模型LoRA微调:
LORA 简介
“低秩适应”(LoRA)是一种“参数高效微调”(PEFT)的形式,它允许使用少量可学习参数对大型模型进行微调 。LoRA改善微调的几个点:
1.将微调视为学习参数的变化(▲w),而不是调整参数本身(w)。
2.通过删除重复信息,将这些变化压缩成较小的表示。
3.通过简单地将它们添加到预训练参数中来“加载”新的变化。
LoRA微调的流程
首先冻结模型参数 。使用这些参数进行推理,但不会更新它们。然后创建两个矩阵 ,当它们相乘时,它们的大小将与我们正在微调的模型的权重矩阵的大小相同。在一个大型模型中,有多个权重矩阵,为每个权重矩阵创建一个这样的配对。
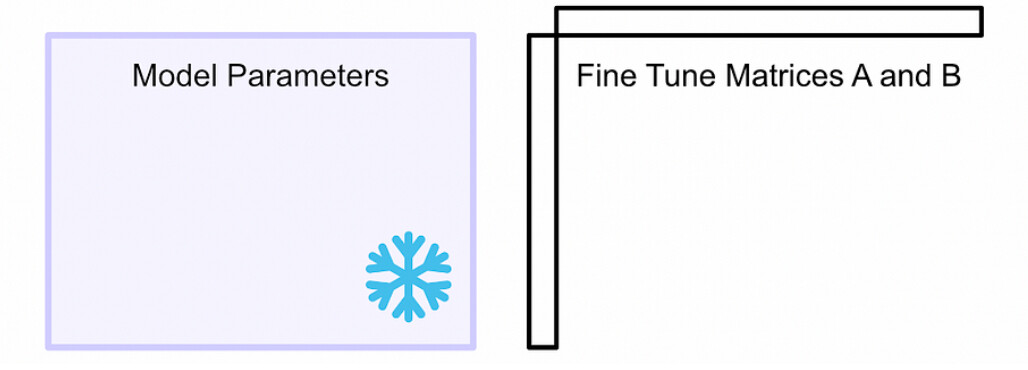
LoRA将这些矩阵称为矩阵“A”和“B”。这些矩阵一起代表了LoRA微调过程中的可学习参数。
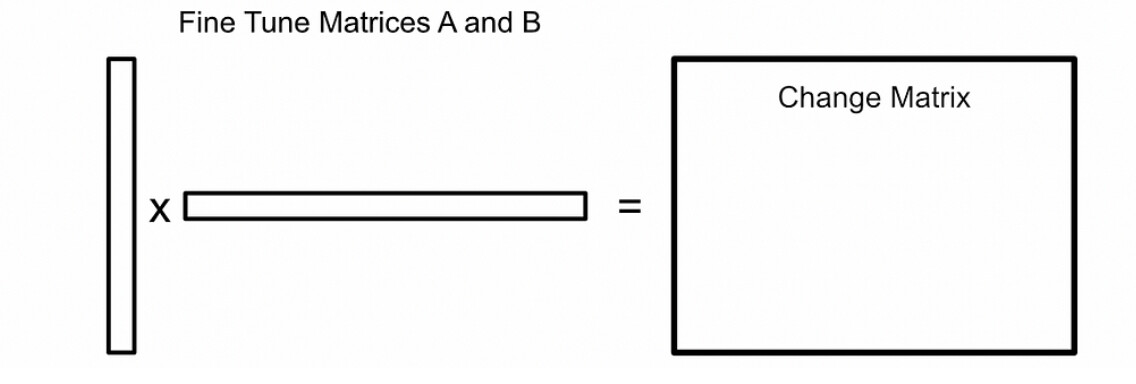
然后将输入通过冻结的权重和变化矩阵传递:
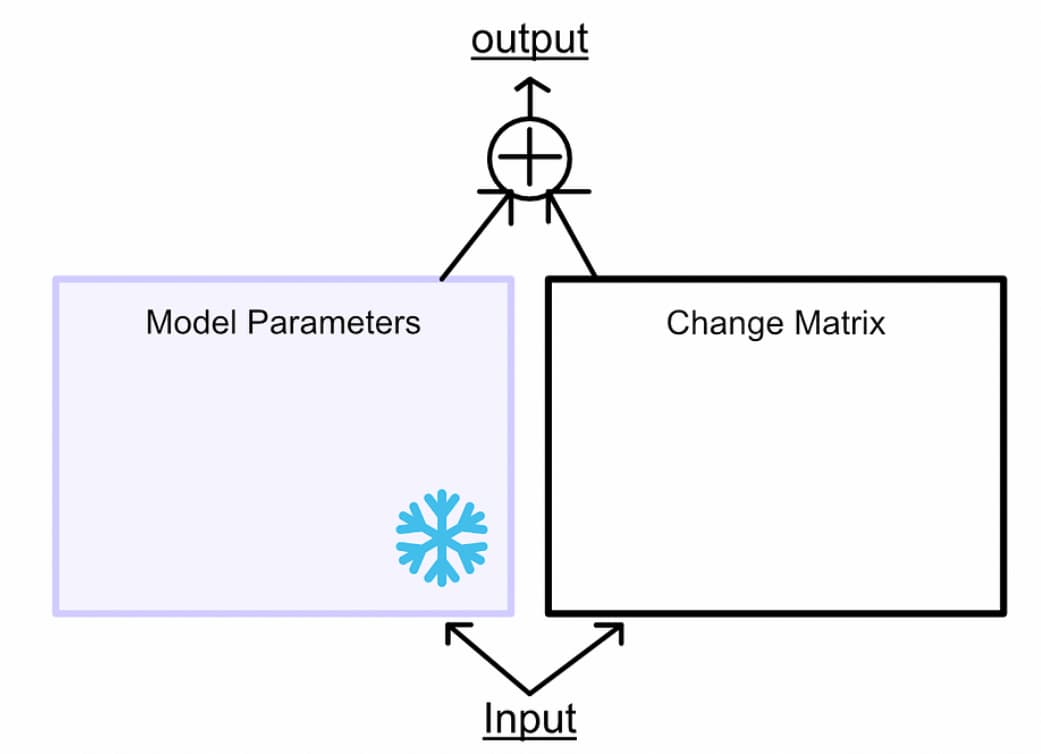
这些变化矩阵是即时计算的,从未被存储 ,这就是为什么LoRA的内存占用如此小的原因。实际上,在训练期间只存储模型参数、矩阵A和B以及A和B的梯度。

昇思+开发板微调实战全流程
代码实现知识点
MindSpore在将数据预处理操作应用到数据集时,代码实现会和Hugging Face Transformers有所区别。
MindSpore配合数据处理Pipeline来实现数据预处理,所有的
数据变换通过.map(…)方法传入,需要指定作用的数据列。
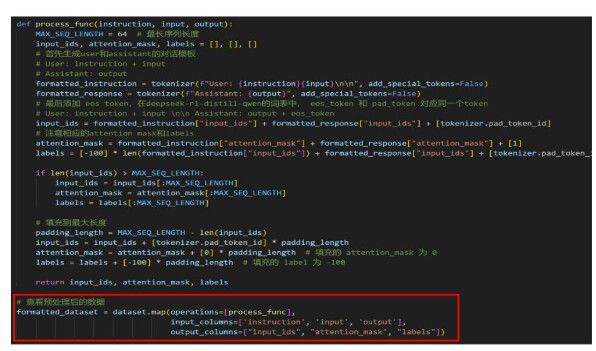
1,map(..)操作可以针对数据集指定列(column)添加数据变换(Transforms),将数据变换应用于该列数据的每
个元素,并返回包含变换后元素的新数据集。
2.map(..)操作可以执行Dataset模块提供的内置数据变换操作,也可以执行用户自定义的变换操作。
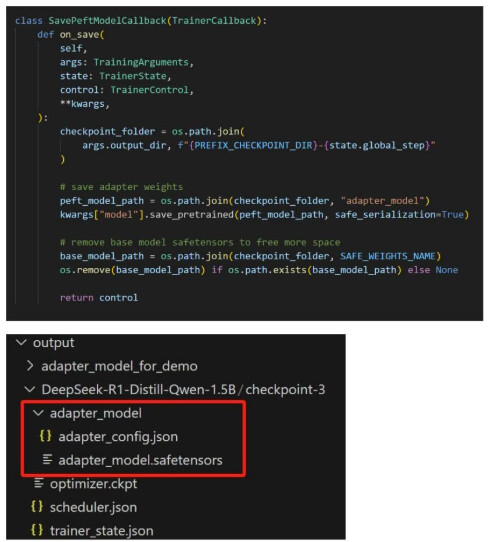
脚本中自定义了SavePeftModelCallback,即每次在save_steps个步数后,将模型当前的LoRAadapter权重保存下来,做到保存微调过程中的权重。保存后的权重可在指定的保存路径(案例中为“./output/DeepSeek-R1-Distill-Qwen-1.5B/adapter_model”)找到
优化方案
在加载模型时,直接加载fp16的权重,而非加载fp32权重再转成fp16

实操环节:
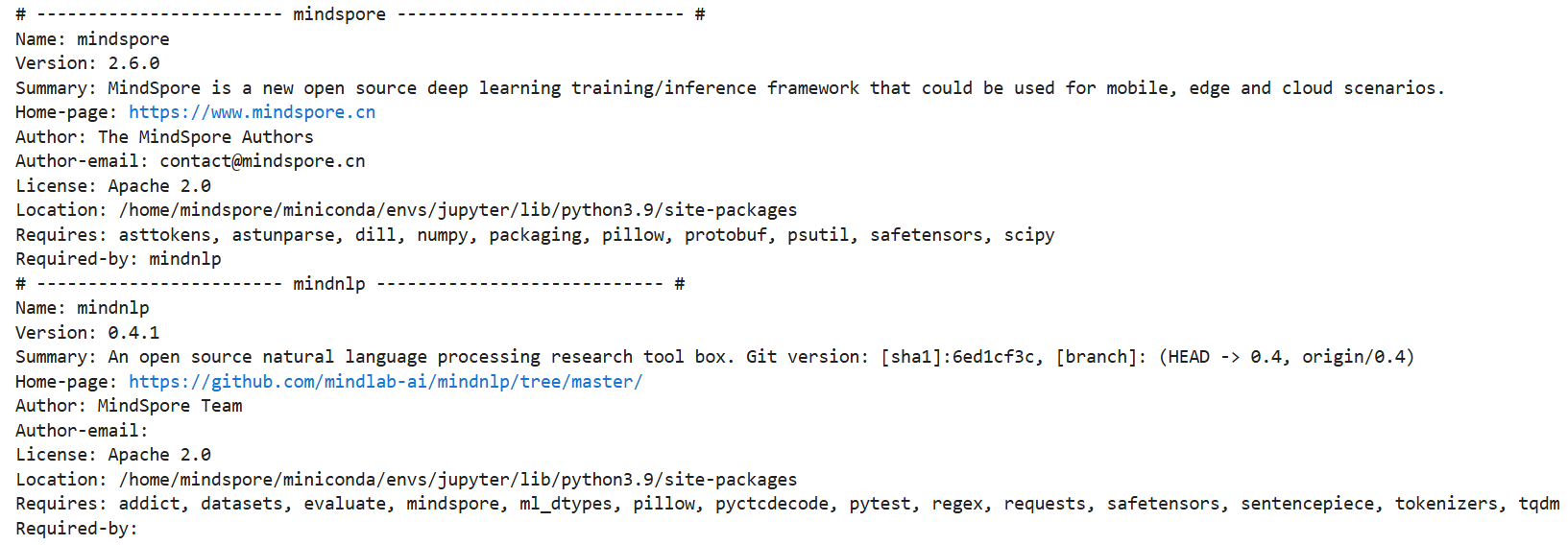
查看当前 mindspore 版本
下载与处理数据集

实例化tokenizer
![]()
实例化base model,LoRA配置,实例化LoRA模型

训练参数
