LoRA 的介绍
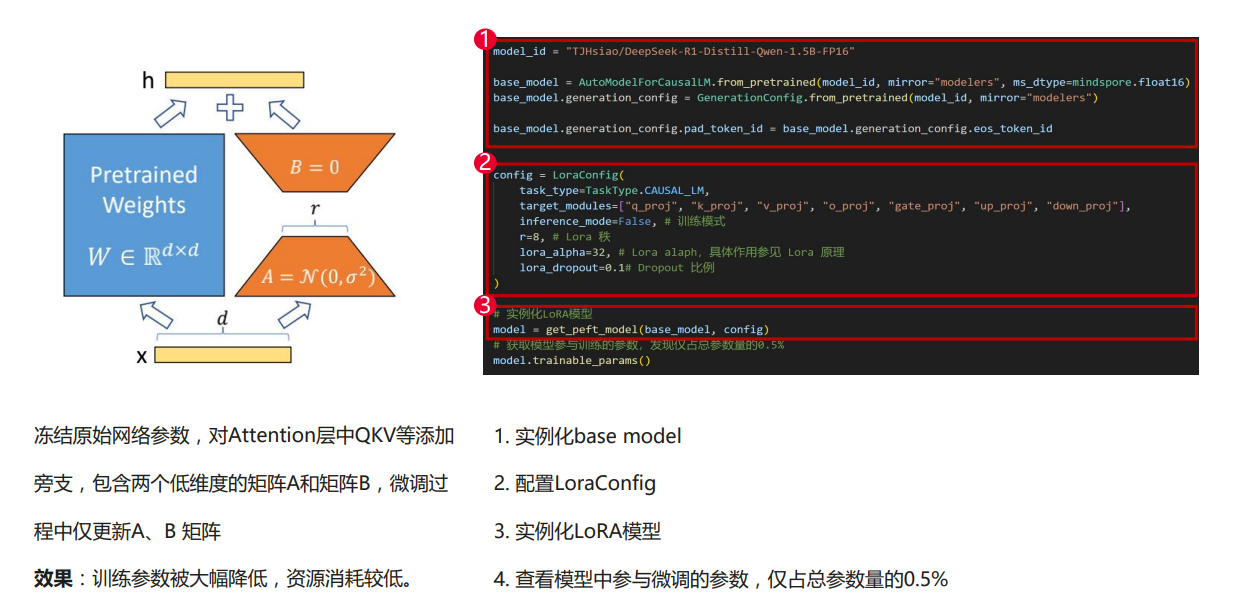
LoRA(Low-Rank Adaptation)是一种高效的参数微调方法,属于参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)范式。其核心思想是在冻结原始模型参数的基础上,在 Attention 层中的 Query、Key、Value(QKV)等模块引入一个低秩旁路结构。
该旁路由两个可训练的低维矩阵 A 和 B 组成,替代对原始大矩阵的直接更新。微调过程中仅更新 A 和 B,从而显著减少训练参数量,降低计算与内存开销,同时保持接近全参数微调的性能表现。
LoRA的主要优点之一是他们的效率。通过使用更少的参数,LoRA显著降低了模型训练过程中计算复杂性和显存使用量。这可以让我们在消费级的GPU上来训练大模型,并且可以便利地将我们训练好的LoRA权重(以兆为单位)分发给其他人。
