昇思+昇腾开发板:软硬结合玩转DeepSeek开发实战(学习打卡第二天)
1.模型微调
模型微调(Fine-tuning)是一种基于预训练模型进行模型优化的技术,在不修改预训练模型原始参数的前提下,通过训练少量新增参数(冻结原始参数)来适配特定任务,既能保留预训练模型的强大能力,又能大幅降低微调的计算成本和存储需求。
模型微调分主要分为全参微调和高效参数微调,全参微调是对预训练模型所有参数进行调整,计算成本高,比较吃硬件资源;高效参数微调是对部分参数进行调整,我们平常都使用高效参数调整,最常见为LoRA微调
2.LoRA微调

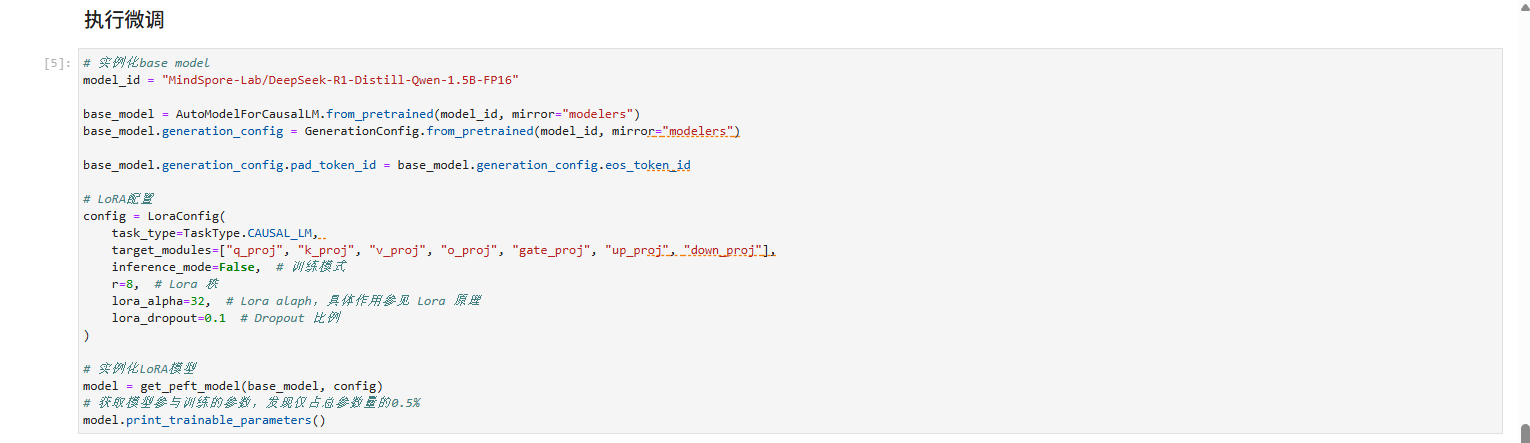
蓝色部分,我们也称其为base model(原模型—不进行调整),去进行一个实例化,加载权重,进行一个小小的调整和修改(称为LoRA adaptor)
