在计算机视觉领域,预训练模型(如在ImageNet上训练的卷积神经网络)已经成为下游任务迁移学习的标准做法。然而,随着数据集规模和模型复杂度的增加,如何高效地利用大规模数据预训练模型,并在小规模或多样化的下游任务中实现高效迁移,成为一个亟待解决的问题。
《Big Transfer(BiT): General Visual Representation Learning》是在2019年由 Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai 等人提出的一种简单而高效的预训练方法,通过在大规模数据集上训练大型模型(Big Models),并结合迁移学习技巧(Transfer Techniques),显著提升下游任务的表现,同时保持方法的通用性和易用性。BiT的核心思想是规模为王:更大的模型和更大的数据集能够学习到更通用的视觉表征,而不需要复杂的训练策略或任务特定的调整。这种方法与当时流行的复杂预训练方法(如自监督学习或多任务学习)形成对比,强调简单性和可扩展性。
# 01
论文创新点
1、大规模预训练的简单框架
BiT提出了一种基于监督学习的预训练方法,利用大规模数据集(如ImageNet-21k和JFT-300M)和大型模型(如ResNet变体),通过标准的分类任务学习通用视觉表征。这种方法与复杂的自监督学习方法(如SimCLR、MoCo)形成鲜明对比。BiT仅依赖监督信号,却依然取得了卓越的性能,证明了在大规模数据场景下,简单的监督学习依然可以实现强大的表征能力。
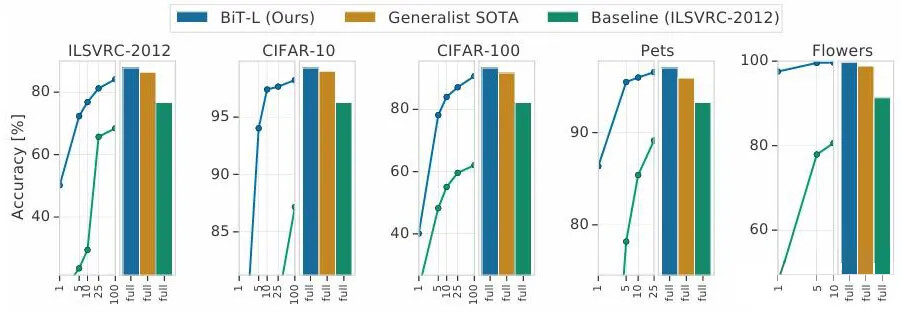
2、模型规模与数据规模的协同效应
论文验证了模型规模(如ResNet-152x4)和数据集规模(如JFT-300M,3亿图像)的协同作用能够显著提升表征能力。BiT表明,单纯增加数据或模型规模可能不足以优化性能,二者需同步扩展以实现最佳效果。这种“双重扩展”的策略弥补了对复杂训练技巧的需求。
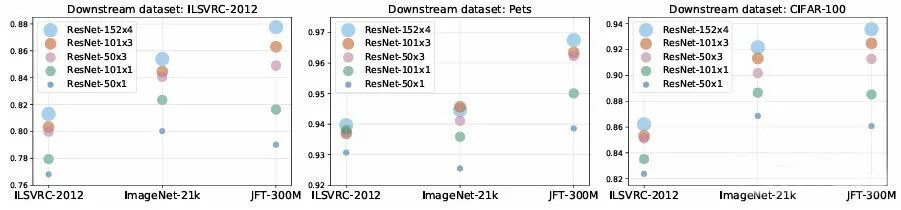
3、 标准化迁移学习协议(BiT-HyperRule)
BiT提出了一套简单高效的迁移学习规则(BiT-HyperRule),包括微调策略和超参数选择指南,避免了为每个下游任务进行昂贵的超参数搜索。该规则根据任务的图像分辨率和数据量动态调整关键超参数(如学习率、训练步数、分辨率),使迁移过程标准化且易于实施。
4、对小数据集的高效迁移
BiT在大规模预训练后,即使在极小数据量的下游任务(如每个类别仅1-10张图像)上也能表现出色,解决了传统预训练模型在小数据集上易过拟合的问题。这种能力在数据稀缺场景(如医疗影像、特定领域分类)中具有重要应用价值。
5、去除了不必要的复杂性
BiT避免使用当时流行的正则化技术(如Dropout、Mixup)或复杂损失函数,证明了简单的预训练+微调流程足以应对多样化的视觉任务。通过精心选择少量关键组件(如Group Normalization和Weight Standardization),BiT在保持简单性的同时实现了高性能。
# 02
方法细节
BiT的实现分为两个主要阶段:上游预训练(Upstream Pre-Training)和下游迁移学习(Transfer to Downstream Tasks)。
1、 预训练阶段
BiT 基于 ResNet 架构,提出了三种不同规模的变体,以适应不同计算资源和任务需求:
BiT-S: 小型模型,例如 ResNet-50x1,训练于 ILSVRC-2012 数据集,包含约 130 万张图像。
BiT-M: 中型模型,例如 ResNet-101x1,训练于 ImageNet-21k 数据集,包含约 1400 万张图像。
BiT-L: 大型模型,例如 ResNet-152x4(宽度乘以 4 倍),训练于 JFT-300M 数据集,包含约 3 亿张图像。
这些模型的深度和宽度逐渐增加,以充分利用大规模数据集的潜力。
