模型LoRA微调:
1.LORA 简介 “低秩适应”(LoRA)是一种“参数高效微调”(PEFT)的形式,它允许使用少量可学习参数对大型模型进行微调 。LoRA改善微调的几个点:
1.将微调视为学习参数的变化(▲w),而不是调整参数本身(w)。
2.通过删除重复信息,将这些变化压缩成较小的表示。
3.通过简单地将它们添加到预训练参数中来“加载”新的变化。
2.1 微调作为参数变化 正如之前讨论的,微调的最基本方法是迭代地更新参数。就像正常的模型训练一样,你让模型进行推理,然后根据推理的错误程度更新模型的参数。
与其将微调视为学习更好的参数,LoRA 将微调视为学习参数变化:冻结模型参数,然后学习使模型在微调任务中表现更好所需的这些参数的变化。
类似于训练,首先让模型推理,然后根据error进行更新。但是,不更新模型参数,而是更新模型参数的变化。
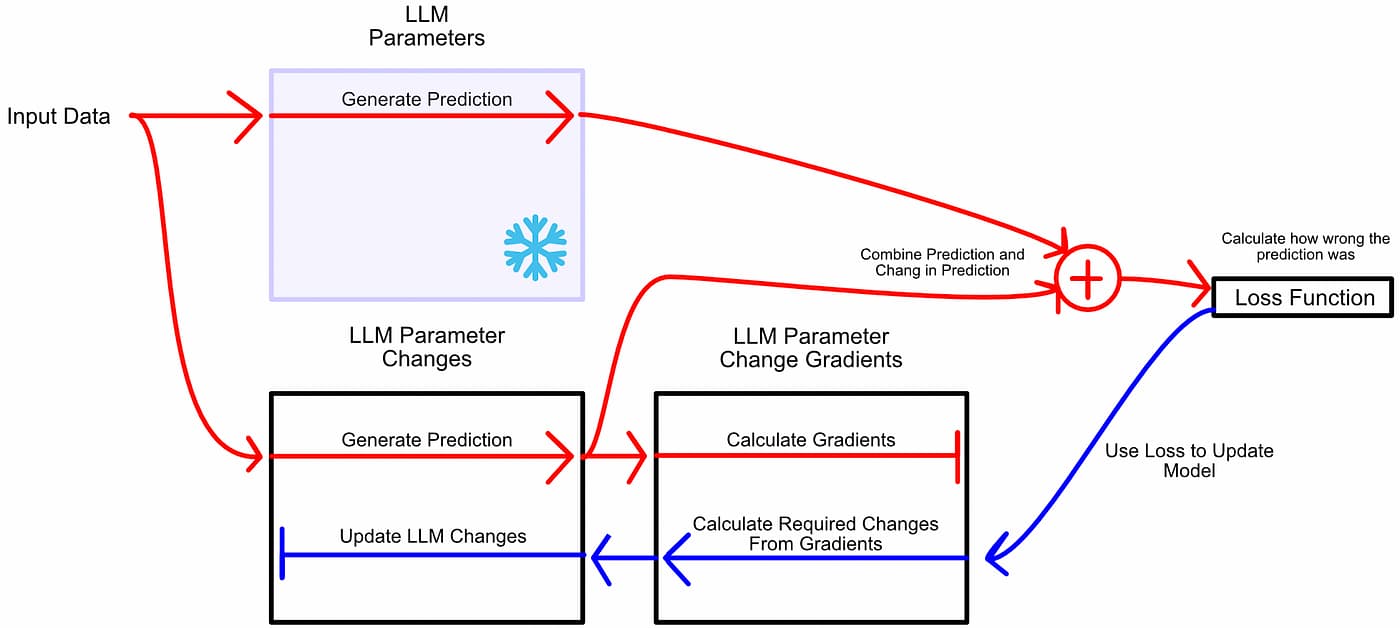
在LoRA中,我们冻结模型参数,并创建一组描述这些参数变化的新值。然后,我们学习必要的参数变化,以在微调任务上表现更好。LoRA添加更多的数据和额外的步骤,如何使微调变得更小、更快?