此外,LoRA可以提升模型的泛化性。通过限制模型的复杂度,可以有助于防止在训练数据有限场景下的过拟合现象;由于LoRA至少保留了初始模型的能力,在处理一些新的,未见过的数据时更具有弹性。
最后,LoRA可以无缝地集成到现有的神经网络架构中。这种集成允许以最小的额外训练成本对预训练模型进行微调和调整,使其非常适合迁移学习应用。
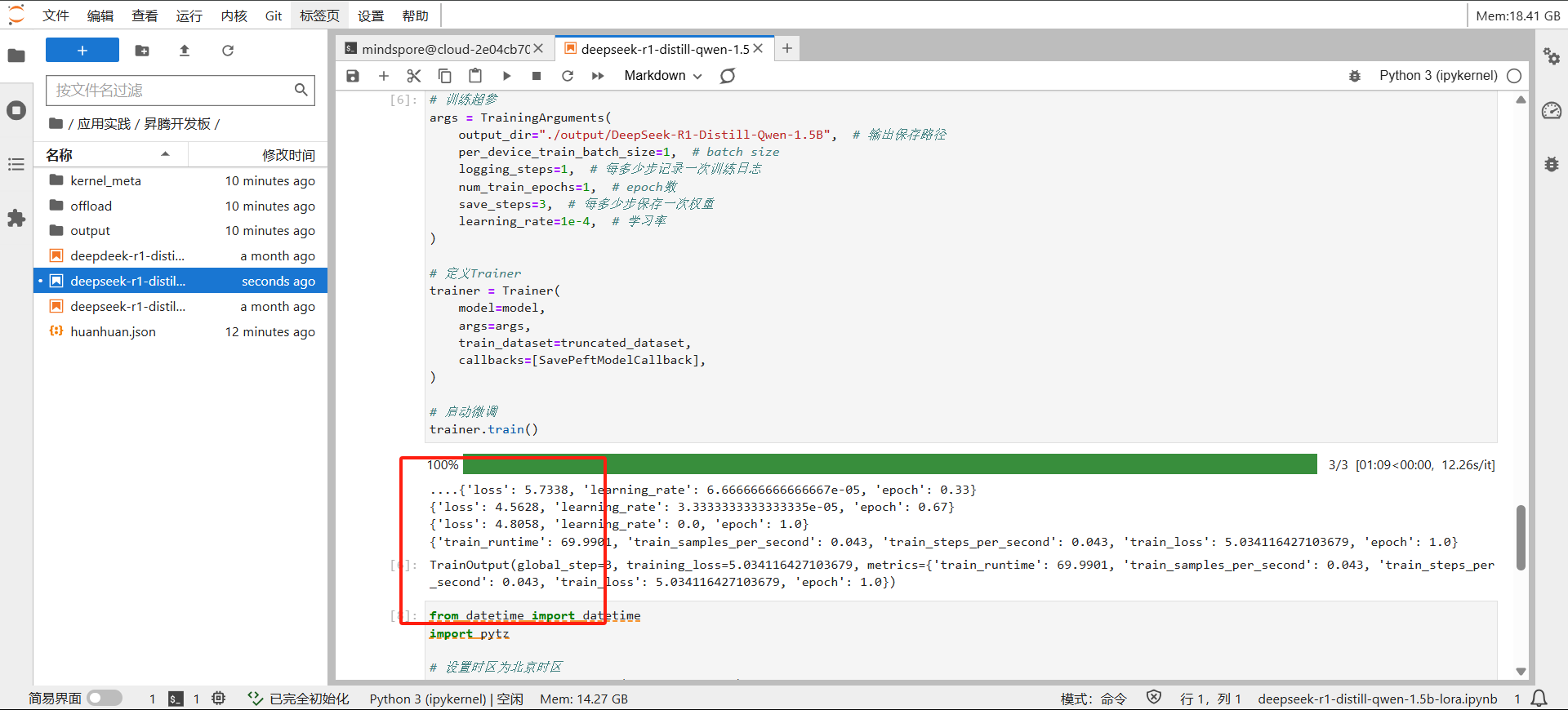
由于环境已经配置好了,下面我们直接开始进行lora的微调实操
但是在此之前,我们还需要解决一个非常头疼的问题,就是解决对应的报错定位,此时,mindspore给我们提供了一个比较好用的工具:
本次演示我们仅对少量数据进行LoRA微调,建议也同时通过mindspore.set_context(pynative_synchronize=True)开启同步,方便在出现问题时进行快速定位。
