今天学习了课程的第5章,基于昇思大模型平台,对 DeepSeek-R1-Distill-Qwen-1.5B 模型进行推理部署,并构建一个可交互的对话机器人;同时利用MindSpore的JIT(Just-In-Time)编译技术,对模型及逆行推理优化,降低单次推理耗时,提升对话响应速度与用户体验。
模型推理
将用户消息和历史对话拼接成完整上下文,通过多线程机制启动模型生成回复,同时实时流式输出每个生成的token,最后将完整回复添加到对话历史中返回。
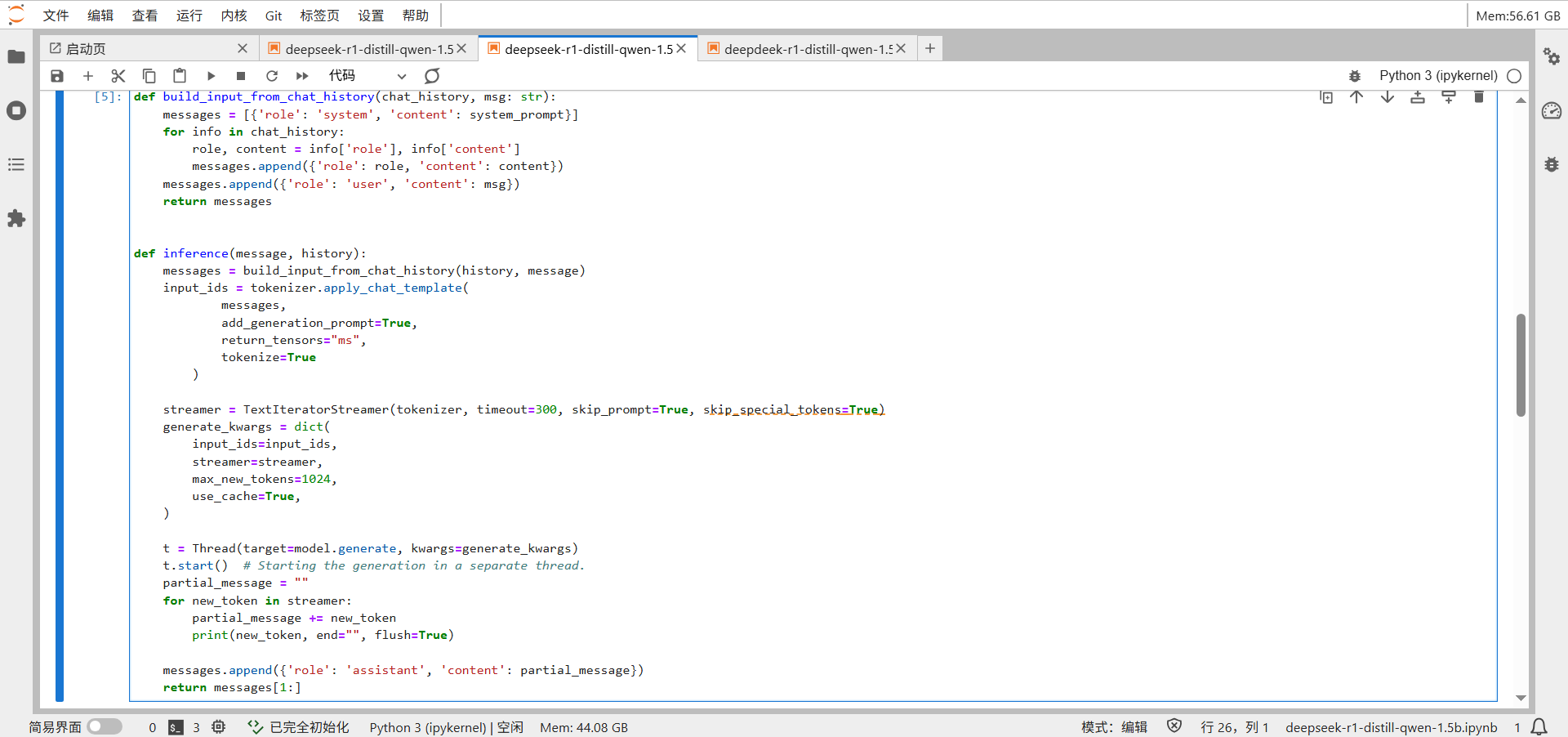
持续接收用户输入,支持"clear"命令清屏重置对话、"stop"命令退出程序,其他输入则调用前面的推理函数生成回复并实时显示,同时维护完整的对话历史上下文。
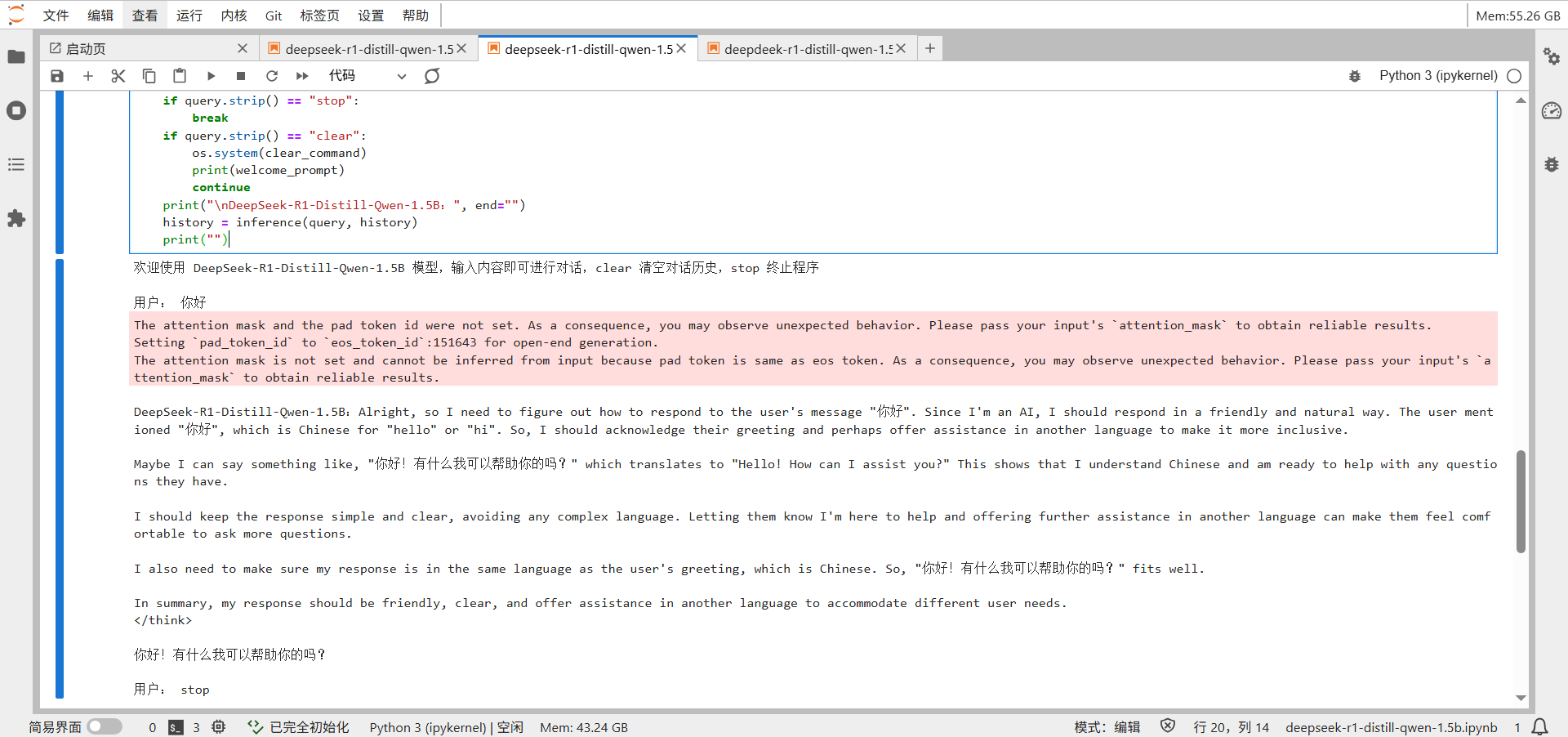
推理JIT优化
开启O2级别的jit优化,开启图算融合
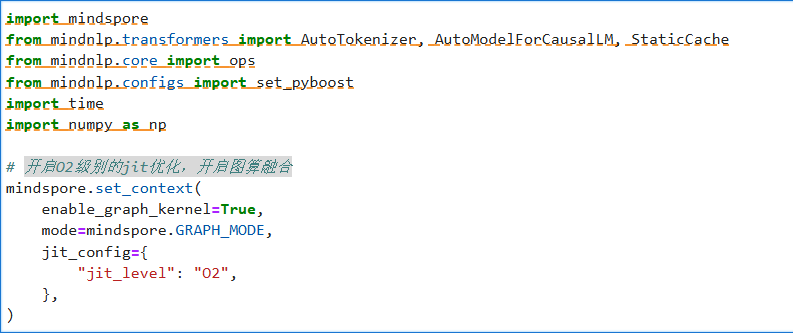
实现Top-p采样算法的高效硬件适配版本:将概率分布转为NumPy数组进行快速排序和掩码处理,筛选出累积概率超过阈值p的高概率token子集并重新归一化,最后通过MindSpore的gather操作实现批量采样。
定义JIT编译优化的单步解码核心函数 ,使用MindSpore的@jit 装饰器将模型推理操作编译为高效机器码,专门用于在文本生成循环中快速获取下一个token的logits值。该函数接收当前token和缓存状态作为输入,调用模型前向传播并返回预测分布,通过静态图编译显著降低了自回归生成中的单步计算开销。