上述过程通过LoRAConfig来实现,最后实例化LoRA模型。
LoRA微调实战
a.前期准备
环境准备与检查:与开发与适配(第一天学习)一样
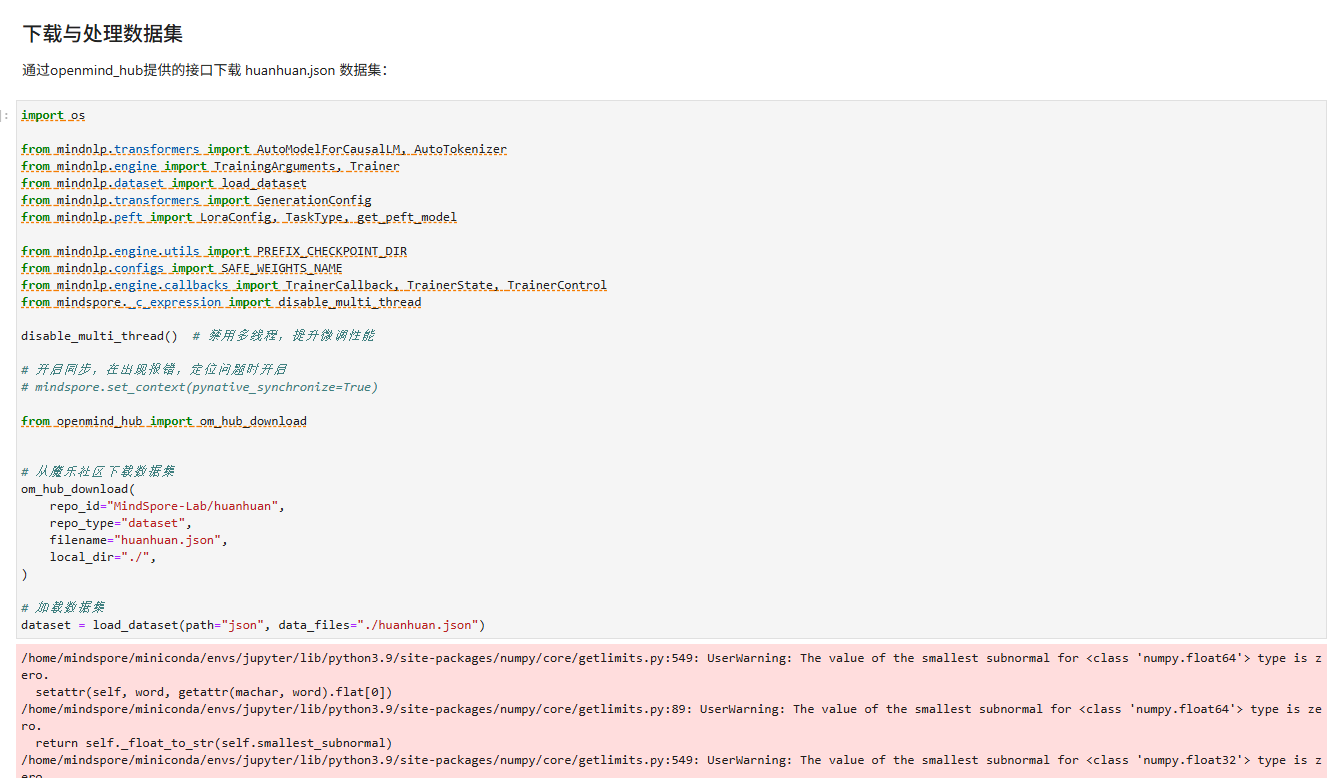
代码下载和权重下载
b.具体代码
大致模块:
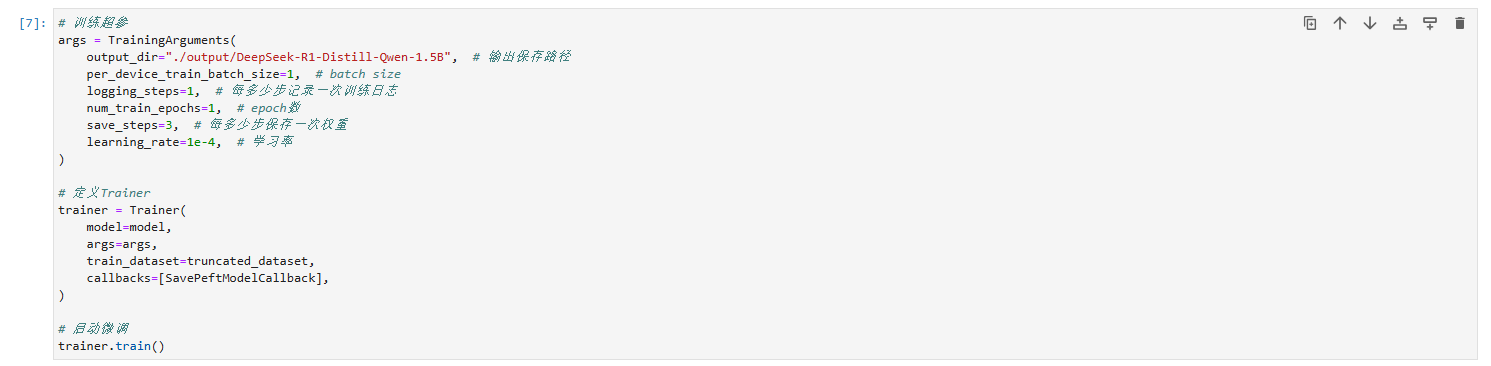
数据集的处理→base model的实例化→LoRA模型实例化→定义Trainter→启动微调
Callback函数:
通过Callback函数,随save_steps定义的部署保存LoRA adapter权重(需要手动进行函数名调整。
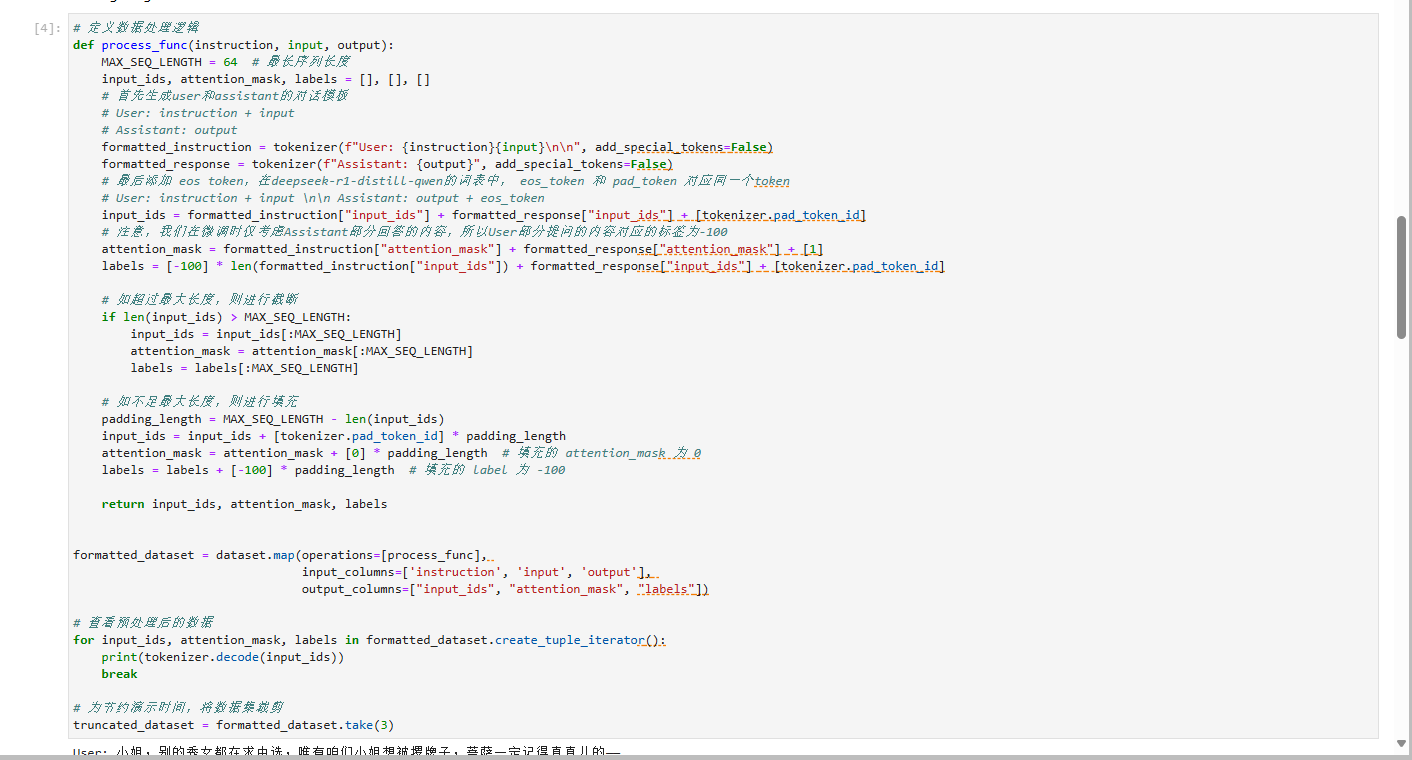
