昇思学习营第七期·昇腾开发板 学习打卡 第二次(LoRA微调)
DeepSeek-R1-Distill-Qwen-1.5B模型LoRA微调
微调分为全参微调和高效参数微调,全参微调比较吃硬件资源,大多数采用高效参数微调,最常见为LoRA微调
LoRA微调介绍

蓝色部分的参数是不动的,只做橙色部分
最终的结果为蓝色部分的推理结果和橙色部分的推理结果相加,通过此种方式将额外添加的低秩矩阵参与到我们结果的最终影响中,省去了蓝色部分的训练参数以及资源消耗
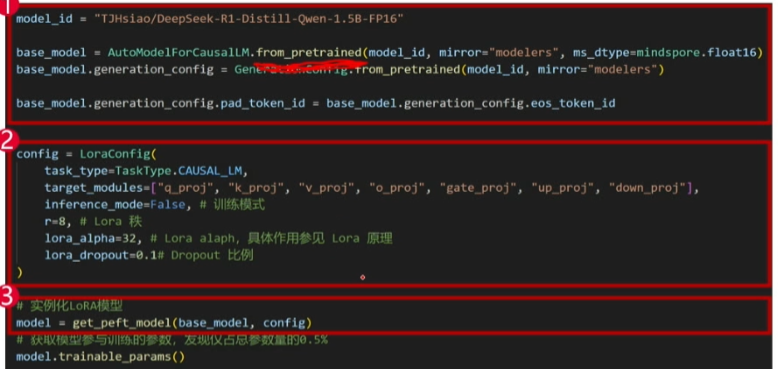
from_pretrained是实例化base model也就是我们第一张图中的蓝色部分(我之前理解的就是预训练模型)
至于这张图片中的第二部分代码就是配置LoraConfig其作用就是将LoRA adapter参与到最终的影响结果,即为第一张图片中的橙色部分
第三部分代码get_peft_model就是融合
昇思+开发板微调实战全流程