BiT 使用了三个不同规模的数据集进行预训练:
ILSVRC-2012: 包含 1000 类,约 130 万张图像,作为基准数据集。
ImageNet-21k: 包含 2.1 万类,约 1400 万张图像,数据量更大且类别更丰富。
JFT-300M: 谷歌内部数据集,包含 3 亿张图像和 1.8 万类,带有噪声标签,是超大规模数据的代表。
2、 迁移学习阶段
微调策略:将预训练模型的卷积层(特征提取器)迁移到下游任务,仅替换最后一层全连接层以适应目标任务的类别数。冻结卷积层权重,仅训练全连接层(适用于小数据集)。对于大数据集,则对整个模型进行端到端微调。
BiT-HyperRule:BiT 提出了一套简单的迁移学习规则(BiT-HyperRule),包括预训练后的微调策略和超参数选择指南:仅使用基本的翻转和裁剪,不依赖复杂增强(如 Mixup)。小于96 × 96的分辨率,先将图片resize到160 × 160 ,再随机剪切出128 × 128的方框;对于大于96 × 96 的分辨率,先将图片resize到512 × 512 ,再随机剪切出480 × 480 的方框。根据任务数据量动态调整,小数据集使用较小的学习率(如 0.003),大数据集使用较大的学习率(如 0.01)。小数据集训练较短(如 500 步),大数据集训练较长(如 20 个 epoch)。移除 Dropout 等技巧,仅依赖 L2 正则化。
# 03
实验结果与分析
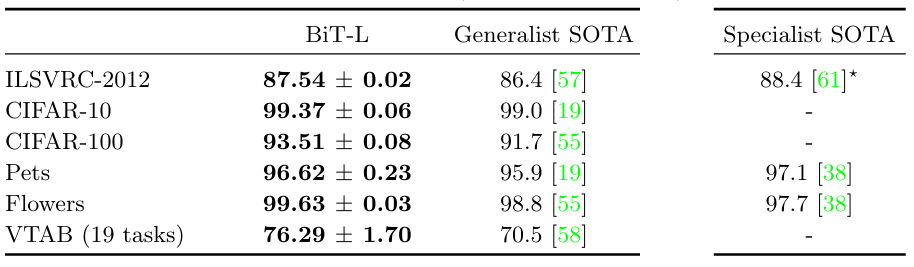
1、 单一模型与单一超参数设置的迁移性能
BiT 的核心思想是通过大规模预训练和简单的迁移学习策略,在多种下游任务上实现卓越的性能。BiT-L 模型在多个数据集上使用单一模型架构和每个任务的单一超参数设置(BiT-HyperRule)进行微调,取得了显著的成果。这些结果不仅超越了当时的通用 SOTA(State-of-the-Art)模型,还在许多情况下优于专门针对特定任务训练的专家模型。
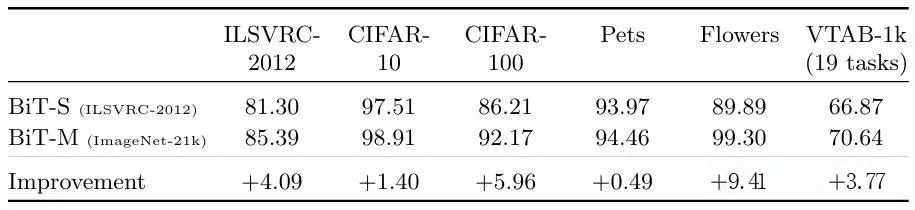
2、 在 ImageNet-21k 上的预训练改进
BiT还展示了在公共 ImageNet-21k 数据集上进行预训练的优势。与传统的 ILSVRC-2012 数据集相比,ImageNet-21k 的规模更大,包含约 1400 万张图像和 2.1 万个类别。BiT 在 ImageNet-21k 上的预训练显著提高了模型的性能。
3、在物体检测任务中的应用
BiT 的迁移学习策略不仅限于图像分类任务,还在物体检测领域取得了显著成果。在 COCO-2017 数据集上,BiT 作为 RetinaNet 检测器的主干网络,进行了微调。结果显示,BiT 模型在物体检测任务上的表现优于标准的 ImageNet 预训练模型。

# 04
创新点优势分析
1、 大规模预训练的高效性
BiT 在大规模数据集(如 ImageNet-21k 和 JFT-300M)上进行预训练,显著提升了模型的泛化能力和性能。这种大规模预训练不仅优于传统的 ILSVRC-2012 数据集,还在下游任务的少样本学习和小数据集任务中表现出色。例如,BiT-L 在 ILSVRC-2012 上达到了 87.5% 的 top-1 准确率,而在 CIFAR-10 上,即使每个类别只有 10 个样本 ,也能达到 97.0% 的准确率。这种能力使得 BiT 在标注数据稀缺的任务中具有显著优势。
2、 简化的迁移学习策略
BiT 提出了 BiT-HyperRule,这是一种简化的超参数调整策略,避免了对每个新任务进行繁琐的超参数搜索。BiT-HyperRule 根据任务的图像分辨率和数据点数量动态调整超参数,包括学习率、训练计划长度和是否使用 MixUp 正则化。这种策略不仅提高了迁移学习的效率,还确保了模型在不同任务上的高性能,减少了手动调参的工作量。
3、 广泛的适用性和高性能