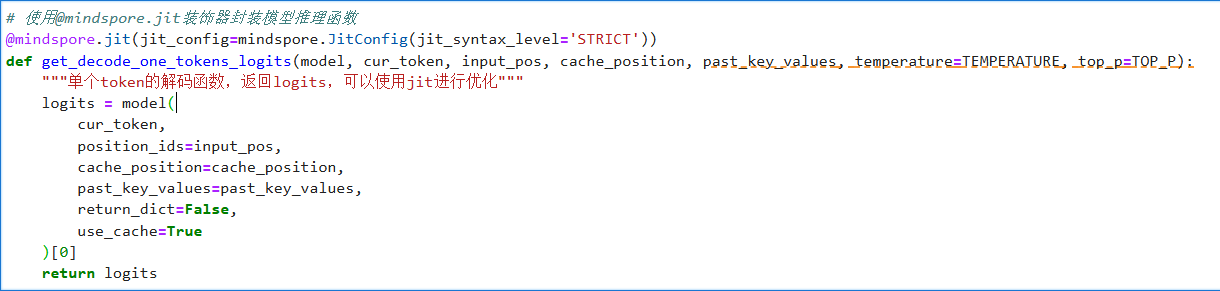
初始化静态缓存并生成首个token,随后进入循环调用优化后的单步解码函数逐个生成后续token,同时实时记录并打印每步耗时。整个过程结合了静态缓存管理和JIT编译优化,最终将生成的token序列解码为可读文本输出。
def decode_one_tokens(model, cur_token, input_pos, cache_position, past_key_values, temperature=TEMPERATURE, top_p=TOP_P):
"""单个token的解码函数,由logits、温度和Top_p选择合适的token"""
logits = get_decode_one_tokens_logits(model, cur_token, input_pos, cache_position, past_key_values, temperature, top_p)
if temperature > 0:
probs = mindspore.mint.softmax(logits[:, -1] / temperature, dim=-1)
new_token = sample_top_p(probs, top_p)
else:
new_token = mindspore.mint.argmax(logits[:, -1], dim=-1)[:, None]
