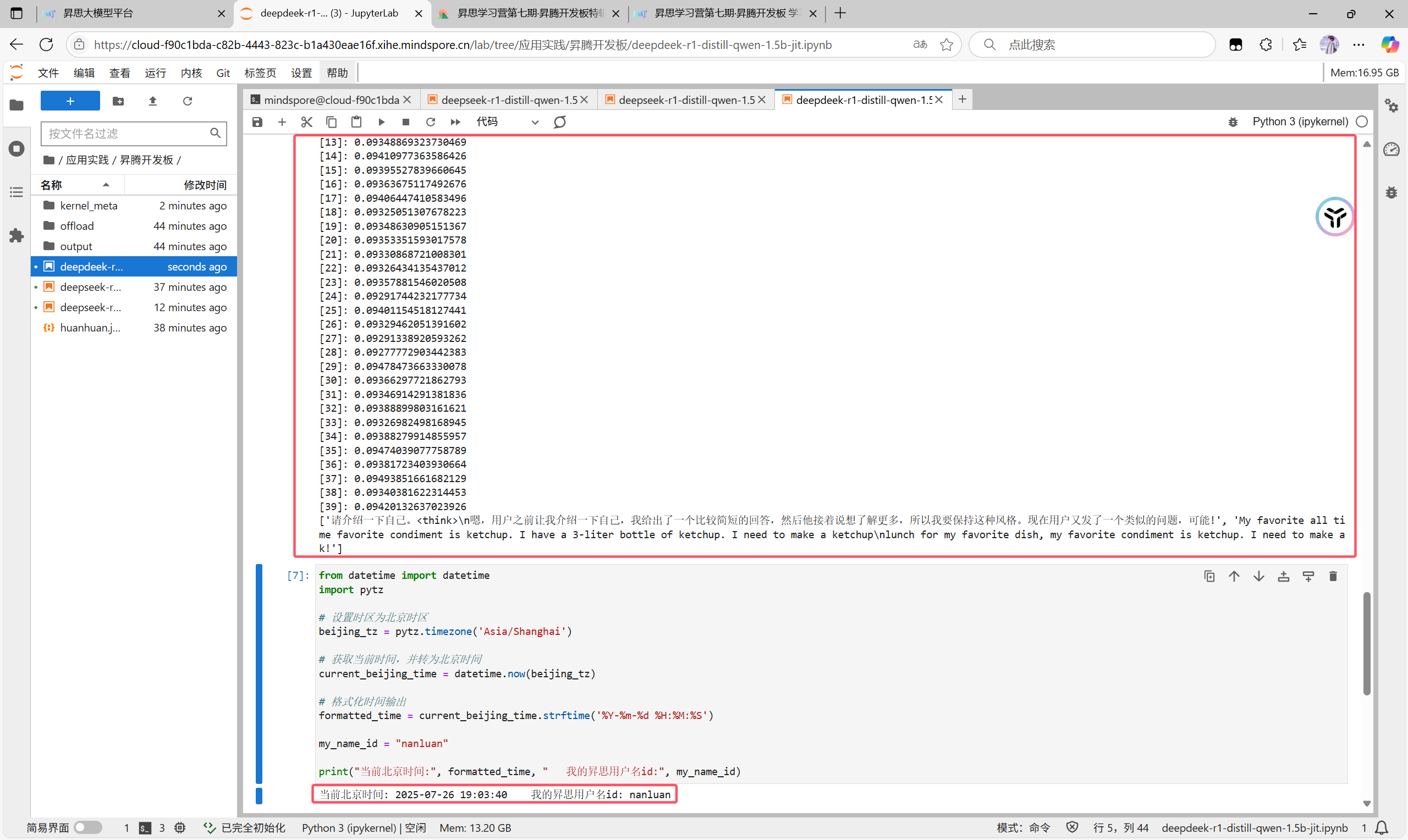
我们可以看到结果与我们视频中预计的结果类似,第一个token比较长,因为此时在冷启动,后面的时间就短很多,我们验证成功