BiT 在多种数据规模和复杂度的任务上表现出色,从每个类别只有 1 个样本 的小数据集到包含 数百万样本 的大数据集。例如,在 19 项任务的视觉任务适应基准(VTAB)上,BiT 的平均准确率达到了 76.3% 。此外,BiT 在物体检测任务中也表现出色,使用 BiT-L 预训练的 RetinaNet 在 COCO-2017 验证集上达到了 43.8% 的平均精度(AP),显著优于使用 ILSVRC-2012 预训练的模型。
BiT 通过大规模预训练和简化的迁移学习策略,显著提升了模型的泛化能力和适用性。其在少样本学习和小数据集任务中的卓越表现,使其在标注数据稀缺的任务中具有重要应用价值。BiT 的创新点不仅在于大规模数据集的预训练,还在于通过 BiT-HyperRule 自动化超参数调整,显著提升了迁移学习的效率和适用性。
# 05
使用MindSpore NLP进行****模型评估
实现代码如下:
import argparse
import os
from tqdm import tqdm
import numpy as np
import mindspore
from mindspore import nn, ops, Tensor
from datasets import load_dataset
from mindnlp.transformers import BitForImageClassification, BitConfig
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com '
def parse_arguments():
parser = argparse.ArgumentParser(description="MindNLP BiT 评估示例")
parser.add_argument("--model_name", type=str, default="google/bit-50", help="模型名称")
parser.add_argument("--dataset_name", type=str, default="cifar10", help="数据集名称")
parser.add_argument("--batch_size", type=int, default=8, help="批次大小")
return parser.parse_args()
def load_data(dataset_name, batch_size):
dataset = load_dataset(dataset_name, split='test')
def preprocess(batch):
images = np.stack([np.array(img) for img in batch['img']]) / 255.0
images = images.transpose(0, 3, 1, 2)
labels = np.array(batch['label'])
return {"images": images, "labels": labels}
# 应用预处理并批处理数据集
dataset = dataset.map(preprocess, batched=True)
dataset = dataset.batch(batch_size)
return dataset
def main():
args = parse_arguments()
dataset = load_data(args.dataset_name, args.batch_size)
# 初始化 BiT 配置
config = BitConfig.from_pretrained(args.model_name, num_labels=10)
# 初始化模型
model = BitForImageClassification.from_pretrained(
args.model_name, config=config, ignore_mismatched_sizes=True
)