代码实现知识点1:
MindSpore在将数据预处理操作应用到数据集时,代码实现会 和Hugging Face Transformers有所区别。 MindSpore配合数据处理Pipeline来实现数据预处理,所有的 数据变换通过.map(…)方法传入,需要指定作用的数据列。
代码实现知识点2:
脚本中自定义了SavePeftModelCallback,即每次在 save_steps个步数后,将模型当前的LoRA adapter权重保 存下来,做到保存微调过程中的权重。
经验分享:
香橙派AIpro的host侧和device侧共享,所以在host侧的内存占用(如python的多进程,模型加载等)也会影响到显存。
相应的优化方案:

数据集准备:
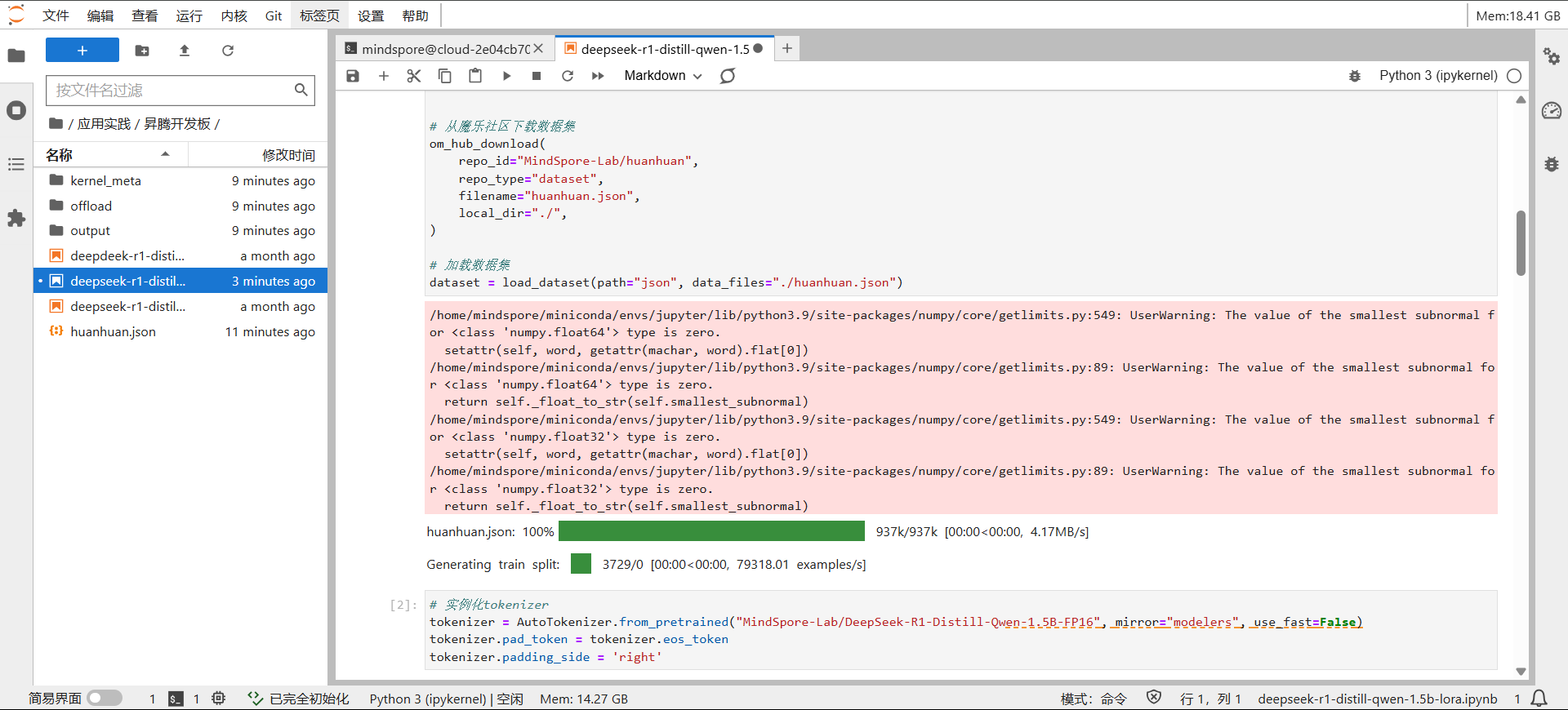
数据集处理加载:
下载模型和对应微调参数的设置
开始进行sft: