一、模型LoRA微调:
1、LoRA微调介绍
微调已经是模型落地的至关重要的手段。但面对成百上千的参数模型,全量微调意味着高成本与高资源消耗。LoRA也就成为一种高效、轻量、即插即用的微调利器。
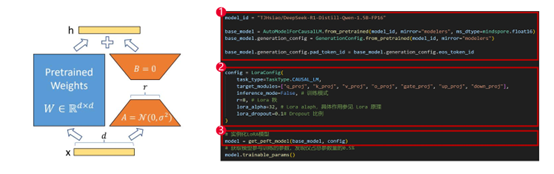
LoRA 提出了一个创新的思路:只训练两个小矩阵 A 和 B,并将它们嵌入原有的线性层中。最大优势就是不动大模型的原始参数,而是通过“添加低秩扰动”进行模型适配来改变行为,即插即用、任务解耦、部署灵活。
2、LoRA 高效的原因:
① LoRA 只需训练少量参数(A 和 B)。例如:70B 模型约 7000M 参数,LoRA仅需训练约 70M 参数。就很好的减轻了训练负担。
② 内存十分友好。只训练 A、B 小矩阵,前向传播时计算量就大幅减少;反向传播时仅对小矩阵求梯度。
③ 即插即用:原始模型保持不变;多个 LoRA 模块可根据不同任务动态加载;便于模型管理、部署与复用。
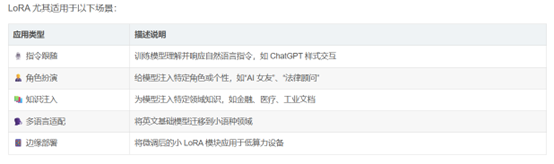
3、LoRA 适用的场景
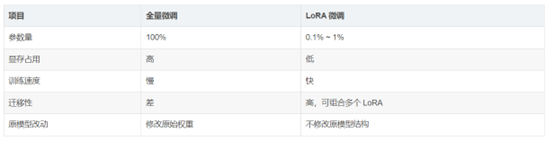
4、LoRA 和全参数微调对比
二、实操部分:
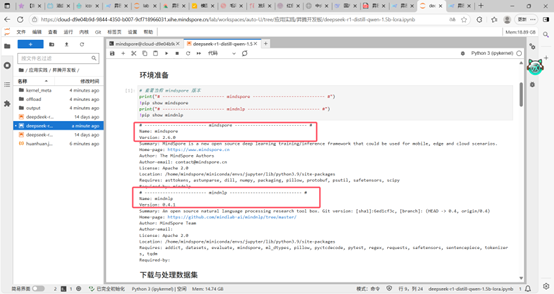
环境准备完毕,版本成功安装。
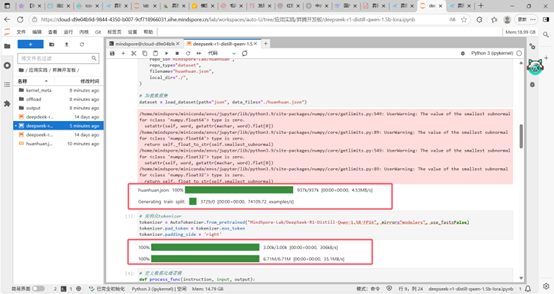
数据集加载成功,完成实例化。
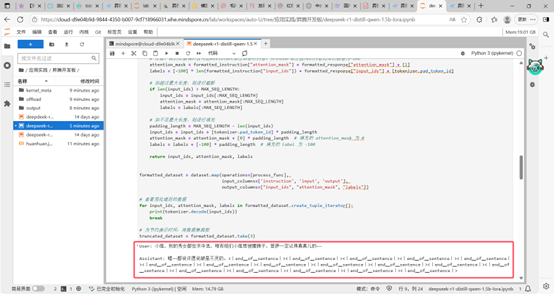
数据成功处理。
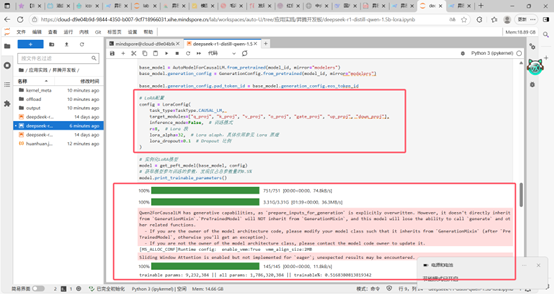
参数成功配置。
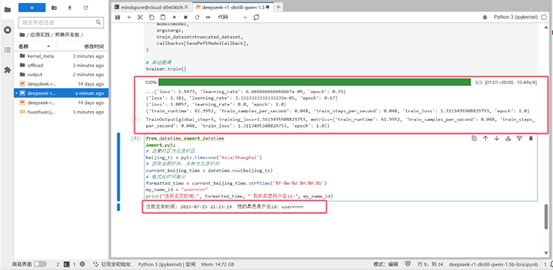
训练参数和微调完成。