昇思MindSpore开源实习模型论文解读任务已顺利完成,共收到模型论文解读稿件10+篇。欢迎开发者积极参与昇思MindSpore开源实习活动,开源实习暑期活动已开启,更多新任务等你来挑战!
在自然语言处理(NLP)领域,长文本的高效处理是近几年来学术界和工业界的研究热点之一。对于长文本处理问题,Google 团队提出的 BigBird-Pegasus 模型,不但继承了 BigBird 模型处理长序列数据的优势,还通过 Pegasus 的优化,提高了文本摘要的能力。本文将深入探讨 BigBird-Pegasus 的独特创新点,展示它在各大数据集上的卓越表现,并利用 MindSpore NLP 进行实际代码实现和模型测评,详细对比其与其他模型的优势。
在详细介绍 BigBird-Pegasus 之前,我们需要理解它的两个组成部分:BigBird 和 Pegasus。BigBird 是一种基于 Transformer 的模型,它通过创新的稀疏注意力机制解决了处理长序列时的计算和内存瓶颈问题。而 Pegasus 则是专门为文本摘要任务设计的预训练模型,它通过预训练任务的优化,提高了下游文本摘要等任务的效果。
# 01
BigBird 模型
1、提出背景
想象这样一个场景:你想使用 AI 为一篇20页的学术论文生成摘要。这个看似简单的任务实际上暴露了当前 NLP 技术的一个重要局限。传统的 Transformer 模型,尽管在各类 NLP 任务上表现出色,但在处理长文本时却显得力不从心。目前的大部分 Transformer 模型最多只能处理512个或1024个 token,大约相当于一到两页纸的内容。换句话说,让模型只看论文的前几页就要生成整篇论文的摘要,这显然是不合理的。
这个问题的根源在于 Transformers 的自注意力机制 。尽管自注意力机制让模型能够灵活地捕获序列中的长距离依赖关系,但它的计算复杂度是序列长度 $n$ 的平方乘上特征维度 $d$,即 $O(n^2d)$。当文本长度增加时,计算资源的消耗迅速增加。这不仅会带来巨大的计算开销,还会导致严重的内存问题。在实际应用中,我们经常不得不截断输入文本,这不可避免地会丢失部分重要信息。
Transformers 模型的 token 长度限制不仅影响摘要生成,还广泛存在于各类需要理解长文本的任务中。例如,在医疗领域,一份完整的病历可能包含数千甚至上万个单词;在法律领域,一份合同文件往往有几十页之长;即使是平常的聊天机器人应用中,我们也希望模型能够记住并理解我们包含多轮对话的长交互历史。这些场景都迫切需要能够高效处理长序列的解决方案。
而 Google 团队在论文 Big Bird: Transformers for Longer Sequences 中提出的 BigBird 模型,其诞生的目的就是解决 Transformers 模型在长序列数据下面临的计算复杂度激增问题。
2、模型简述
BigBird 是一种基于 Transformer 的模型,它通过创新的稀疏注意力机制 ,将 Transformers 模型的二次依赖 优化为线性依赖 ,解决了处理长序列时的计算和内存瓶颈问题,从而将 Transformers 模型(如 BERT 等)在长序列场景下进行扩展。Google 团队在论文中,从理论上证明了应用稀疏注意力机制的效果接近于完全注意力机制,同时对于较长的序列来说计算效率更高。由于能够处理更长的上下文,与 BERT 或 RoBERTa 等模型相比,BigBird 在各种长文本 NLP 任务(例如问答和摘要)上所表现的性能要更为出色。
3、稀疏 注意力机制
Google 团队思考了这样一个问题:是否真的需要让每个 token 都关注序列中的所有其他 token?而这其实也是对注意力机制其本质的探讨。
通过理论分析和实验验证,Google 团队发现,完全注意力虽然强大,但往往存在大量冗余计算。实际上,一个词的含义主要受其周围词的影响,而与远距离的词的关联相对较弱,但小部分词则可能与远距离的词关联性较强。此外,一些词在整段文本中的重要程度较高,大部分词都可能与前者有较强的关联(比如文章标题)。基于以上考虑,Google 团队提出了创新的稀疏注意力机制。
在 BigBird 模型中的稀疏注意力机制,论文将其分成了三个部分,即:随机注意力(Random Attention)、滑动窗口注意力(Window Attention)以及全局注意力(Global Attention)。