数据集处理:
原始数据集时甄嬛传中,娘娘的说话语句(让模型学会娘娘说话语气)
实例化tokenzizer:
进行分词:将文本信息拆分成一个个token(词,表),token可以根据相关的索引装换成数据的模型
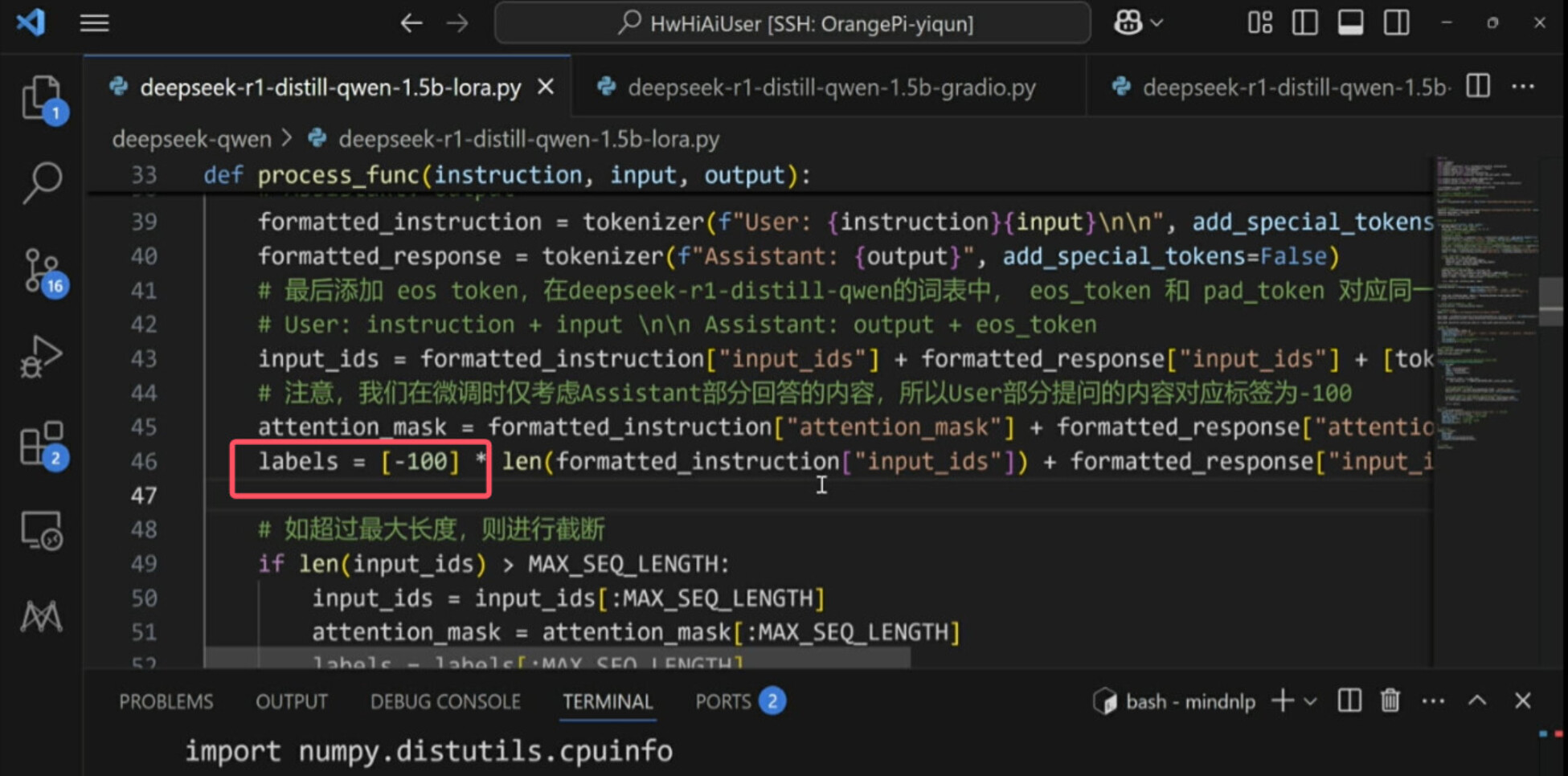
eso token(终止符):用于避免一句话重复说的问题。
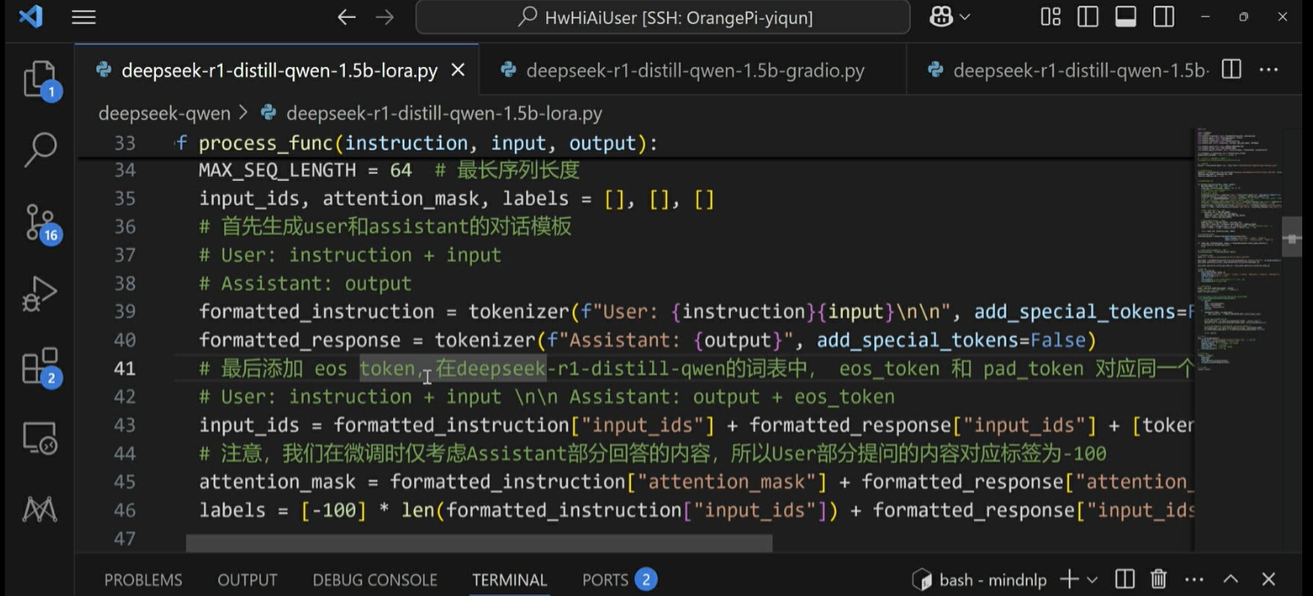
[-100]:表示模型提问问题可以不做处理,这样模型可以跳过处理我们的提问问题,只处理回答问题部分。
3.MindSore数据处理的特点
MindSpore所有的数据转换都通过.map(…)方法传入;
map(operation = […]——数据操作有哪些,
