昇思学习营第七期·昇腾开发板 学习打卡_第二次
LoRA模型的微调:
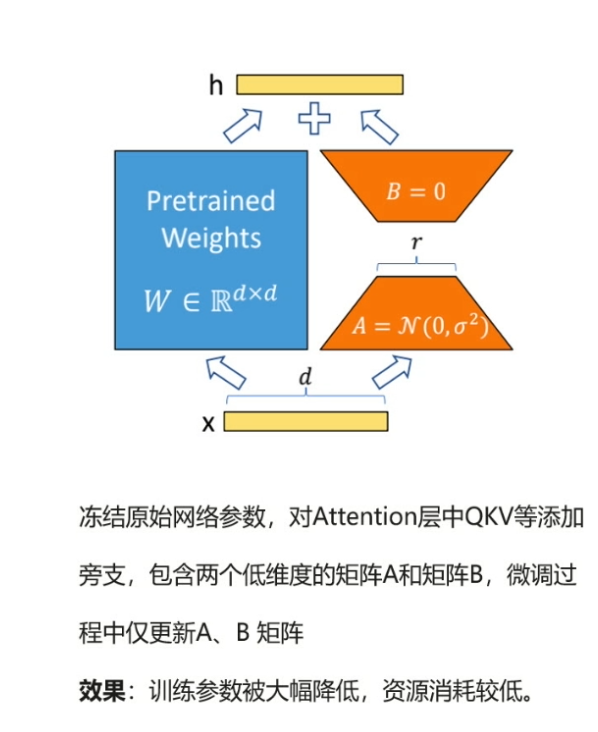
粗看一遍感觉到:原来适配大模型不一定要"伤筋动骨"全盘调整,加个轻量补丁就能高效解决问题,省时省力且满足需求
代码示例
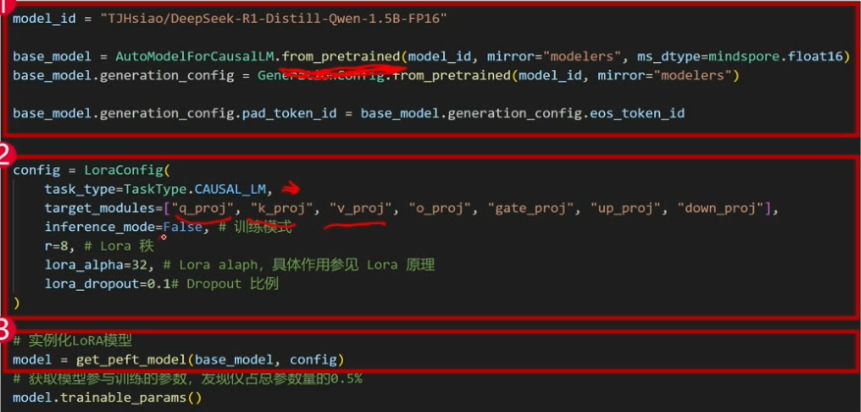
方框一:
- 从云端下载一个现成的 1.5B 参数大模型(类似 ChatGPT 的“大脑”)。
- 设置模型用 半精度(FP16) 运行,节省显存。
- 配置生成文本时的参数,比如用
eos_token(结束符)作为填充符。
方框二:
- 告诉 LoRA 要改哪些部分(这里是注意力机制相关的 7 个关键模块)。
- 设定微调强度:
r=8:用 8 维的小矩阵做调整(原模型可能是 4096 维的)。alpha=32:调整幅度是基础值的 32 倍。
dropout=0.1:训练时随机忽略 10% 的数据,避免死记硬背。
好比:给电脑外接一个 轻量级显卡(LoRA),只升级玩游戏需要的部分,而不是换整个主板。
方框三:
- 把 LoRA 模块和原模型组合,新模型既能用原能力,又能学新任务。
- 结果显示 只有 0.5% 的参数需要训练(1.5B 参数中约 750 万可调)。
好比:电脑接上外接显卡后,系统自动识别,现在你只需要更新显卡驱动(LoRA参数),不用重装整个系统。
接下来,老师以甄嬛传为例子,讲了一个训练学甄嬛说话的模型。
教了我们如何定义步长,数据集的加载方法,tokenizer的实例化,然后还讲解了代码的逻辑处理。
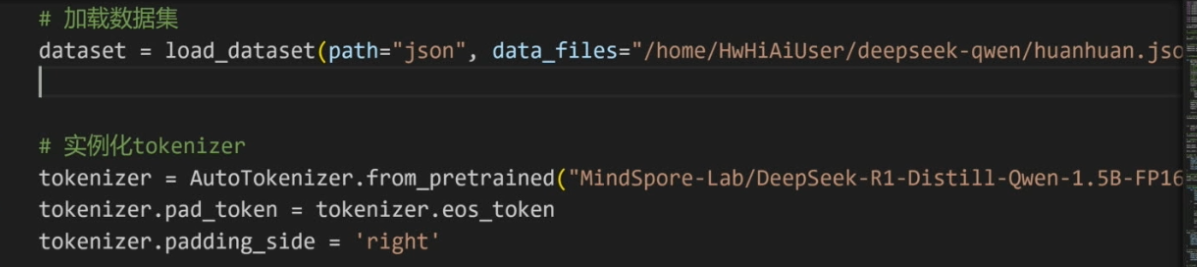
针对性的讲解了map函数的使用
最后进入实操环节!
首先先删除原来的第一个和第三个方框
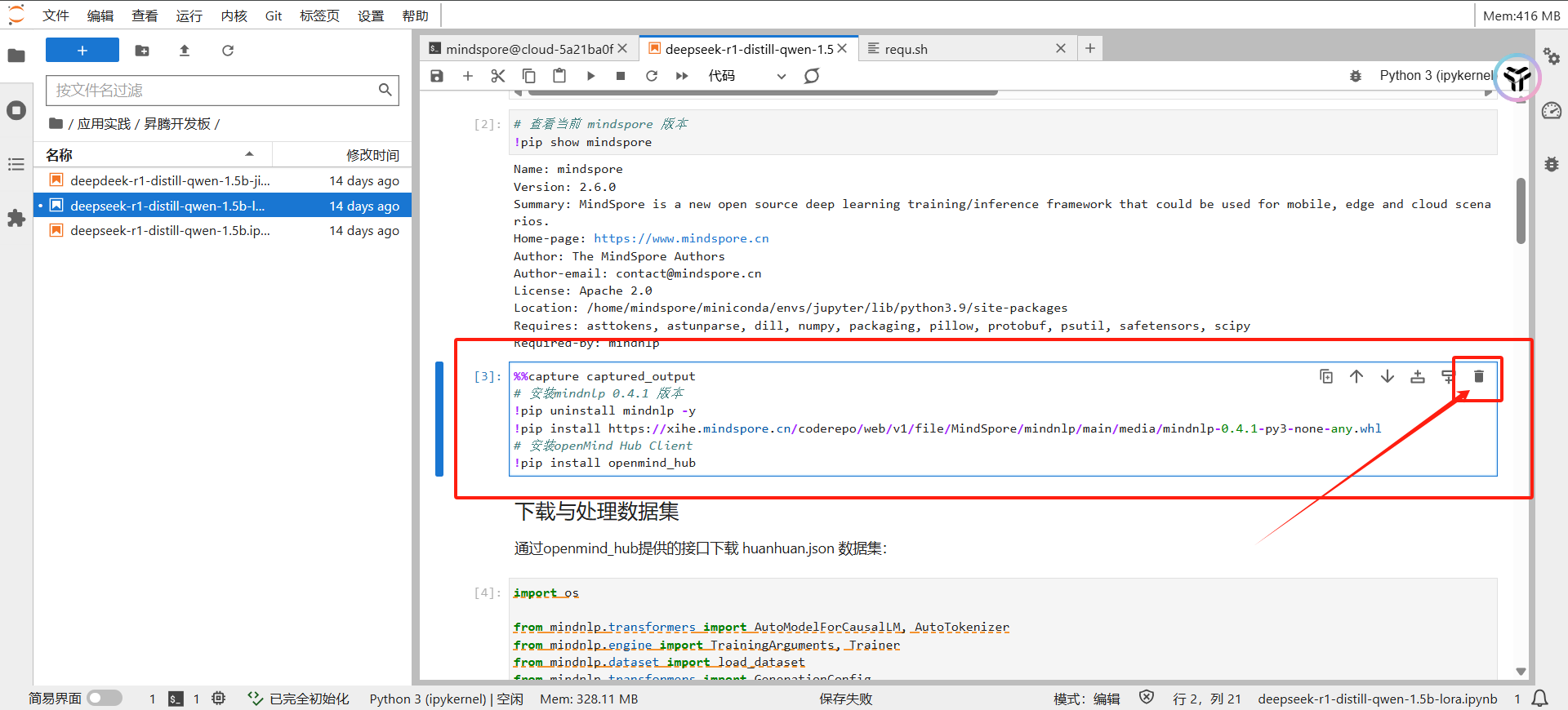
然后修改第二个方框内容为
print(“# ------------------------ mindspore ---------------------------- #”) !pip show mindspore print(“# ------------------------ mindnlp ---------------------------- #”) !pip show mindnlp
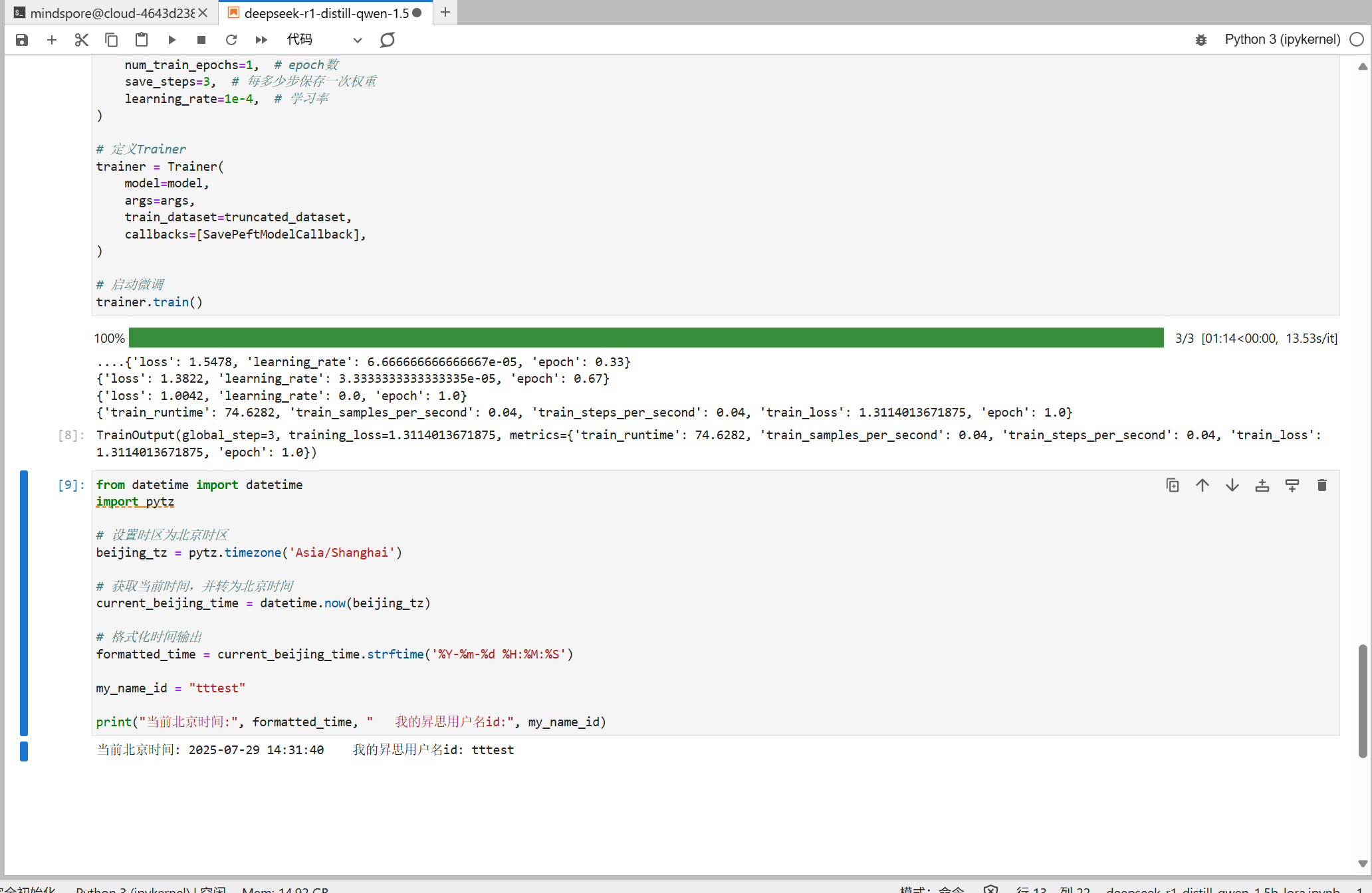
接着在第九个方框下面加一个单元格,输入以下代码
from datetime import datetime import pytz
设置时区为北京时区
beijing_tz = pytz.timezone(‘Asia/Shanghai’)
获取当前时间,并转为北京时间
current_beijing_time = datetime.now(beijing_tz)
格式化时间输出
formatted_time = current_beijing_time.strftime(‘%Y-%m-%d %H:%M:%S’)
my_name_id = “tttest”
print(“当前北京时间:”, formatted_time, " 我的昇思用户名id:", my_name_id)
最后得到如图结果
实操结束,感谢组长带着我们走一遍实操流程