4、Random Attention
为了保证模型仍具有较好的捕获长距离依赖的能力,同时能使 token 之间进行更好的信息传递,BigBird 模型中具备 Random Attention,对于一个 token,会计算该 token 与随机几个词的注意力分数,假设每个 token 只与随机的 r 个 token计算注意力分数,那么总的时间复杂度为 O(r * n) = O(n) (r 为常数)。用示意图表示如下:
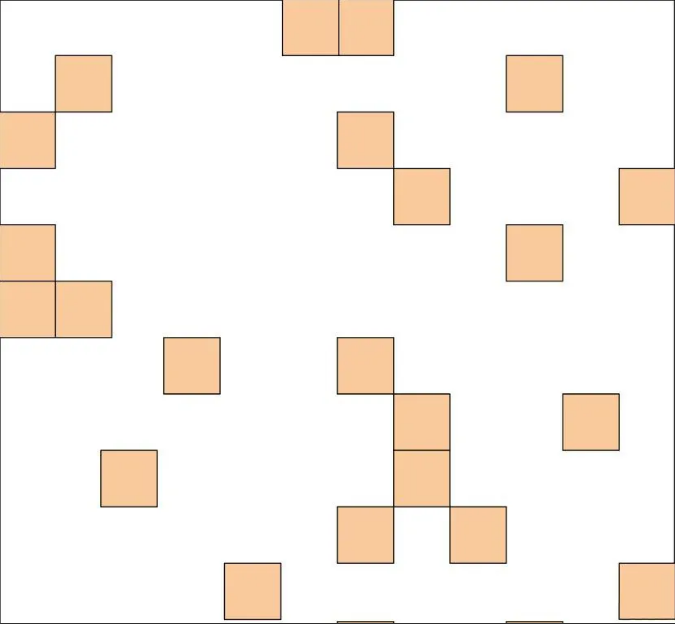
Random Attention
5、Window Attention
前面提到,一个词的含义主要受其周围词的影响。因此,BigBird 模型中也引入了 Window Attention,设定窗口大小为 w,对于每个 token,将会计算该 token 与该窗口内 w 个 token 的注意力分数,因此总的时间复杂度为 O(w * n) = O(n) (w 为常数)。用示意图表示如下:

Window Attention
6、Global Attention
前面提到,一些词在整段文本中的重要程度较高,而在 BigBird 模型的 Global Attention 中,将会选定 g 个 token,对于每个 token ,都需要计算其与这 g 个 token 的注意力分数。同理,总的时间复杂度为 O(g * n) = O(n) (g 为常数)。用示意图表示如下:

Global Attention
7、BigBird Sparse Attention
通过结合以上三种注意力机制,即可得到 BigBird 模型的注意力机制。从下面的示意图可以看到,稀疏注意力可以有效降低计算量,时间复杂度维持在 O(n),随 token 长度线性增长,从而缓解了在长文本情景下,模型计算量激增的问题。
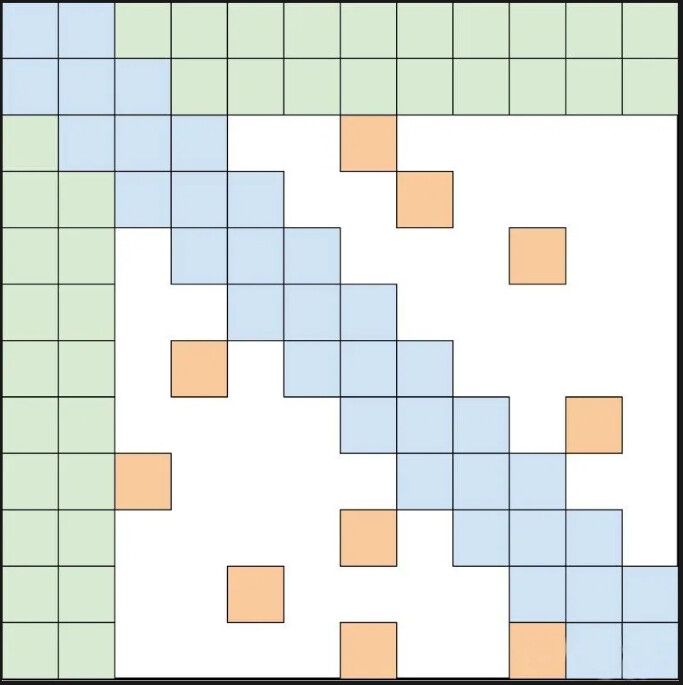
BigBird Sparse Attention
众所周知,Transformers 模型的特点是借助自注意力机制来处理长距离依赖,从而实现准确的文本理解能力。而 BigBird 模型设计的精妙之处则在于它巧妙地平衡了对局部信息和全局信息的获取。在稀疏注意力机制中,每个 token 会重点关注其周围固定窗口内的其他 token,符合语言的局部性原理;该机制设置了一些特殊的全局 token,从而关注整个序列,高效集成文本信息;通过随机注意力机制,每个 token 还能够随机地关注一些远距离位置,从而使得模型仍然具有捕获长距离依赖的能力。
# 02
Pegasus
1、 GSG 预训练目标
如果说 BigBird 的贡献在于解决长文本处理的计算难题,那么 Pegasus 则将文本摘要任务的效果推向了一个新的高度。传统的 NLP 模型在预训练阶段往往采用通用的目标函数,例如以 BERT 为代表的 Masked Language Model。而 Pegasus 则针对摘要任务这一下游任务进行了专门优化,创新性地引入了 Gap Sentence Generation(GSG)作为其预训练目标。
GSG 任务的核心思想是模拟摘要生成过程:通过从输入文本中屏蔽完整的句子,让模型预测被屏蔽的内容。这一方法使得 Pegasus 能够在预训练阶段学习如何提取文本中的关键信息,并生成具有高度概括性的句子。与其他预训练目标相比,GSG 更贴近摘要生成任务的实际需求,因此在下游任务中表现出了显著优势。
GSG 的实现策略是,选择一篇文章中对内容最重要的若干句子,作为目标摘要进行屏蔽。这些句子通常是文章的核心信息,而其余部分则作为上下文输入模型。通过这种方式,Pegasus 可以在预训练过程中不断优化对核心信息的捕获能力。
2、实 验效果
实验表明,Pegasus 在多个领域的数据集(如新闻、科学文献和医疗报告)上生成的文本摘要不仅覆盖了原文的重要信息,同时在语言流畅性和语义一致性上也达到了很高的水准。例如,在 CNN/DailyMail 数据集上的测试中,Pegasus 的 ROUGE 分数显著高于同期模型,其生成的摘要更接近人工撰写的结果。
# 03
BigBird-Pegasus