return new_token
batch_size, seq_length = inputs["input_ids"].shape
# 创建静态缓存(用于加速自回归生成)
past_key_values = StaticCache(
config=model.config, max_batch_size=2, max_cache_len=512, dtype=model.dtype
)
cache_position = ops.arange(seq_length)
generated_ids = ops.zeros(
batch_size, seq_length + NUM_TOKENS_TO_GENERATE + 1, dtype=mindspore.int32
)
generated_ids[:, cache_position] = inputs["input_ids"].to(mindspore.int32)
# 初始前向传播获取首个logits
logits = model(
**inputs, cache_position=cache_position, past_key_values=past_key_values,return_dict=False, use_cache=True
)[0]
# 生成第一个新token
if TEMPERATURE > 0:
probs = mindspore.mint.softmax(logits[:, -1] / TEMPERATURE, dim=-1)
next_token = sample_top_p(probs, TOP_P)
else:
next_token = mindspore.mint.argmax(logits[:, -1], dim=-1)[:, None]
generated_ids[:, seq_length] = next_token[:, 0]
# 自回归生成循环
cache_position = mindspore.tensor([seq_length + 1])
for i in range(1, NUM_TOKENS_TO_GENERATE):
s = time.time()
next_token = decode_one_tokens(model, next_token, None, cache_position, past_key_values)
generated_ids[:, cache_position] = next_token.int()
cache_position += 1
t = time.time()
# 打印单步生成耗时
print("[%d]:" % i, t - s)
text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(text)
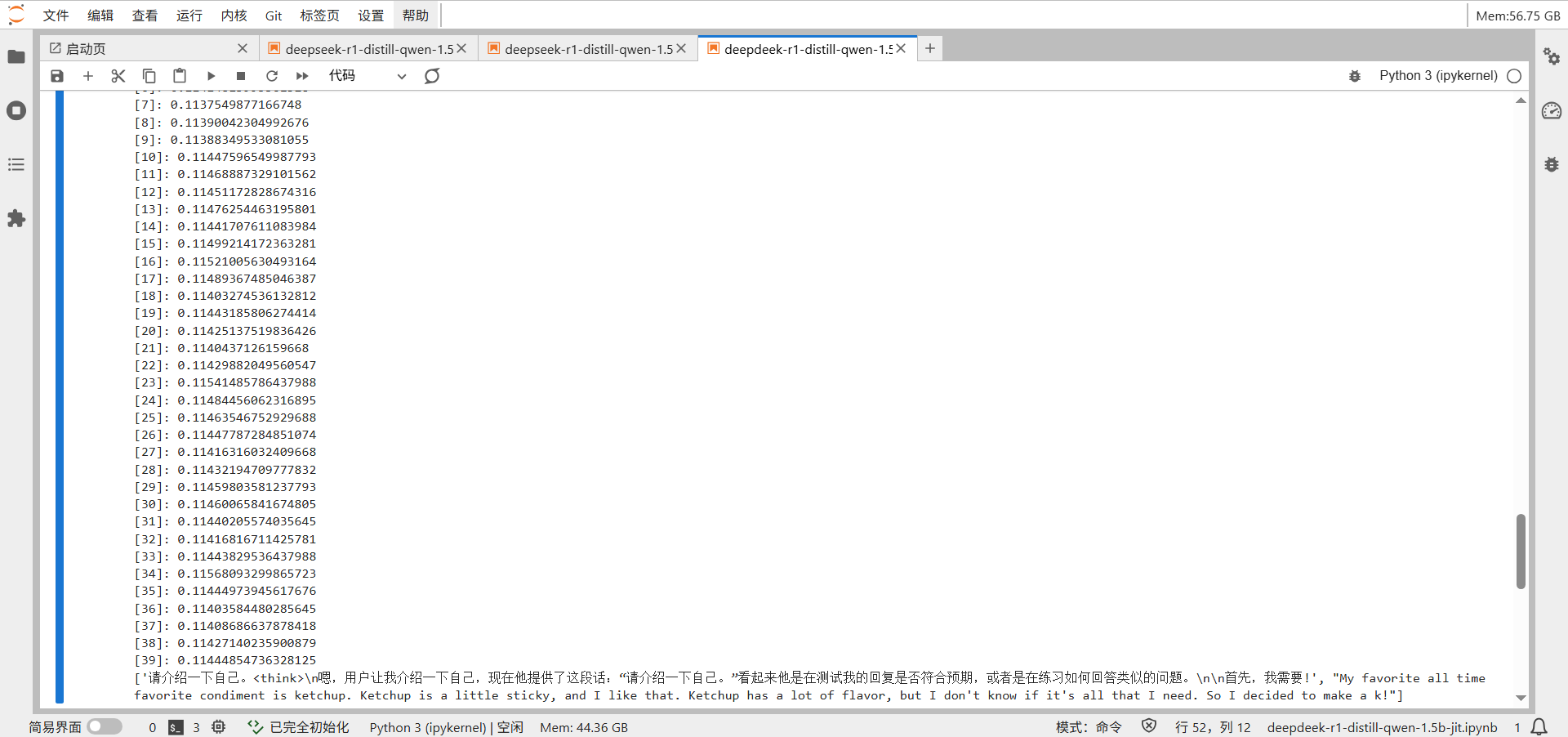
实验可以看出, JIT优化方案实现了显著的性能突破