昇思学习营第七期·昇腾开发板特辑 第二次打卡
DeepSeek-R1-Distill-Qwen-1.5B模型LoRA微调
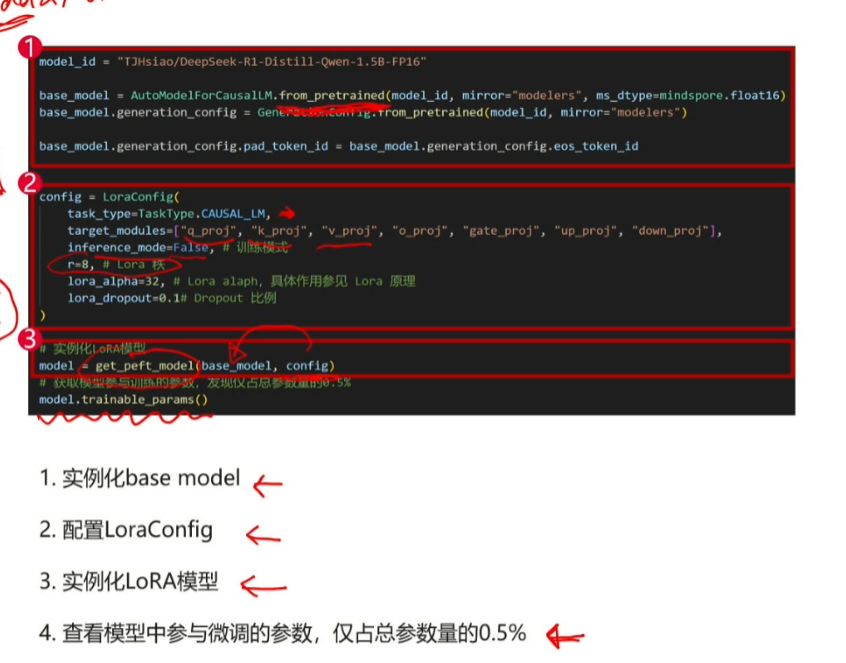
在我们微调大模型的开发任务重,实际的微调方式分为许多种,例如全参微调lora微调以及qlora微调,对于我们个人用户开发者来说全参微调对于我们硬件资源成本以及时间的消耗是巨大的,所以我们在一般的任