2.2 参数变化压缩
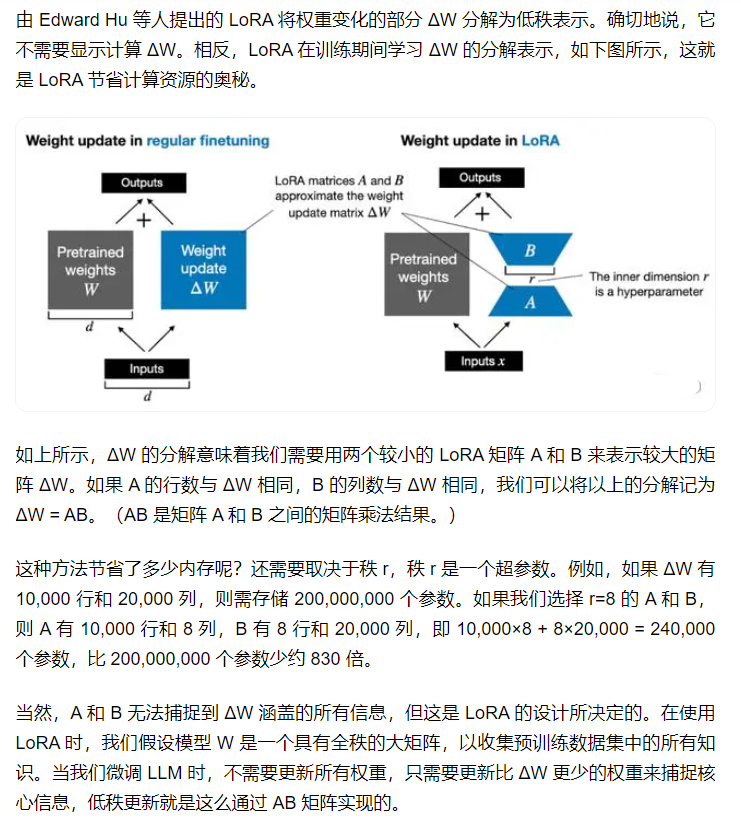
矩阵的秩是为了量化矩阵中的线性独立性。我们可以将一个矩阵分解为一些线性独立的向量;这种矩阵的形式被称为“行阶梯形式”。
因此,矩阵可以包含一定程度的“重复信息”,即线性相关性。如果你有一个大矩阵,具有显著的线性相关性(因此秩较低),可以将该矩阵表示为两个相对较小的矩阵的乘积。