input_colums = […]——数据指定序列
output_colums = […]——与return一一对应)

4.优化方案
a.在加载模型时,直接加载fp16的权重,而非加载fp32权重再转换成fp16

观察上述图片,可以发现这种优化方式可以大大优化内存占用,节约资源,减少参数量
b.限制拉起python进程数,减少显存的影响。
export MAX_COMPILE_CORE_NUMBER=1
export TE_PARALLEL_COMPILER=1
设置两个环境变量,可以把python进程控制在4-6个

c.手动限制进程最大内存占用
手动限制进程最大内存占用,开了swap然后再限制内存就可以空出来给NPU用

5.实操训练
环境准备
通过run_check(),检查mindspore是否成功安装
# 检查 mindspore 是否正确安装并运行测试
python -c "import mindspore; mindspore.set_context(device_target='Ascend');mindspore.run_check()"
通过git来下载安装mindnlp环境
# 克隆仓库
git clone https://openi.pcl.ac.cn/MindSpore/mindnlp.git
# 进入仓库目录
cd mindnlp || { echo "进入 mindnlp 目录失败"; exit 1; }
# 查看所有分支
git branch -a
# 切换到 0.4 分支
git checkout 0.4
pip show mindnlp
数据处理
这里的代码无需修改,已经将数据处理部分完成