以甄嬛传的数据集在开发板上训练出一个可以模仿甄嬛说话的“嬛嬛”,之前微调过一个西游记的孙悟空,这个与之类似感觉,不过比我那个感觉更有意思。
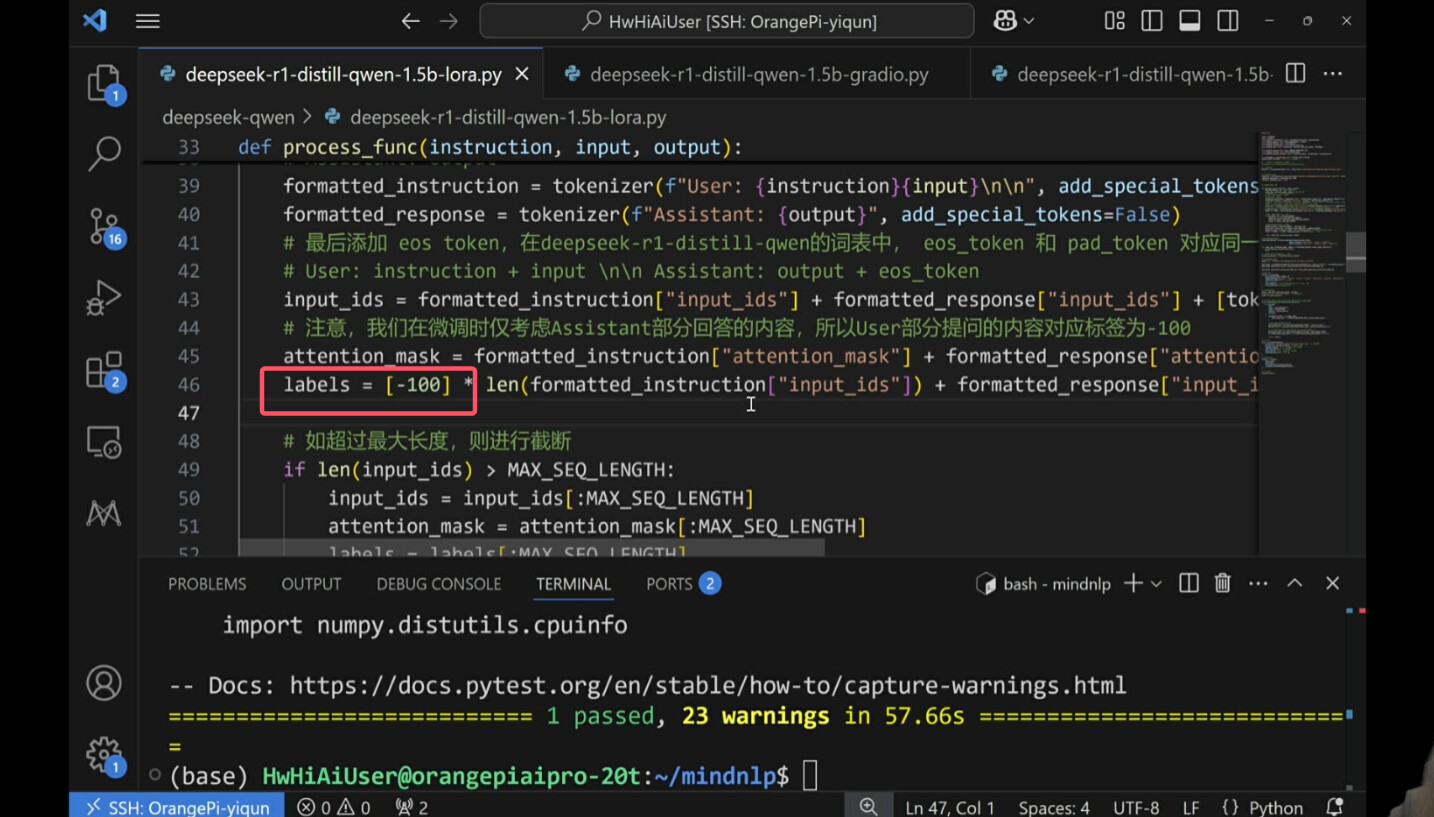
将提问部分的标签设置为-100告诉模型提问问题可以不做处理,因为我们想要的主要效果只是让它回答我们的问题
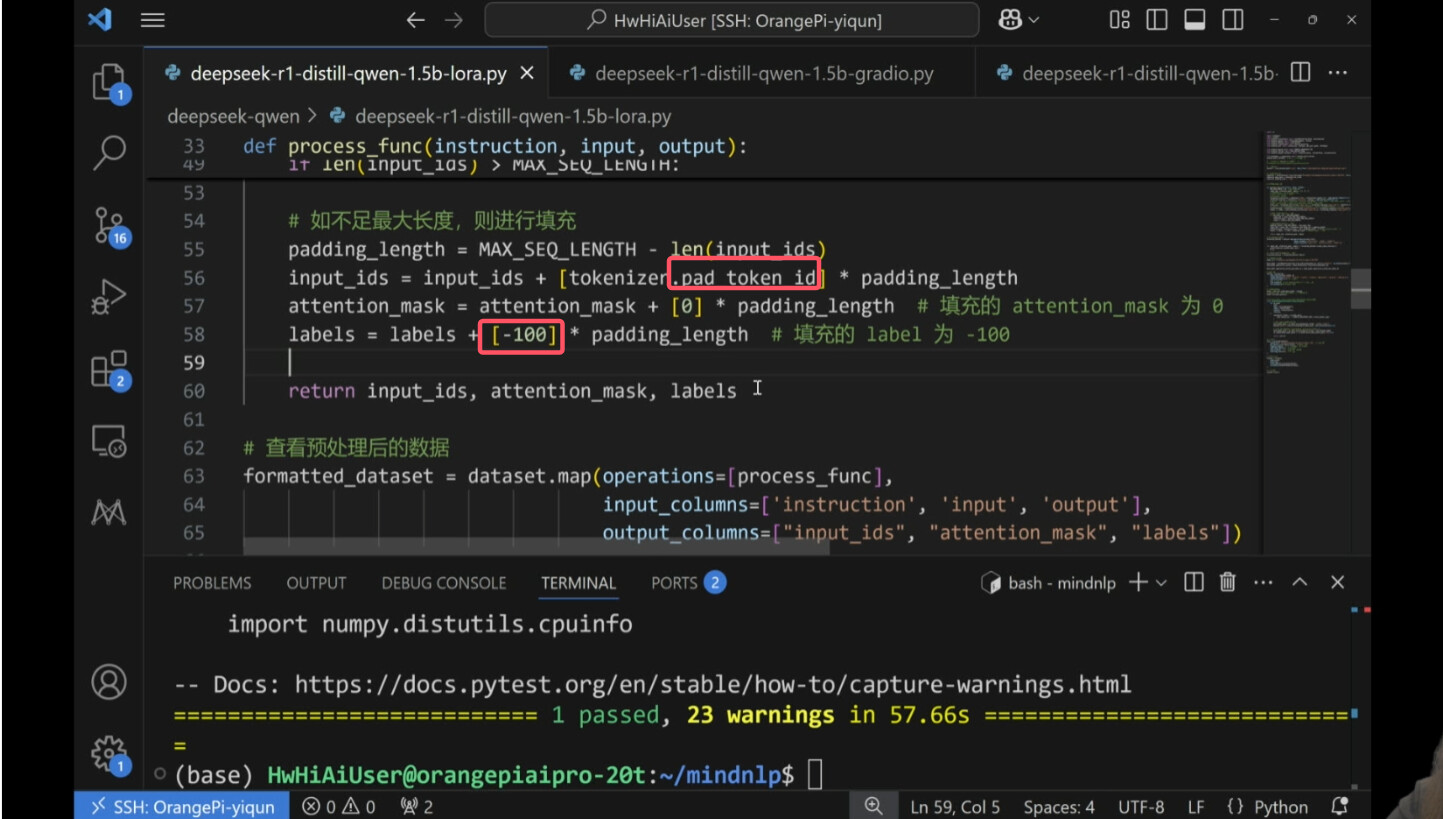
pad_token_id表示占位,如果词数不够则用此填充,标签为-100表示填充词无实际意义,不用理会,返回的数据为,内容,掩码以及标签