BigBird-Pegasus 即使用了 Pegasus 作为 Tokenizer 的 BigBird 模型,其结合了 Bigbird 和 Pegasus 两者的特点,既能高效处理长序列,又能生成高质量文本摘要。BigBird 提供了对长文本的支持,使得模型能够处理远超传统 Transformer 长度限制的输入;而 Pegasus 的 GSG 预训练目标则进一步优化了摘要生成任务的效果。这种结合使得 BigBird-Pegasus 在长文本摘要任务中具有无可比拟的优势。
实验结果显示,在 ArXiv、PubMed 和 BigPatent 等长文本数据集上,BigBird-Pegasus 达到了 State-of-the-art 的效果。其 ROUGE 分数显著高于其他同类模型,生成的摘要内容在覆盖率、准确性和语言流畅性上均达到了新的高度。对于一篇包含复杂结构和专业术语的学术论文,BigBird-Pegasus 能够准确提取关键信息并生成清晰易读的摘要,从而提升阅读文章的效率。
性能表现
对于 Arxiv、PubMed 和 BigPatent 这三个文本摘要数据集,BigBird-Pegasus 的 ROUGE 分数要明显优于其他模型,提升效果显著,完整对比结果如下所示:
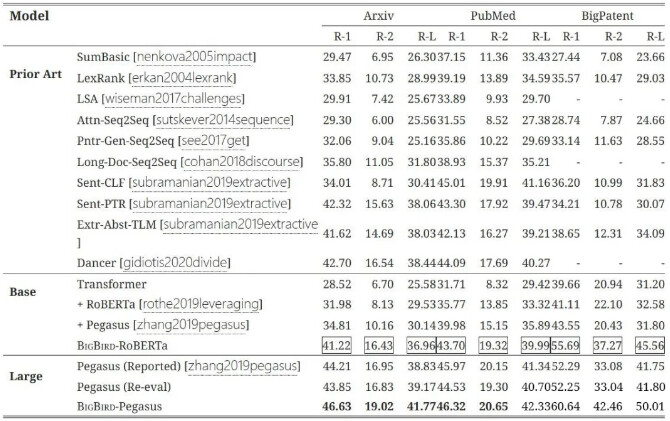
性能表现
# 04
使用MindSpore NLP进行****模型评估
为了验证 BigBird-Pegasus 的实际效果,本文利用 MindSpore NLP 工具进行模型的实现与测评。安装 MindSpore NLP 并下载预训练的 BigBird-Pegasus 权重,选取 ArXiv、PubMed 和 Big Patent 长文本数据集,将文本预处理为适合模型输入的格式,用 BigBird-Pegasus 进行摘要生成,并计算 ROUGE 分数。
实现代码如下:
import numpy as np
import tqdm
from datasets import load_dataset
from mindnlp.transformers import (
PegasusTokenizer,
BigBirdPegasusForConditionalGeneration,
AutoTokenizer
)
from rouge_score import rouge_scorer
tokenizer = AutoTokenizer.from_pretrained("google/bigbird-pegasus-large-pubmed")
model = BigBirdPegasusForConditionalGeneration.from_pretrained("google/bigbird-pegasus-large-pubmed")
def load_model_and_tokenizer(model_name):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = BigBirdPegasusForConditionalGeneration.from_pretrained(model_name)
return model, tokenizer
def evaluate_summarization(dataset, model, tokenizer):
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
rouge_scores = []
for i, example in tqdm.tqdm(enumerate(dataset)):
if 'article' in example:
input_text = example['article']
reference = example['abstract']
elif 'description' in example:
input_text = example['description']
reference = example['abstract']
inputs = tokenizer([input_text], return_tensors="ms", max_length=3072, truncation=True)
summary_ids = model.generate(inputs["input_ids"])
predicted = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
