昇思MindSpore开源实习模型论文解读任务已顺利完成,共收到模型论文解读稿件10+篇。欢迎开发者积极参与昇思MindSpore开源实习活动,开源实习暑期活动已开启,更多新任务等你来挑战!
开源实习官网
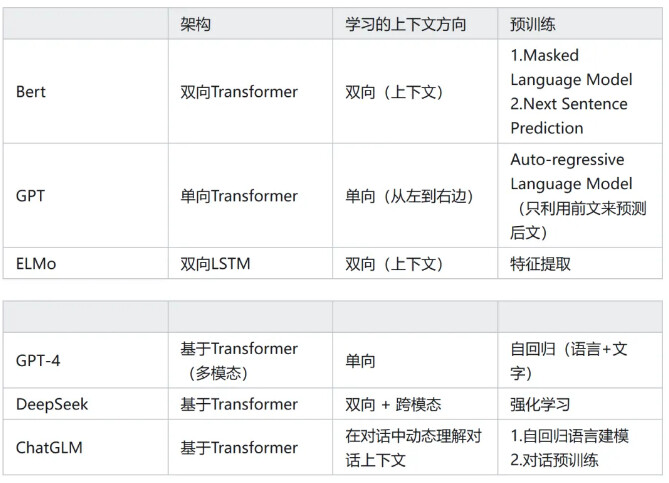
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的自然语言处理(NLP)模型,由 Google 于2018年提出论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
(https://arxiv.org/abs/1810.04805)
在NLP领域应用预训练和微调前计算机视觉方向已经广泛采用这种方式BERT的提出 将NLP的结合了预训练和微调带到了一个新的领域。
下面开始对该模型进行解读。
# 01
架构
BERT 是由多层 Transformer 编码器Encoder 堆叠而成。
它分为以下两种:
- BERT-base:12 层 Encoder,隐藏层维度为 768,注意力头数为 12。
- BERT-large:24 层 Encoder,隐藏层维度为 1024,注意力头数为 16。
I am eating a banana 经过bert编码器编码的句子类似**[CLS]I am eating a banana[SEP] [PAD] [PAD]**
前[CLS]表示可以用于下游任务,后[SEP]表示句子的结束[PAD]用于填充防止句子长度不同。
# 02
模型的创新点:
1、 BERT 通过 遮蔽语言模型(MLM) 任务
利用双向上下文来训练模型。在训练时,它随机遮蔽输入中的一些单词(利用[mask]遮蔽句子中的部分信息),然后让模型同时从左边和右边的上下文信息预测这些单词。
其中 80% 替换为 [MASK] ;10% 替换为随机 token;10% 保持不变。
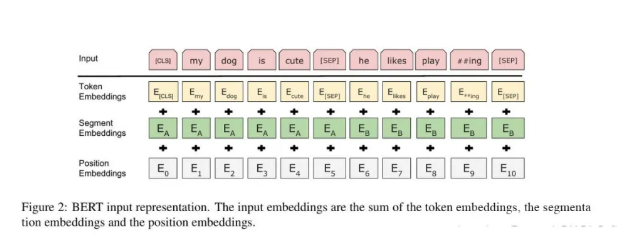
Token Embeddings–>词嵌入
Segment Embeddings—>句子嵌入
Position Embeddings—>位置嵌入(区别于GPT1的正余弦编码)
输入 BERT 之前,每个 token 由 词嵌入、句子嵌入和位置嵌入 组成。它们的 向量相加 后送入 BERT 进行训练或推理。
2、 下一句预测(Next Sentence Prediction, NSP)
传统方法的局限性:忽视了句子之间的关系。
BERT 的创新:BERT 在预训练时引入了 下一句预测(NSP) 任务,该任务帮助模型理解句子之间的逻辑关系。模型被给定两句文本,任务是判断第二句是否为第一句的下文。
3、 BERT 使用了预训练-微调(Pre-training and Fine-tuning)
预训练: 在大规模无标签的语料上进行预训练。
语料:BooksCorpus(Zhu et al., 2015) 和英文维基百科(25亿词只提取文本段落,忽略列表、表格和标题)
通过MLM 和NSP 任务学习语言的通用表示---->好处:能够大大减少对标注数据的依赖
微调: 模型适应下游任务(如文本分类等)。–>好处:提高了模型在多个任务上的性能
# 03
BERT区别于其他模型
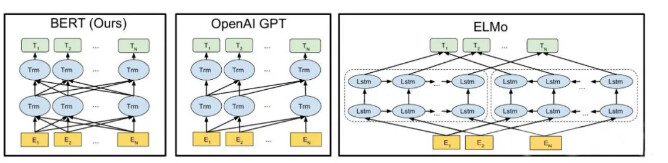
bert和OpenAI GPT以及ELMo的对比
# 04
效果
1、GLUE 测试
BERT 通过 [CLS] 位置的向量 C 进行分类,添加全连接层 W 并使用交叉熵损失进行微调。
效果:BERTLARGE 比 SOTA 提高 7.0% 平均准确率。MNLI 任务提升 4.6% 绝对准确率。BERTLARGE 在小数据集表现更优。
- 超参数Batch size = 32,Fine-tune 3 epochs,学习率 5e-5, 4e-5, 3e-5, 2e-5。
2、SQuAD任务
采用 [CLS] 预测无答案,两个向量 S 和 E 预测答案起止位置。
SQuAD v1.1: BERTLARGE (单模型) F1 = 90.9% ,超越 SOTA。集成模型提升至 F1 = 92.2% 。
SQuAD v2.0:F1 提高 5.1 ,无答案处理能力增强。
3、SWAG 任务
4 个候选句,每个与 sentence A 组成输入,[CLS] 位置表示选择最佳答案。
BERTLARGE比OpenAIGPT 高 8.3% ,比ELMo提升 27.1% 。
# 05
总结
- 去掉 NSP–>对问答任务影响大。
- 采用左到右语言模型(LTR)表现下降,说明 BERT 的 双向性 关键。
# 06
实操
1、Mindspore仓进行基于bert的情感分类预测步骤
相关代码已上传到昇思代码仓:https://github.com/mindspore-lab/mindnlp/tree/master/applications/bert
参考:基于MindSpore的bert模型实验指导书(AI Gallery_Notebook详情_开发者_华为云
步骤:
1.安装MindSpore框架和MindSpore NLP套件;
2.用bert分词库进行分词;
3.进行模型的训练和推理。
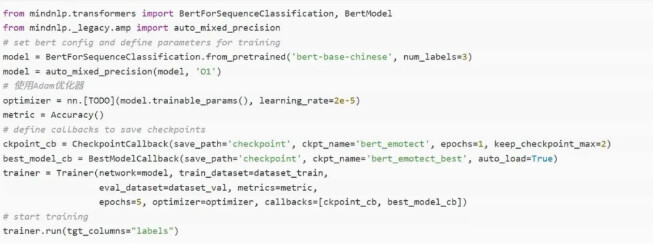
2、pytorch中用于文本分类的示例

情感分类验证集性能