batch size表示每次取多少条数据 epoch表示训练次数是多少
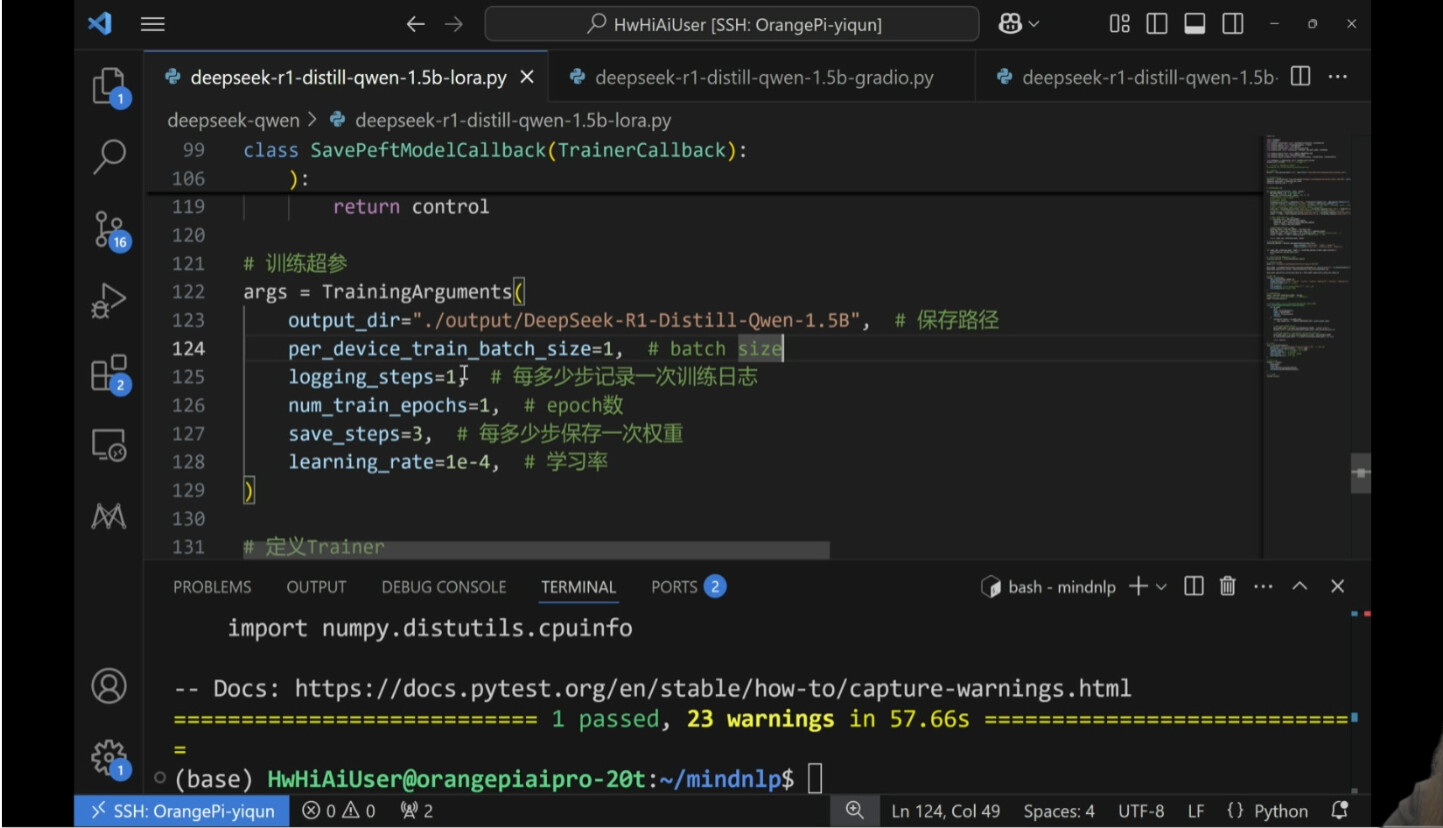
第二课前面一些保存路径什么的之前的微调中便有一些涉及,在此处就不再赘述了
从此处开始再来记录

可以看到相比于先加载fp32再转换成fp16,我们直接加载fp16权重省去了极大部分的显存资源

我对此的理解就是我们算法中的省去并行空间,但是此方法也会有限制,我们一般在微调完模型之后还