scores = scorer.score(reference, predicted)
rouge_scores.append({
'rouge1': scores['rouge1'].fmeasure,
'rouge2': scores['rouge2'].fmeasure,
'rougeL': scores['rougeL'].fmeasure
})
avg_scores = {
metric: np.mean([score[metric] for score in rouge_scores])
for metric in ['rouge1', 'rouge2', 'rougeL']
}
return avg_scores
def main():
datasets_and_models = {
'arxiv': {
'model': 'google/bigbird-pegasus-large-arxiv',
'dataset': 'ccdv/arxiv-summarization',
},
'pubmed': {
'model': 'google/bigbird-pegasus-large-pubmed',
'dataset': 'ccdv/pubmed-summarization',
},
'bigpatent': {
'model': 'google/bigbird-pegasus-large-bigpatent',
'dataset': 'big_patent',
}
}
for dataset_name, config in datasets_and_models.items():
print(f"\n评估数据集: {dataset_name}")
model, tokenizer = load_model_and_tokenizer(config['model'])
test_dataset = load_dataset(config['dataset'],
split='test')
scores = evaluate_summarization(test_dataset, model, tokenizer)
print(f"数据集: {dataset_name}")
print(f"ROUGE-1: {scores['rouge1']:.4f}")
print(f"ROUGE-2: {scores['rouge2']:.4f}")
print(f"ROUGE-L: {scores['rougeL']:.4f}")
if __name__ == "__main__":
main()
代码仓链接:https://github.com/mindspore-lab/mindnlp/blob/master/docs/en/api/transformers/models/pegasus.md
推理结果
基于 MindSpore NLP 框架,在 ArXiv、PubMed 和 Big Patent 长文本数据集上使用 BigBird-Pegasus 预训练模型进行推理,计算平均 ROUGE 得分,结果汇总如下表所示:

由于笔者只选取了小部分数据进行推理,因此推理得到的结果与官方论文有出入,有兴趣的读者可以对全量数据集自行进行推理验证。
在模型推理阶段,可以发现 BigBird-Pegasus 在生成速度和摘要质量上效果显著。传统模型可能在长文本任务中面临信息丢失或生成质量下降的问题,而 BigBird-Pegasus 的稀疏注意力机制和 GSG 预训练目标确保了生成结果的完整性和准确性,从而在长文本摘要任务中表现优异。
# 05
总结
BigBird-Pegasus 模型的出现标志着 NLP 技术向前迈进了一大步,为长文本处理和文本生成任务提供了高效并且优雅的解决方案。它不仅解决了长文本处理的技术难题,还为文本生成任务提供了新思路。有时候完美并不一定是最好的选择,恰到好处的简化反而能带来更好的效果。
对于想要入门长序列处理研究的同学,我的建议是,首先深入理解原论文中的理论证明,Google团队在论文中的理论部分写得还是较为严谨详细的;另外可以尝试使用 MindSpore NLP 框架进行实践,MindSpore NLP 框架成熟度高,并且官方提供了大量详细的入门文档,建议从简单任务开始,尝试跑跑官方代码,逐步学习更复杂的模型算法。