# 评估模式
try:
model.eval()
print("Model switched to evaluation mode successfully.")
except AttributeError:
print("Warning: Model does not support eval(). Proceeding without mode switch.")
# 定义损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义评估步骤
def eval_step(model, images, labels):
# 数组转换
images = Tensor(images, dtype=mindspore.float32)
labels = Tensor(labels, dtype=mindspore.int32)
outputs = model(images)
logits = outputs.logits
preds = ops.argmax(logits, dim=1)
# 计算损失
loss = loss_fn(logits, labels)
# 计算准确率
equals = ops.cast(ops.equal(preds, labels), mindspore.float32)
accuracy = ops.reduce_mean(equals)
return loss, accuracy
# 评估模型
total_loss = 0.0
total_accuracy = 0.0
num_batches = 0
for batch in tqdm(dataset, desc="评估中"):
if isinstance(batch, dict):
images, labels = batch['images'], batch['labels']
else:
raise ValueError("Batch is not in expected dictionary format")
loss, accuracy = eval_step(model, images, labels)
total_loss += loss.asnumpy()
total_accuracy += accuracy.asnumpy()
num_batches += 1
avg_loss = total_loss / num_batches
avg_accuracy = total_accuracy / num_batches
print(f"平均损失: {avg_loss}")
print(f"测试准确率: {avg_accuracy}")
if __name__ == "__main__":
main()
论文在该模型测试都应用于下游微调后的任务,这里仅比较预训练模型的loss值,选用cifar10数据集:
推理结果
基于 MindSpore NLP 框架,在 ArXiv、PubMed 和 Big Patent 长文本数据集上使用 BigBird-Pegasus 预训练模型进行推理,计算平均 ROUGE 得分,结果汇总如下表所示:
| 模型实现 | loss值(cifar10) |
|---|---|
| BiT(MindSpore NLP) | 3.342 |
| BiT(Transformers) | 3.390 |
可以看出MindSpore NLP框架实现性能和Transformer实现相近。使用MindSpore NLP可以帮助我们更方便快捷地构建和训练模型,也推荐大家对BiT模型进行微调和推理验证。
# 06
总结
BiT 通过大规模预训练和简化的迁移学习策略,显著提升了模型的泛化能力和适用性。其在少样本学习和小数据集任务中的卓越表现,使其在标注数据稀缺的任务中具有重要应用价值。BiT 的创新点不仅在于大规模数据集的预训练,还在于通过 BiT-HyperRule 自动化超参数调整,显著提升了迁移学习的效率和适用性。