这种分解的思想使得LoRA占用了如此小的内存空间。
2.实操环节
mindnlp和mindspore:
数据集处理和模型加载和 lora 参数配置:


定义数据处理逻辑
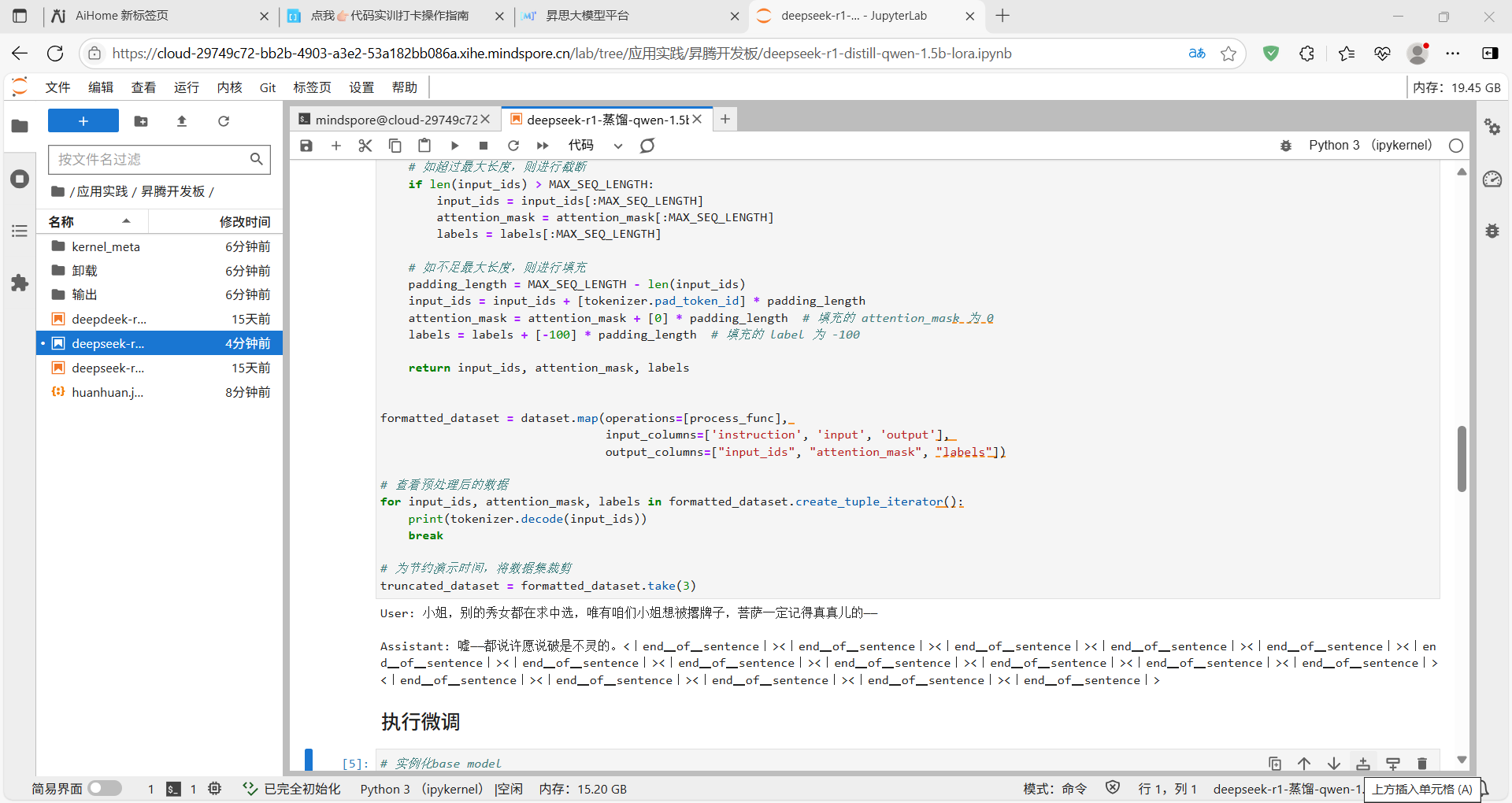
