昇思学习营第七期·昇腾开发板 学习打卡_第二次
模型LoRA微调:
lora微调算法的介绍:
在平时,我们进行模型微调,主要是有两种模型微调方式(全参数微调和参数高效微调)。我们平时所用的基本都是参数高效微调(Parameter-Efficient Fine Tuning),主要是因为资源和数据量的大小限制了我们(说白了就是没得这个财力和精力),但是全参数微调(Full Fine-Tuning)对我们来说也没有必要,因为参数高效微调已经能够起到四两拨千斤的效果了,对个人和小型团队依然够用。
我们看一下参数高效微调和全参数微调的适用场景对比:
适用场景对比
| 场景 | 全参数微调(Full Fine-Tuning) | 参数高效微调(PEFT) |
|---|---|---|
| 数据量充足 | ||
| 资源有限(如单卡训练) | ||
| 任务与预训练差异大 | ||
| 多任务快速适配 | ||
| 防止灾难性遗忘 |
下面是PEFT给出的常用的几种微调方法:
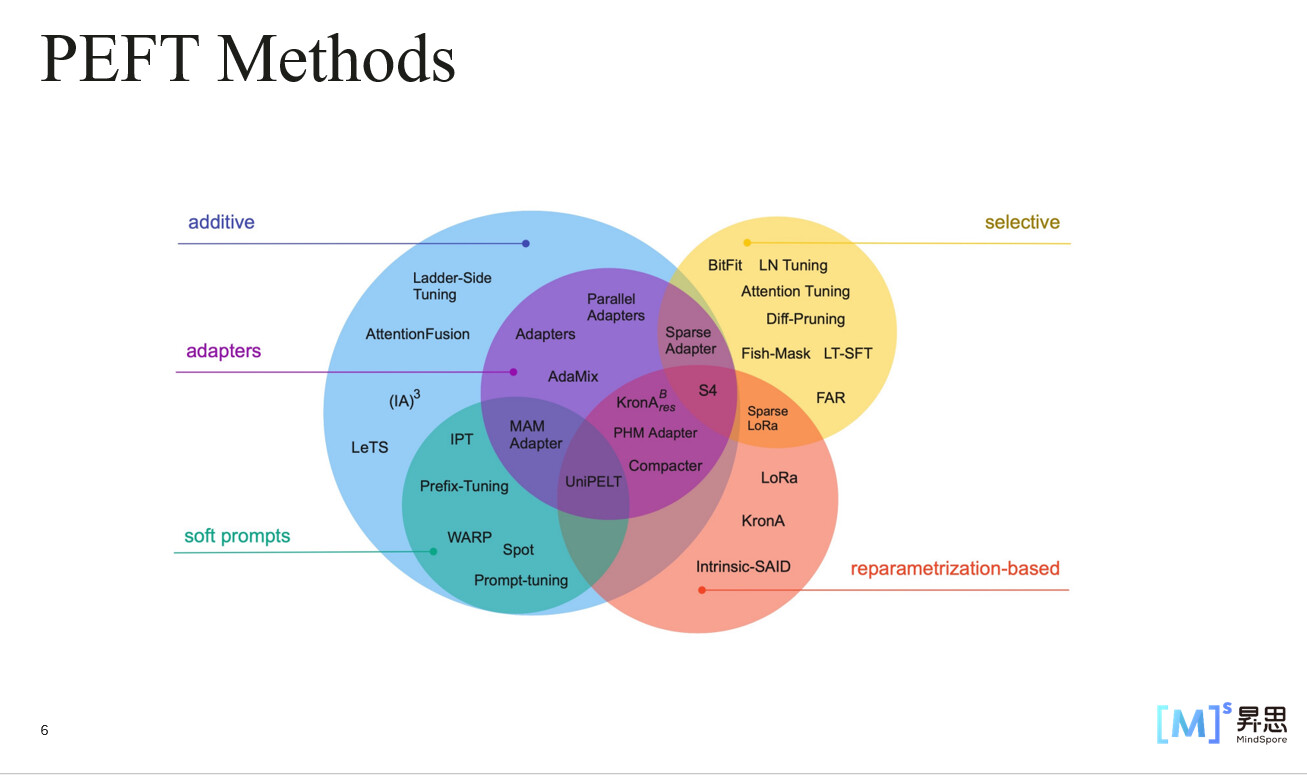
我们平时用的主要方式就是lora,今天我们学习的主角也是lora微调。
所以这里我记录一下我学习用mindnlp进行lora微调的过程以及与用transformers进行lora微调的对比:
先说一下原理(ps:这里参考了一下一个B站UP主的,UP讲的很好很用心,UP的主页https://space.bilibili.com/21060026):
- 预训练模型中存在一个极小的内在维度,这个内在维度是发挥核心作用的地方。
- 在继续训练的过程中,权重的更新依然也有如此特点,即也存在一个内在维度(内在秩)。
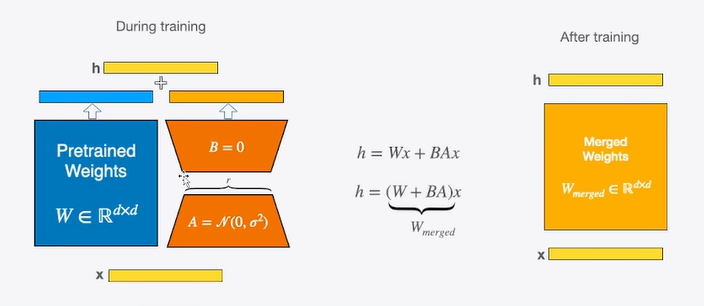
- 权重更新:W=W+△W
- 因此,可以通过矩阵分解的方式,将原本要更新的大的矩阵变为两个小的矩阵。
- 权重更新:W=W+△W=W+BA
- 具体做法,即在矩阵计算中增加一个旁系分支,旁系分支由两个低秩矩阵A和B组成。
- 训练时,输入分别与原始权重和两个低秩矩阵进行计算,共同得到最终结果,优化则仅优化A和B。
- 训练完成后,可以将两个低秩矩阵与原始模型中的权重进行合并,合并后的模型与原始模型无异,避免了推理期间Prompt系列方法带来的额外计算量 。
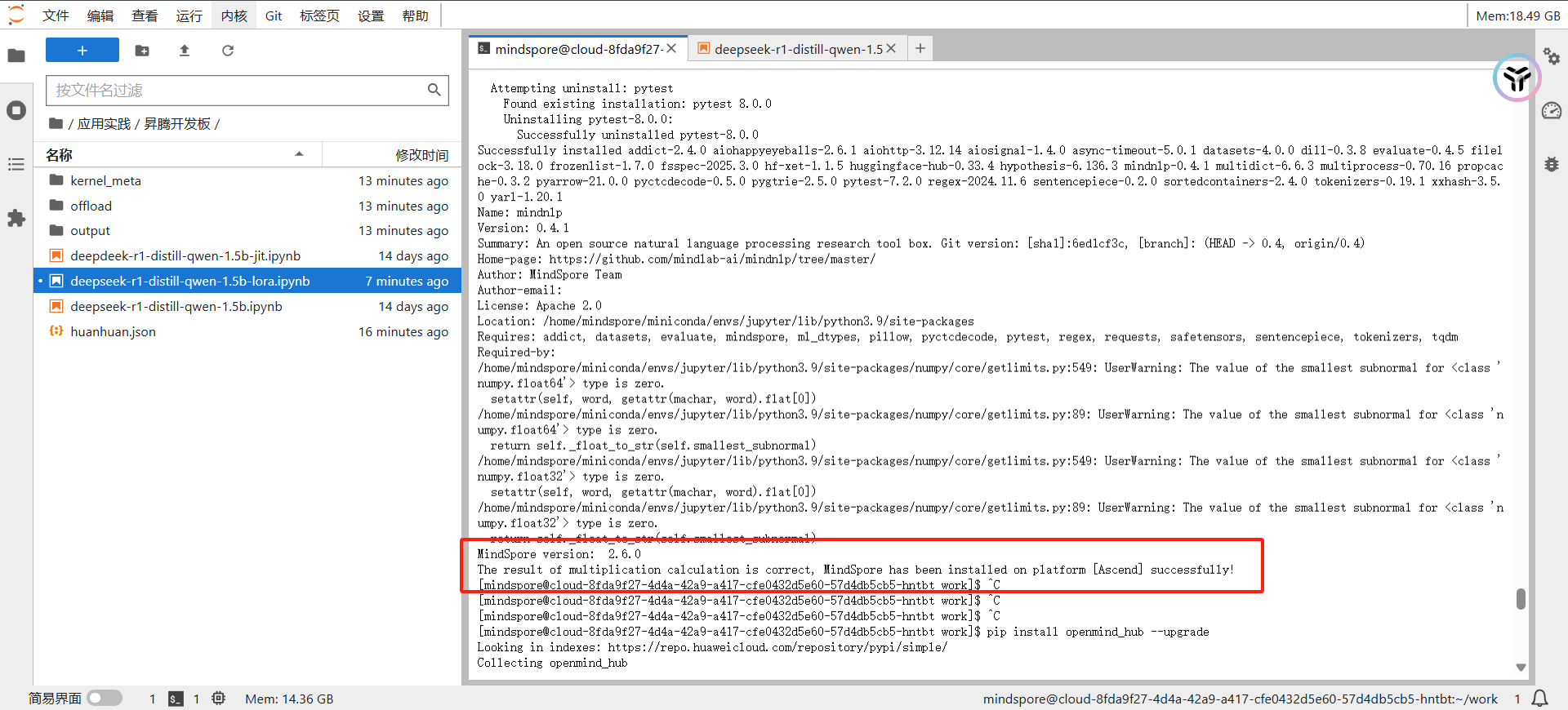
然后是最最基本的,环境安装和验证:
环境检查安装:
bash requ.sh
requ.sh源文件:
#!/bin/bash
# 克隆仓库
git clone https://openi.pcl.ac.cn/MindSpore/mindnlp.git
# 进入仓库目录
cd mindnlp || { echo "进入 mindnlp 目录失败"; exit 1; }
# 查看所有分支
git branch -a
# 切换到 0.4 分支
git checkout 0.4
# 执行构建并重新安装脚本
bash scripts/build_and_reinstall.sh
# 显示 mindnlp 包的信息
pip show mindnlp
# 返回上一级目录
cd ..
# 安装openmind_hub
pip install openmind_hub --upgrade
# 检查 mindspore 是否正确安装并运行测试
python -c "import mindspore; mindspore.set_context(device_target='Ascend'); mindspore.run_check()"
echo "脚本执行完成"
只需要运行该脚本看到如下信息就代表成功了。
下面我们来对比一下:
- 先看一下我们最熟悉的transformers
# 导入相关包
from datasets import Dataset
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
# 加载数据集
model_name_or_path = "Langboat/bloom-1b4-zh"
data_path = "../data/alpaca_data_zh/"
ds = Dataset.load_from_disk(data_path)
# 数据集预处理
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
def process_func(example):
MAX_LENGTH = 256
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")
response = tokenizer(example["output"] + tokenizer.eos_token)
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenizer.decode(tokenized_ds[1]["input_ids"])
tokenizer.decode(list(filter(lambda x: x != -100, tokenized_ds[1]["labels"])))
# 创建模型
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, low_cpu_mem_usage=True)
# PEFT 配置文件
from peft import LoraConfig, TaskType, get_peft_model
config = LoraConfig(task_type=TaskType.CAUSAL_LM, target_modules=".*\.1.*query_key_value", modules_to_save=["word_embeddings"])
model = get_peft_model(model, config)
model.print_trainable_parameters()
# 配置训练参数
args = TrainingArguments(
output_dir="./chatbot",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
logging_steps=10,
num_train_epochs=1
)
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
trainer.train()
- mindnlp:
# 查看当前 mindspore 版本
print("# ------------------------ mindspore ---------------------------- #")
!pip show mindspore
print("# ------------------------ mindnlp ---------------------------- #")
!pip show mindnlp
import os
from mindnlp.transformers import AutoModelForCausalLM, AutoTokenizer
from mindnlp.engine import TrainingArguments, Trainer
from mindnlp.dataset import load_dataset
from mindnlp.transformers import GenerationConfig
from mindnlp.peft import LoraConfig, TaskType, get_peft_model
from mindnlp.engine.utils import PREFIX_CHECKPOINT_DIR
from mindnlp.configs import SAFE_WEIGHTS_NAME
from mindnlp.engine.callbacks import TrainerCallback, TrainerState, TrainerControl
from mindspore._c_expression import disable_multi_thread
disable_multi_thread() # 禁用多线程,提升微调性能
# 开启同步,在出现报错,定位问题时开启
# mindspore.set_context(pynative_synchronize=True)
from openmind_hub import om_hub_download
# 从魔乐社区下载数据集
om_hub_download(
repo_id="MindSpore-Lab/huanhuan",
repo_type="dataset",
filename="huanhuan.json",
local_dir="./",
)
# 加载数据集
dataset = load_dataset(path="json", data_files="./huanhuan.json")
# 实例化tokenizer
tokenizer = AutoTokenizer.from_pretrained("MindSpore-Lab/DeepSeek-R1-Distill-Qwen-1.5B-FP16", mirror="modelers", use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = 'right'
# 定义数据处理逻辑
def process_func(instruction, input, output):
MAX_SEQ_LENGTH = 64 # 最长序列长度
input_ids, attention_mask, labels = [], [], []
# 首先生成user和assistant的对话模板
# User: instruction + input
# Assistant: output
formatted_instruction = tokenizer(f"User: {instruction}{input}\n\n", add_special_tokens=False)
formatted_response = tokenizer(f"Assistant: {output}", add_special_tokens=False)
# 最后添加 eos token,在deepseek-r1-distill-qwen的词表中, eos_token 和 pad_token 对应同一个token
# User: instruction + input \n\n Assistant: output + eos_token
input_ids = formatted_instruction["input_ids"] + formatted_response["input_ids"] + [tokenizer.pad_token_id]
# 注意,我们在微调时仅考虑Assistant部分回答的内容,所以User部分提问的内容对应的标签为-100
attention_mask = formatted_instruction["attention_mask"] + formatted_response["attention_mask"] + [1]
labels = [-100] * len(formatted_instruction["input_ids"]) + formatted_response["input_ids"] + [tokenizer.pad_token_id]
# 如超过最大长度,则进行截断
if len(input_ids) > MAX_SEQ_LENGTH:
input_ids = input_ids[:MAX_SEQ_LENGTH]
attention_mask = attention_mask[:MAX_SEQ_LENGTH]
labels = labels[:MAX_SEQ_LENGTH]
# 如不足最大长度,则进行填充
padding_length = MAX_SEQ_LENGTH - len(input_ids)
input_ids = input_ids + [tokenizer.pad_token_id] * padding_length
attention_mask = attention_mask + [0] * padding_length # 填充的 attention_mask 为 0
labels = labels + [-100] * padding_length # 填充的 label 为 -100
return input_ids, attention_mask, labels
formatted_dataset = dataset.map(operations=[process_func],
input_columns=['instruction', 'input', 'output'],
output_columns=["input_ids", "attention_mask", "labels"])
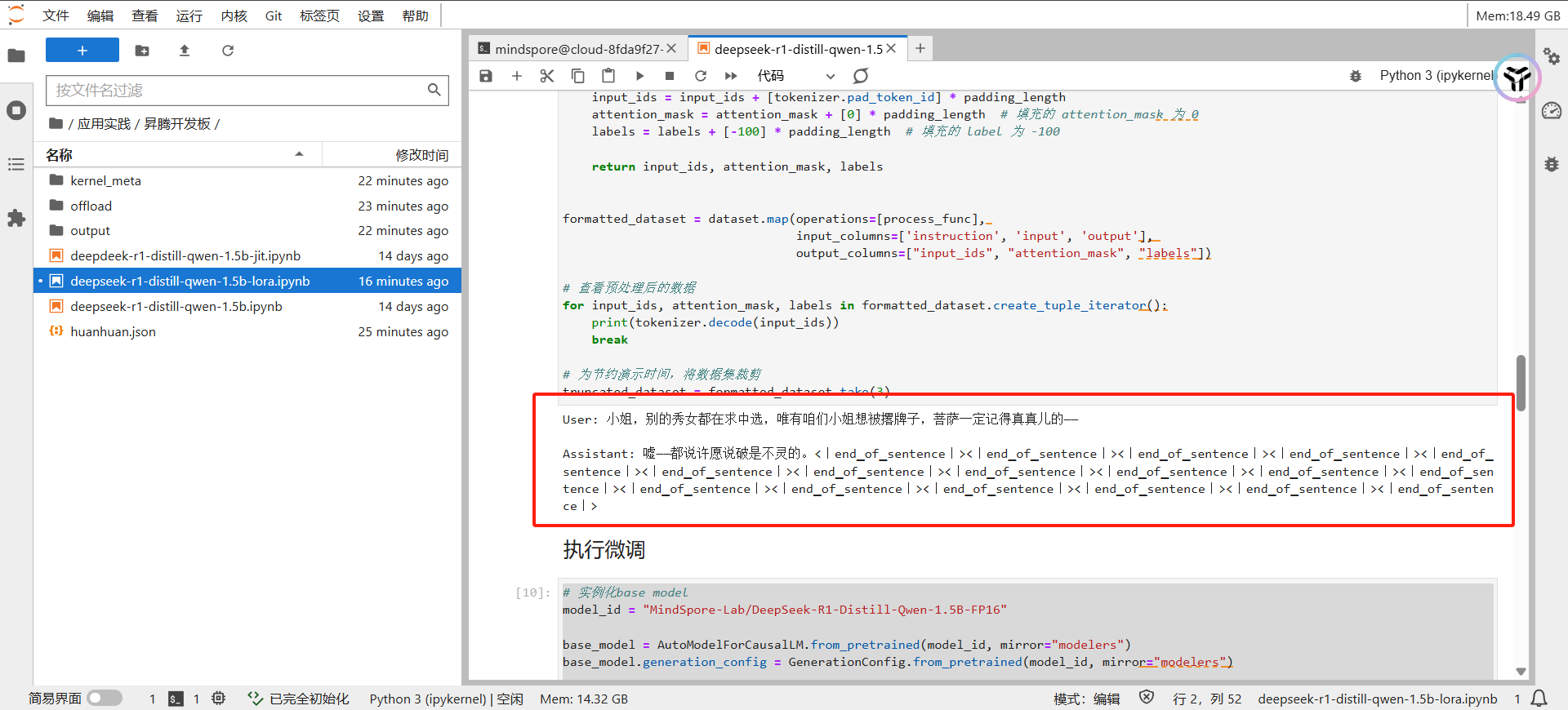
# 查看预处理后的数据
for input_ids, attention_mask, labels in formatted_dataset.create_tuple_iterator():
print(tokenizer.decode(input_ids))
break
# 为节约演示时间,将数据集裁剪
truncated_dataset = formatted_dataset.take(3)
# 实例化base model
model_id = "MindSpore-Lab/DeepSeek-R1-Distill-Qwen-1.5B-FP16"
base_model = AutoModelForCausalLM.from_pretrained(model_id, mirror="modelers")
base_model.generation_config = GenerationConfig.from_pretrained(model_id, mirror="modelers")
base_model.generation_config.pad_token_id = base_model.generation_config.eos_token_id
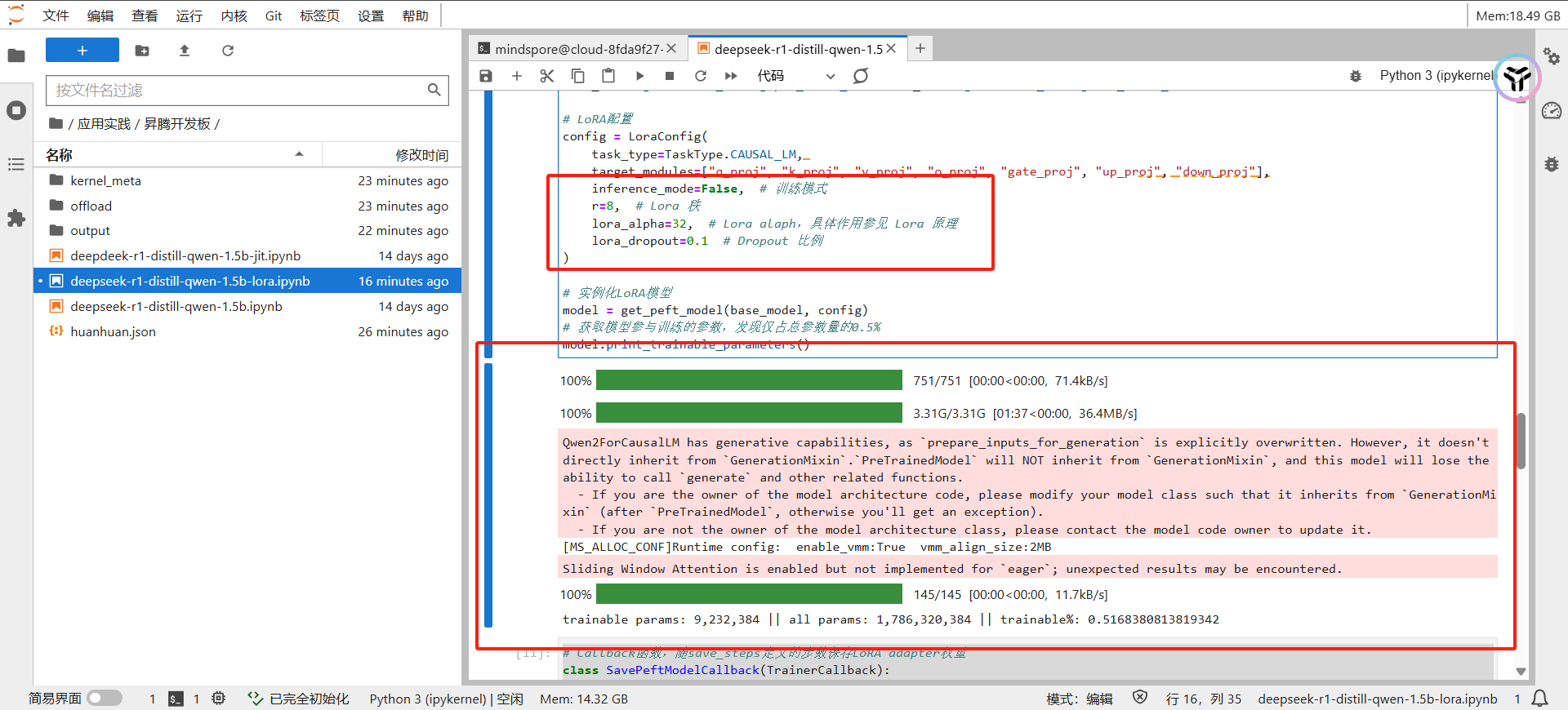
# LoRA配置
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1 # Dropout 比例
)
# 实例化LoRA模型
model = get_peft_model(base_model, config)
# 获取模型参与训练的参数,发现仅占总参数量的0.5%
model.print_trainable_parameters()
# Callback函数,随save_steps定义的步数保存LoRA adapter权重
class SavePeftModelCallback(TrainerCallback):
def on_save(
self,
args: TrainingArguments,
state: TrainerState,
control: TrainerControl,
**kwargs,
):
# LoRA adapter权重保存路径
checkpoint_folder = os.path.join(
args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}"
)
# 保存LoRA adapter权重
peft_model_path = os.path.join(checkpoint_folder, "adapter_model")
kwargs["model"].save_pretrained(peft_model_path, safe_serialization=True)
# 移除额外保存的base model的model.safetensors,节约空间
base_model_path = os.path.join(checkpoint_folder, SAFE_WEIGHTS_NAME)
os.remove(base_model_path) if os.path.exists(base_model_path) else None
return control
# 训练超参
args = TrainingArguments(
output_dir="./output/DeepSeek-R1-Distill-Qwen-1.5B", # 输出保存路径
per_device_train_batch_size=4, # batch size
logging_steps=1, # 每多少步记录一次训练日志
num_train_epochs=15, # epoch数
save_steps=3, # 每多少步保存一次权重
learning_rate=1e-4, # 学习率
)
# 定义Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=truncated_dataset,
callbacks=[SavePeftModelCallback],
)
# 启动微调
trainer.train()
| 对比维度 | Hugging Face Transformers | MindSpore |
|---|---|---|
| 数据处理 | 使用datasets.Dataset.load_from_disk加载数据集。自定义process_func进行数据预处理,包括指令、输入和输出的格式化。 利用tokenizer对文本进行编码,并处理成模型输入格式。 |
使用mindnlp.dataset.load_dataset加载数据集。定义process_func来处理数据,包含用户指令和模型响应的格式化。同样利用tokenizer对文本编码,但可能需要适应MindSpore的数据结构。 |
| 模型加载 | 使用transformers.AutoTokenizer和AutoModelForCausalLM从指定路径加载预训练模型及分词器。通过PEFT库配置LoRA适配器并应用到模型上。 |
使用mindnlp.transformers.AutoTokenizer和AutoModelForCausalLM加载模型。PEFT配置同样用于创建LoRA适配器,但具体实现可能略有不同。 |
| 训练设置 | 定义TrainingArguments对象,设置如批量大小、梯度累积步数、日志记录间隔等参数。使用Trainer类来封装训练逻辑。 |
类似地定义训练参数,使用MindSpore特定的参数调整。使用MindSpore的Trainer类,同时可以添加自定义回调函数(如保存检查点)。 |
| 训练过程 | 调用trainer.train()启动训练。可以集成自定义的回调函数以执行额外的操作,例如在特定步骤保存模型。 |
同样调用trainer.train()开始训练。支持更灵活的回调机制,比如在MindSpore中可以更加细致地控制如何以及何时保存模型权重。 |
实操环节:
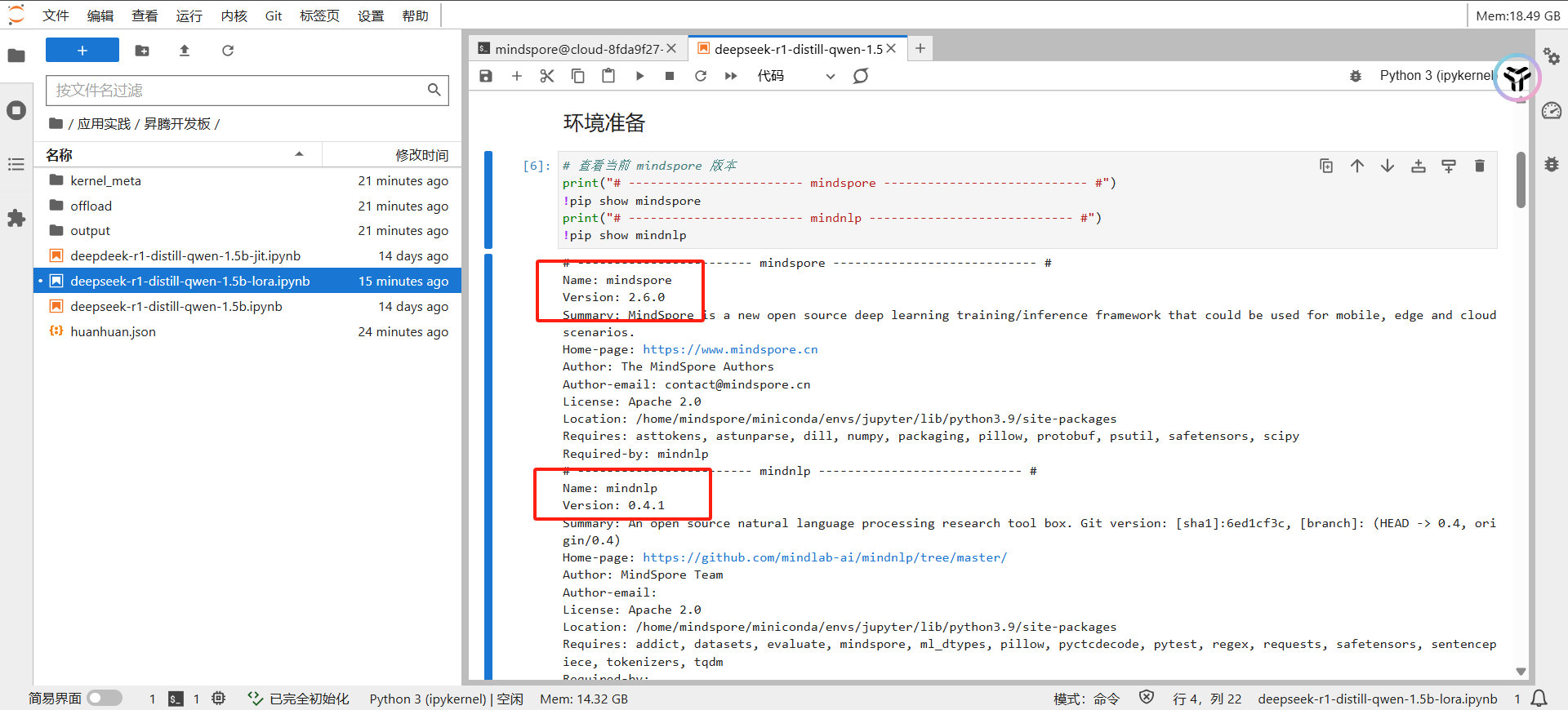
可以看到,运行上面的脚本后,mindspore和mindnlp都是安装成功的。
然后进行数据集处理和模型加载和 lora 参数配置:
进行训练参数的配置和开始训练:
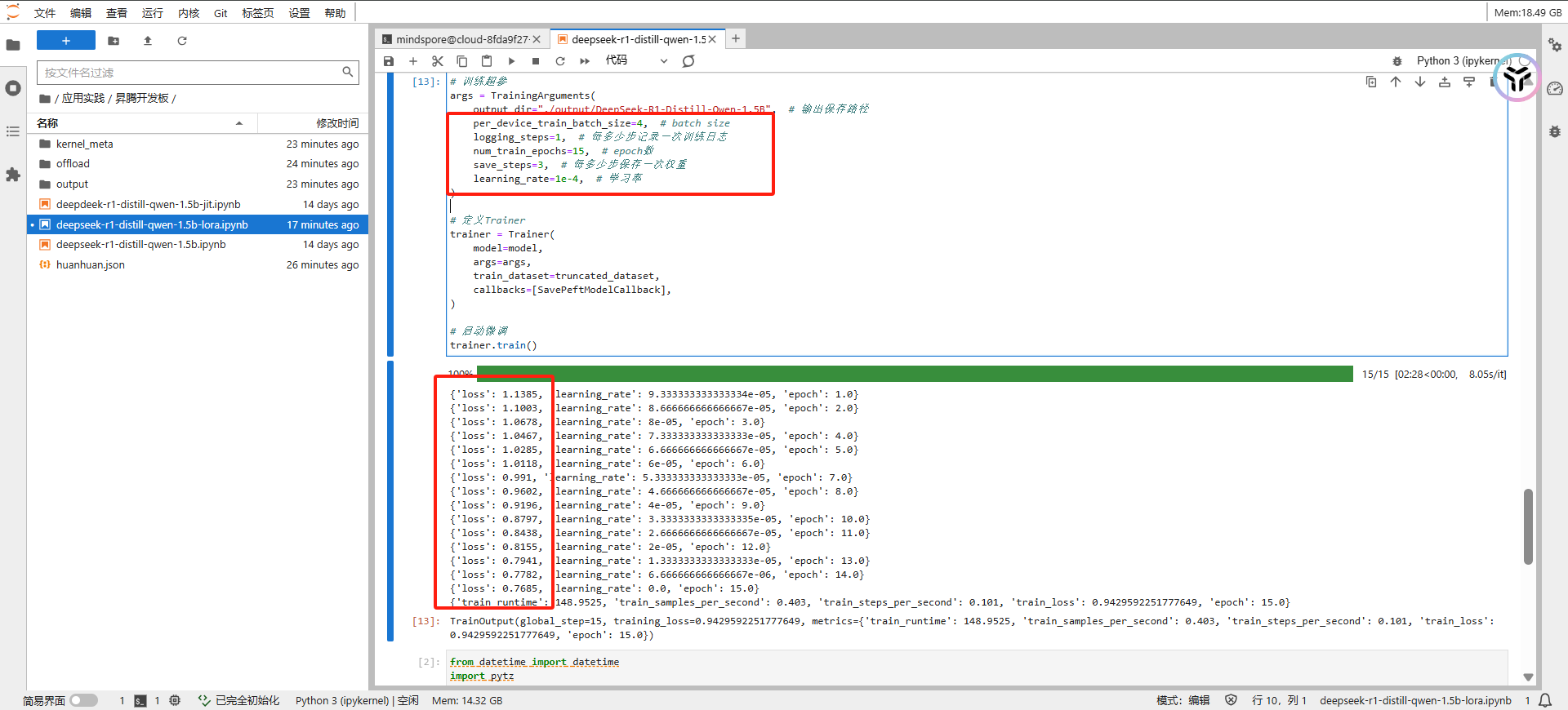
可以看到,由于是在910a上跑的,我们可以适当的吧per_device_train_batch_size设置大一点,改为4
为了看到明显的效果,我们把num_train_epochs改为15,可以看见loss值下降明显。
至此,我们的实操训练结束。