务中都不会采取全参微调,而是采用比较常见的lora微调,lora微调如下图所示,就是将较大部分的参数以及权重保持原模型不变,我们只动较小的一部分参数以及权重,然后再将这两者融合,从而将影响用一个较小的资源来参与到最后的模型中,其中较大部分对应图中的蓝色部分,我们一般称之为base model,较小部分对应橙色部分,我们一般称之为lora adaptor

我们在代码中一般分为如下步骤来实现我们的lora微调
我们在实际的微调任务中一般采用以下的步骤
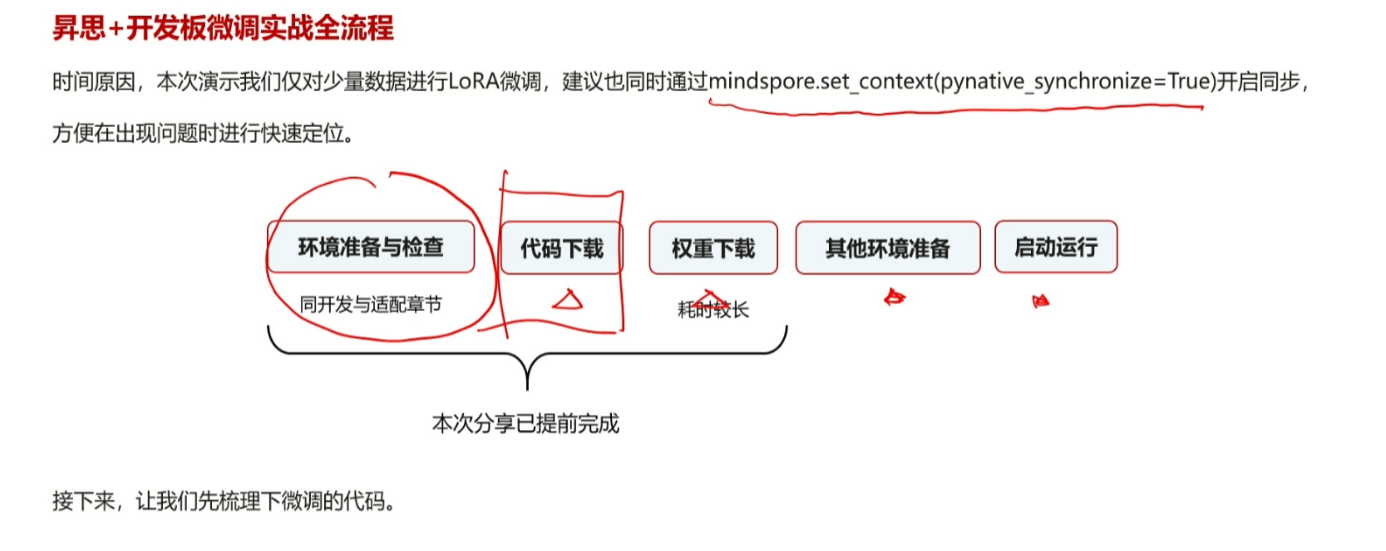
首先我们一定要安装好环境,而且注意我们的框架一定要与环境版本匹配,不然会出现意想不到的报错很麻烦。
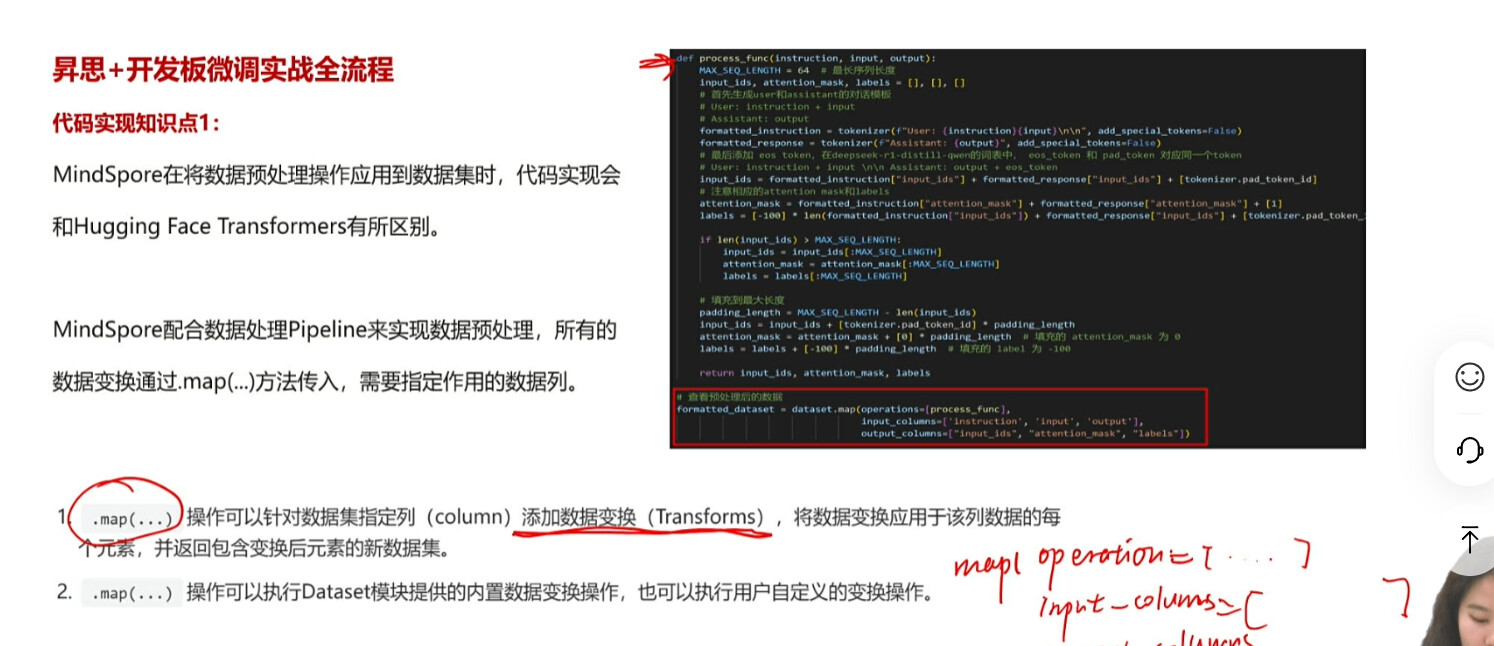
注意我们在实际的微调任务中,我们的数据集一定要和对应的框架中的函数类型匹配
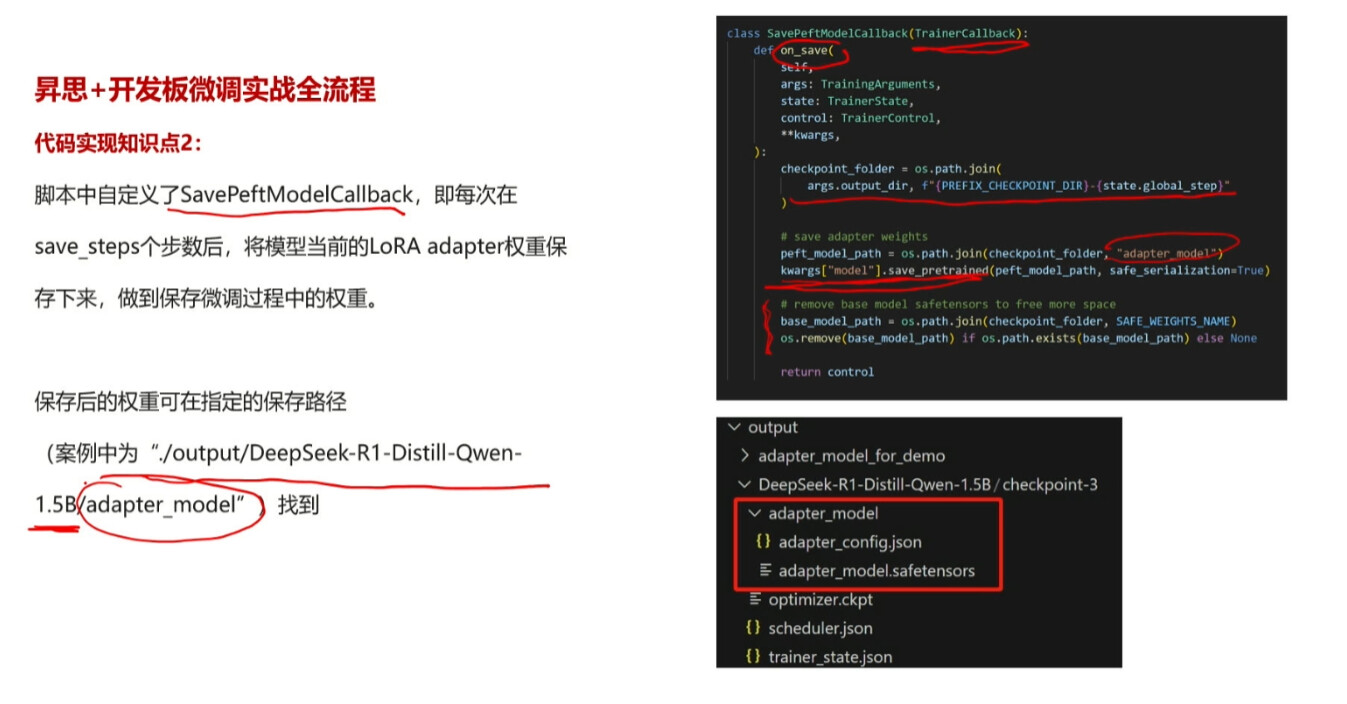
我们可以通过调参来设置保存模型的步数和路径
在微调模型的任务中,如果模型的参数量比较大,我们的资源可能就会出现问题,在这种情况下就需要我们来进行优化,对于显存问题,我们一般想到的都是先加载fp32权重再转换成fp16,但是其实我们可以采用直接加载fp16的方式
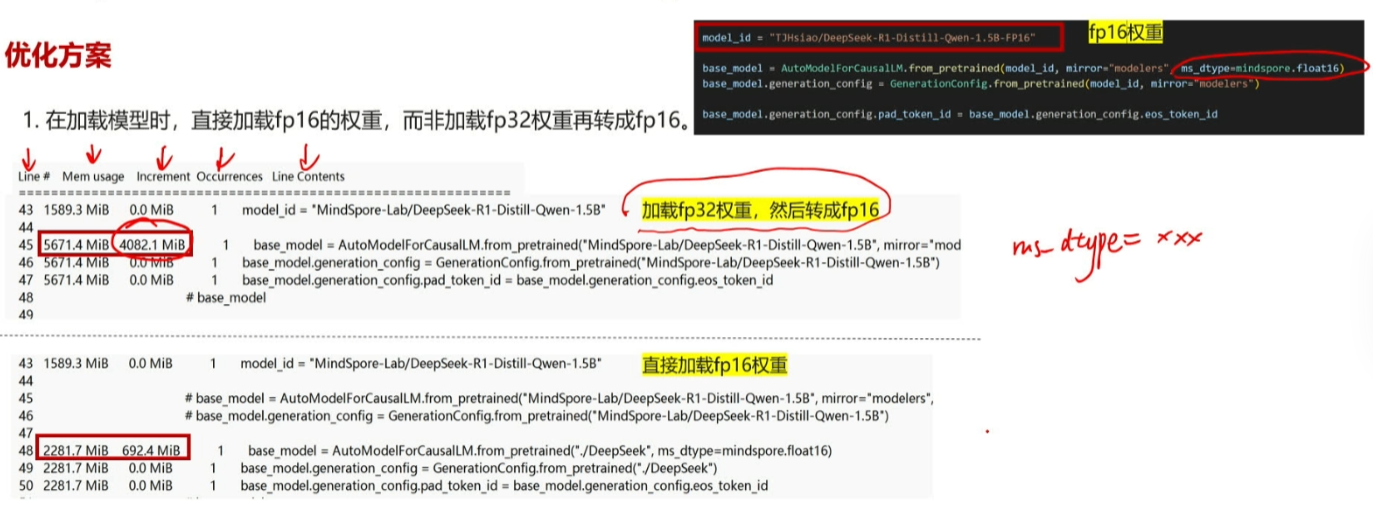
如图所示我们可以看到,相比于第一种方法,我们的第二种方法将资源消耗降低到了百分之五十以上
在训练中我们还可以通过
export MAX_COMPILE_CORE_NUMBER=1
export TE_PARALLEL_COMPILER=1
来控制我们的进程和端口数,以免我们的显存崩掉,当然,我们的端口和进程也不一定要设置为1,具体可以根据自己的硬件资源来进行调整,我们的目的只是不然卡崩掉,在我们的微调任务中一定不可过于古板。

当然我们还可以手动限制最大内存

下面我们通过平台来实操一下
首先我们在终端创建一个脚本,至于脚本的内容在此我就不透露了(每个人都有自己的小秘密)
touch requer.sh
我发现我们的平台不可以手动保存和修改文件,所以我们只能采用vim的方式
vim requer.sh
然后我们运行脚本
bash requer.sh
然后我们找到此页面
我们加上象征我们身份的代码块
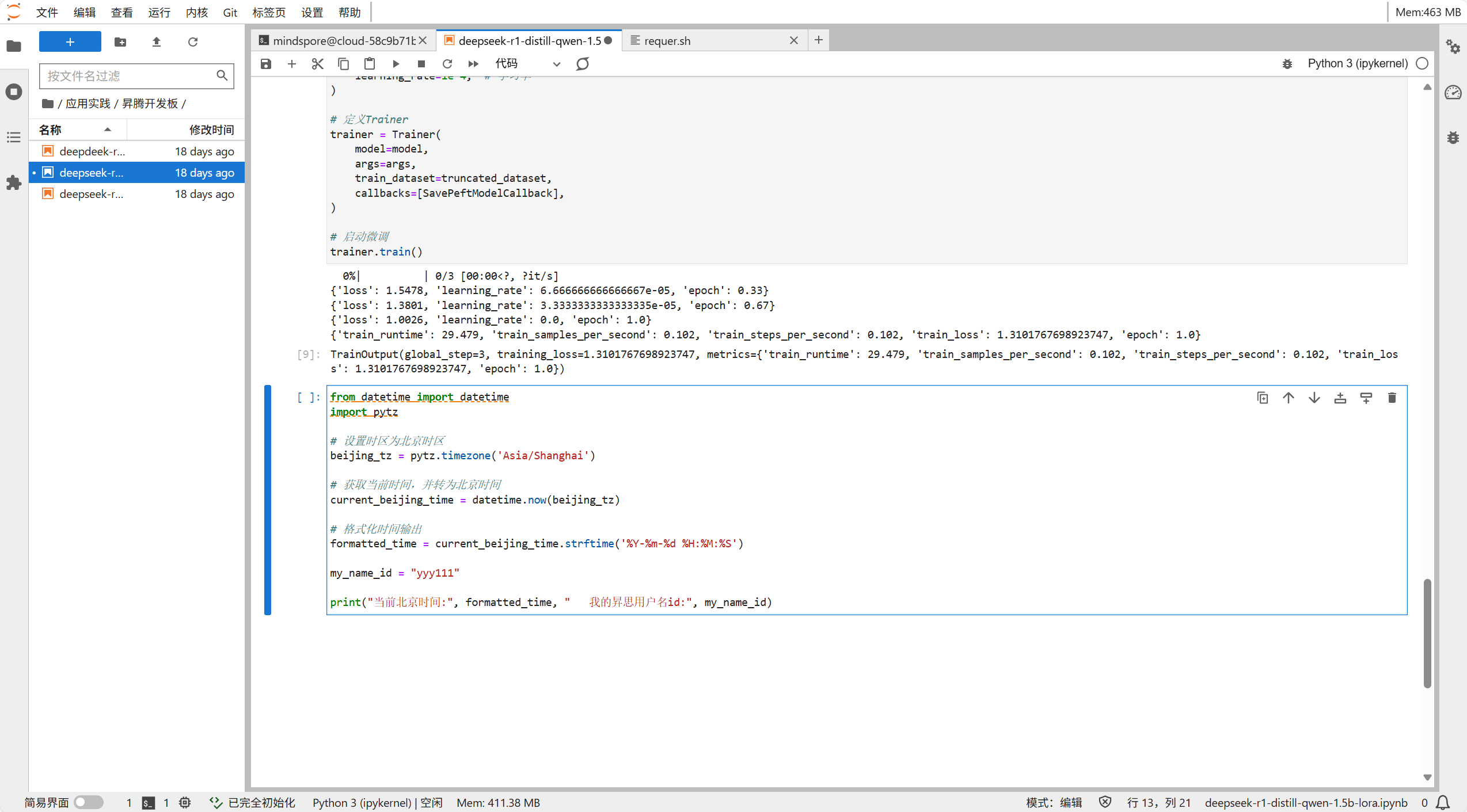
然后修改训练参数以便达到更好的训练效果
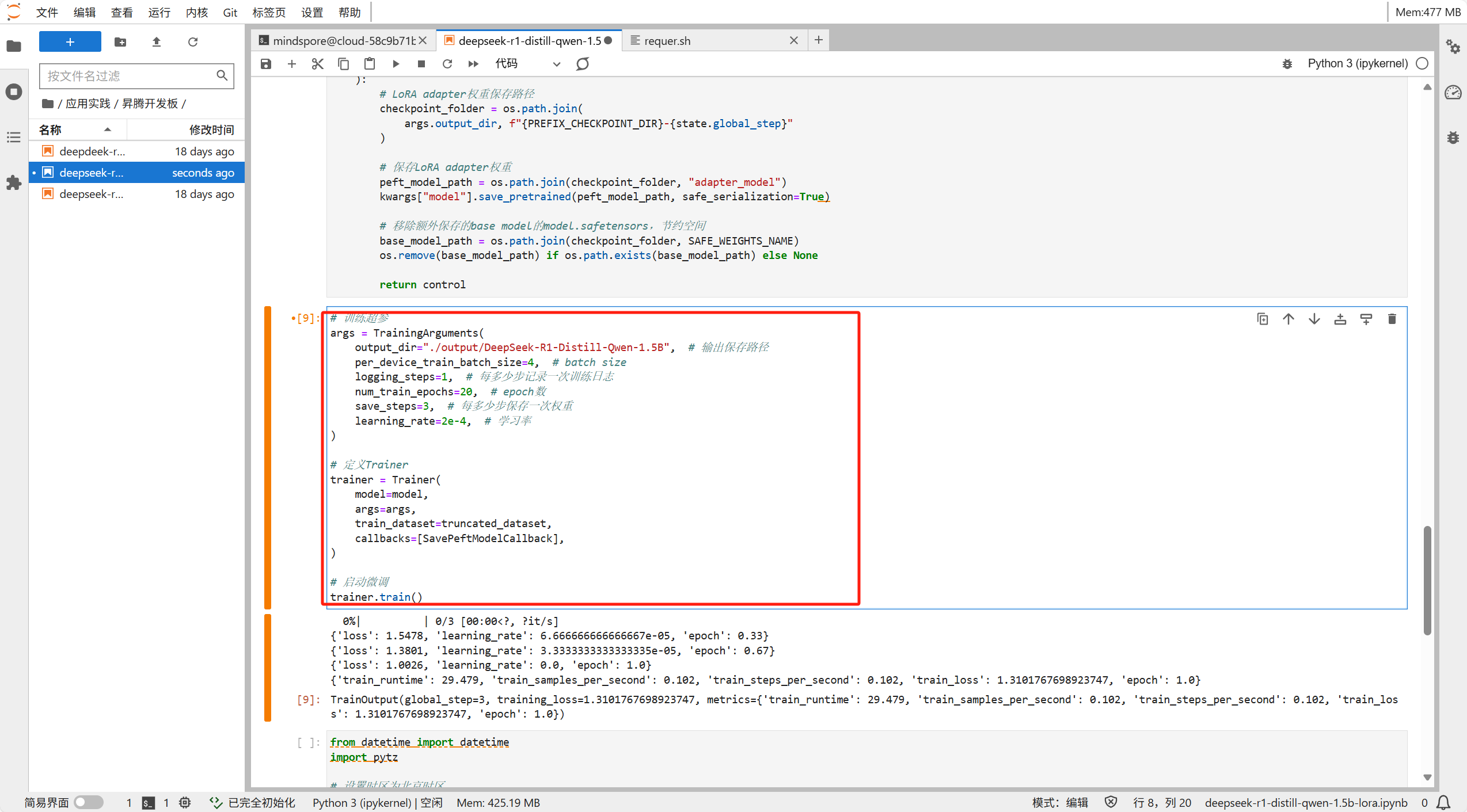
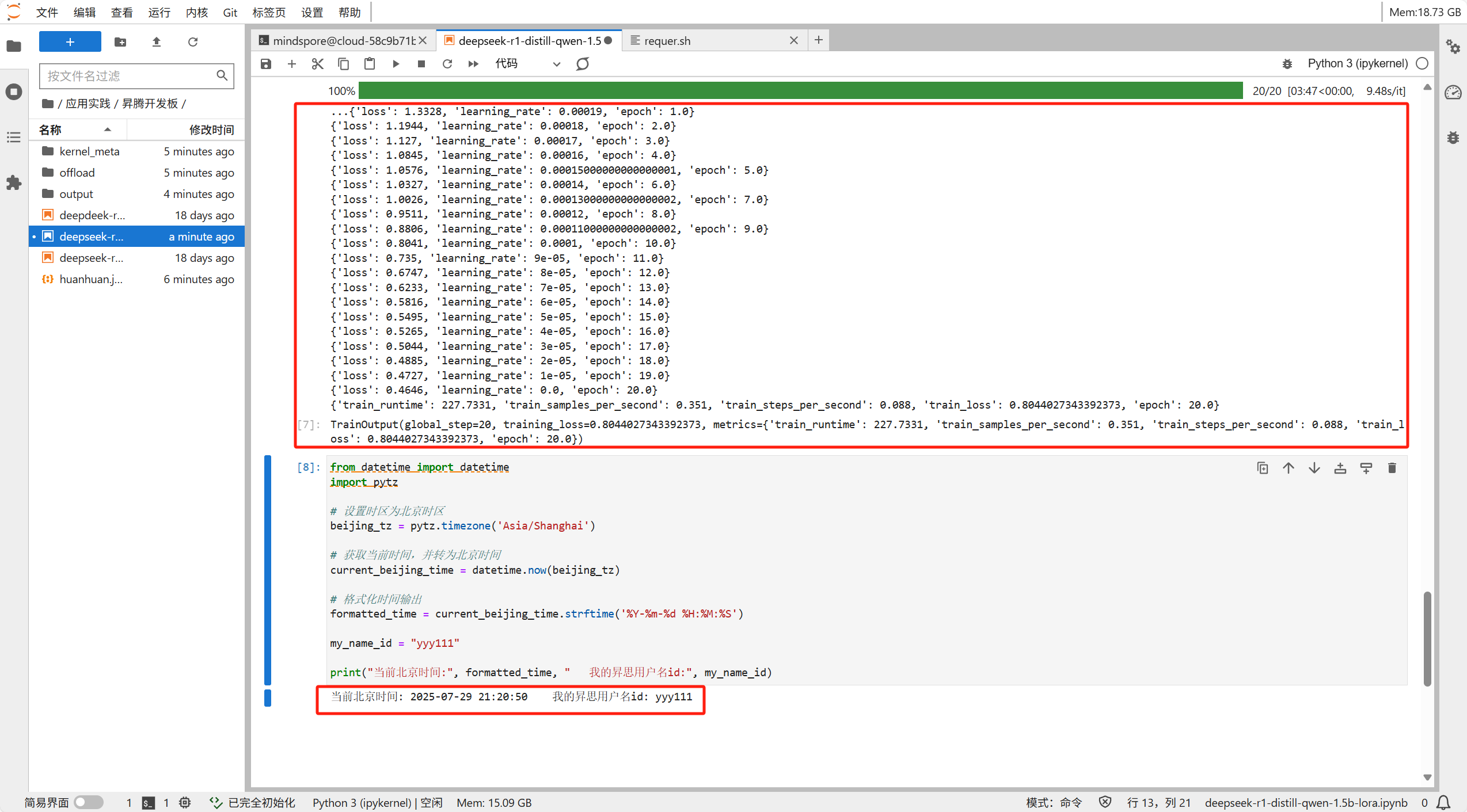
然后我们启动训练,可以看到我们的参数调整的还是十分合理的,loss有明显的下降且十分稳定