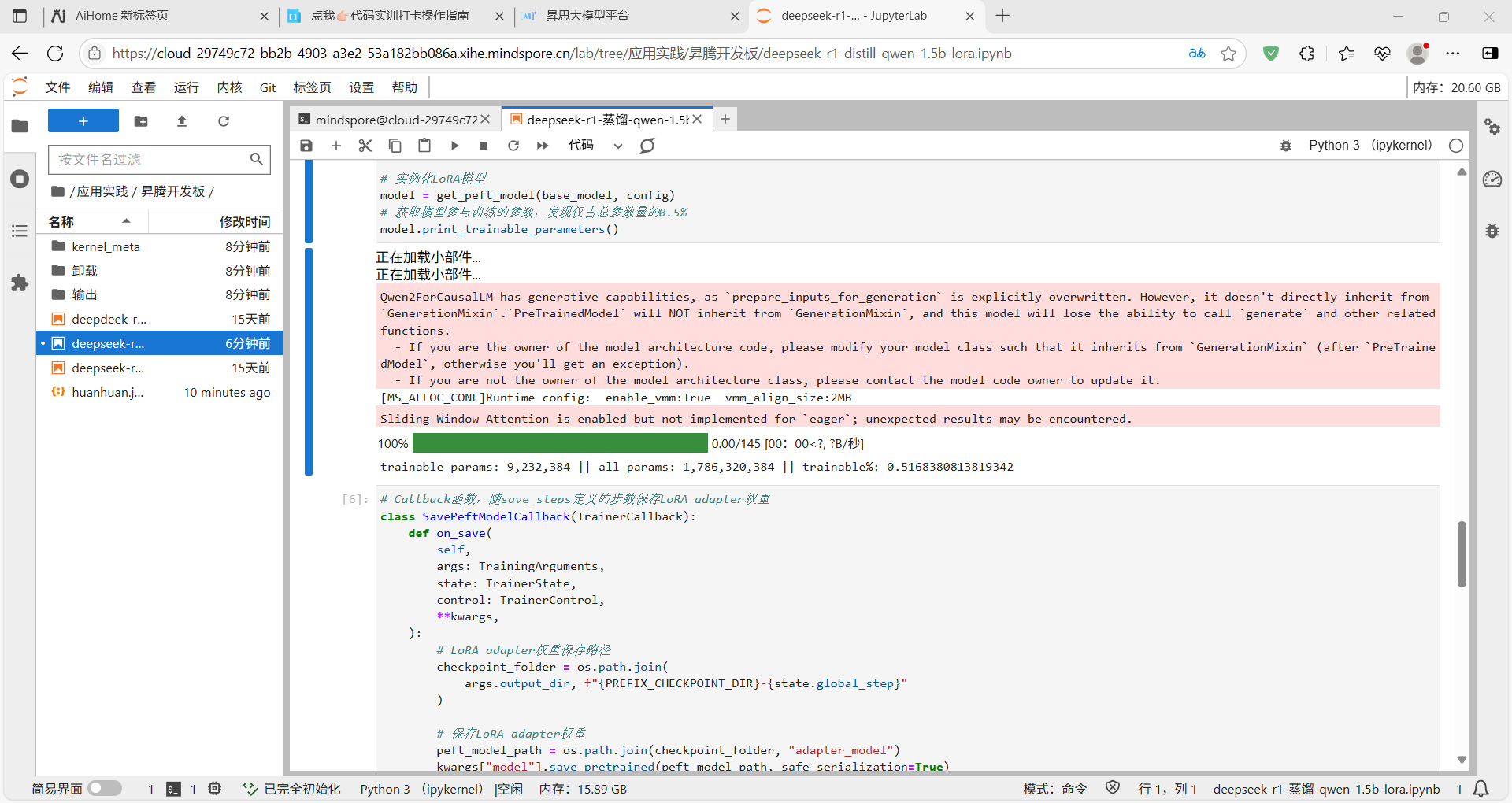
执行微调

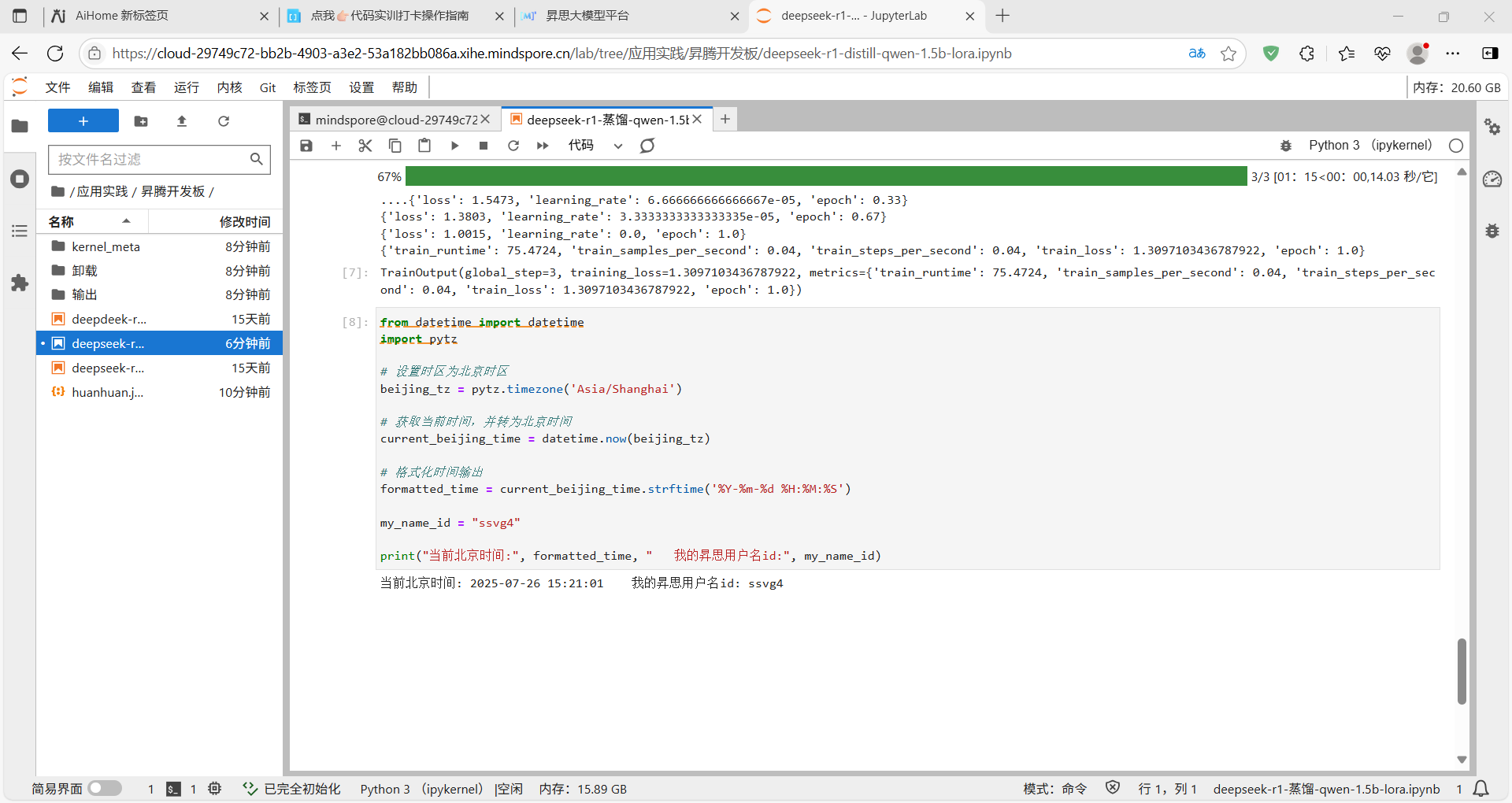
3.小结
使用 MindNLP 进行 LoRA 微调仅需微调少量参数,显著减少训练时的显存占用,对一些配置不太好的初级炼丹师而言非常友好,而且对于小数据集效果更加显著,可谓入门选手的最佳选择