会涉及到模型的转换和融合,将进程控制在1,我们就不能保留中间的权重去转换融合,就是边训练边融合,所以需要根据自己的实际训练情况来定义。
代码实操
在实践界面微微的启动了一下训练,完成了实践任务,结果保存在这里
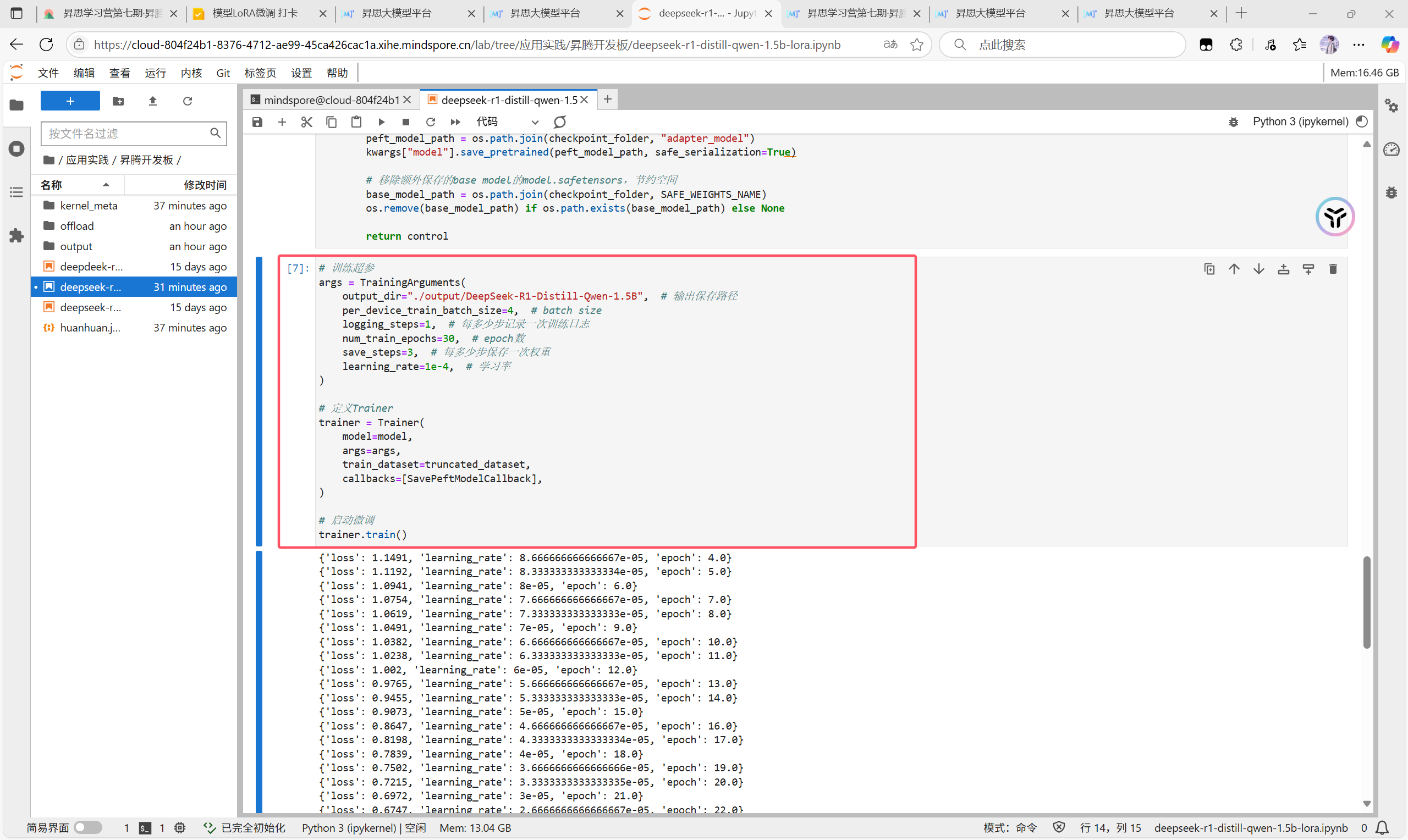
参数设置如图所示,我的个人习惯是将batch size设置为4
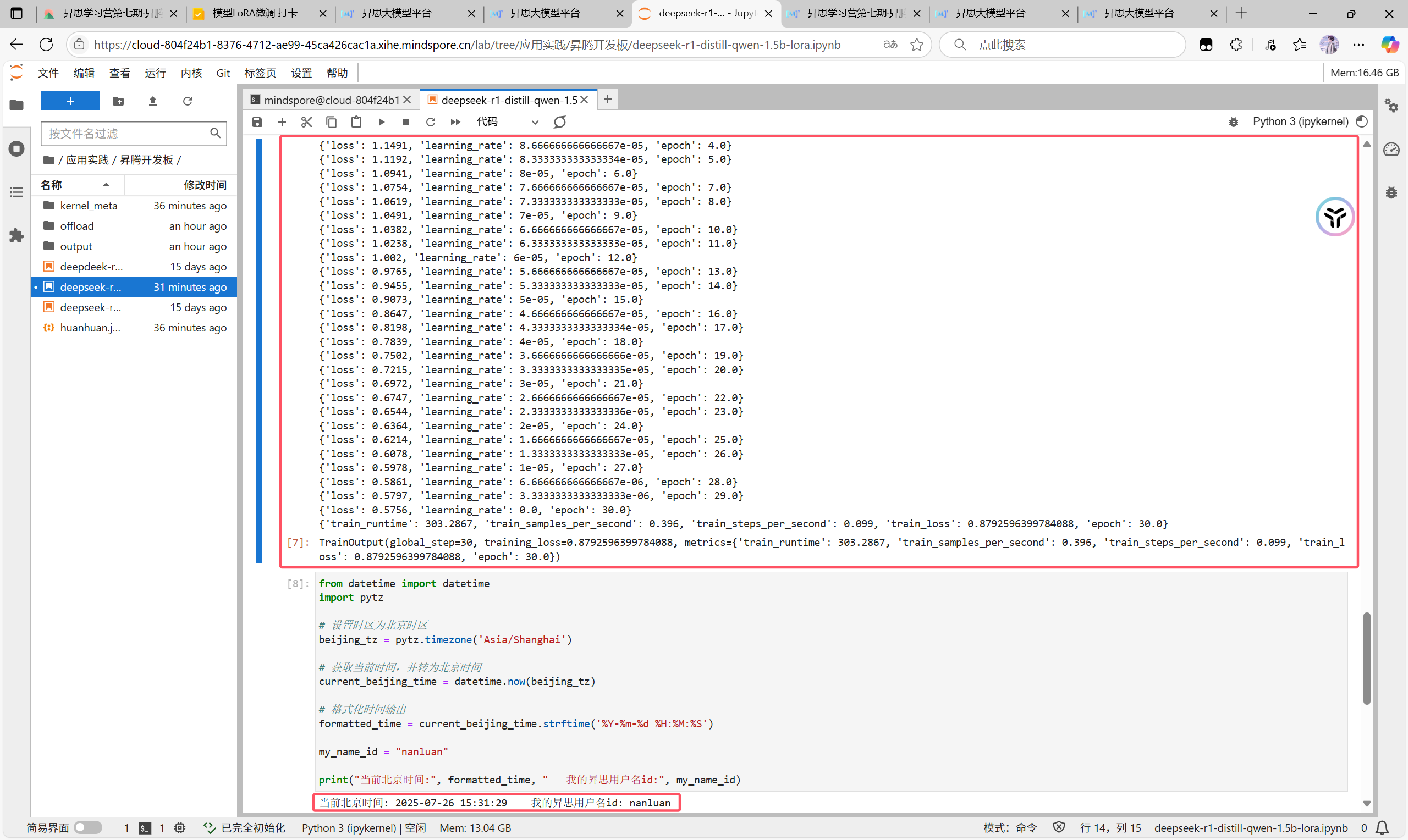
可以看到loss有明显的下降