原论文名为《利用预训练检查点进行序列生成任务》,主要探讨了如何将预训练检查点 应用于序列生成任务(seq2seq),特别是在自然语言处理(NLP)中的机器翻译、文本摘要、句子拆分 和句子融合 等任务上。作者提出了一种基于 Transformer 架构的 序列到序列模型 ,并通过广泛的实验验证了预训练模型在这些任务中的有效性。实验结果显示,与随机初始化的模型相比,利用预训练模型显著改善了性能,尤其是在机器翻译、文本摘要、句子拆分和句子融合任务上。预训练编码器被认为是序列生成任务的重要组成部分,并且编码器与解码器之间的权重共享也能带来更好的效果。
近年来,无监督预训练大型神经网络模型(如 BERT、GPT-2 和 RoBERTa)显著提高了许多自然语言理解任务的性能。通过使用公开发布的预训练检查点,研究人员能够通过热启动(warm-starting)节省大量计算资源并推动多项基准任务的进展。然而,这些预训练模型大多应用于自然语言理解任务,较少研究其在序列生成任务中的应用。
# 01
论文研究方法:
1、基于 Transformer 的序列到序列模型
作者提出了一种基于 Transformer 的序列到序列(seq2seq)模型 ,该模型能够兼容BERT、GPT-2 和 RoBERTa 的预训练检查点。通过使用这些预训练模型的编码器和解码器,模型能够显著提高性能。
2、探索了多种encoder-decoder初始化的组合
所有权重均随机初始化的组合架构。编码器和解码器之间的参数共享的组合。随机初始化的编码器与一个基于 BERT初始化的解码器的组合等。
3、应用到多种seq2seq任务
探索了在句子融合、句子拆分、机器翻译和文本摘要任务中的效果,并与从头训练的随机初始化模型进行了比较。
4、研究不同的初始化策略和配置对模型性能的影响:
组合不同的预训练检查点,仅初始化嵌入层,初始化部分层。
# 02
论文创新点
1、将预训练模型扩展至序列生成任务,**而不仅仅是传统的自然语言理解任务。这一进展大大扩展了大型预训练模型的应用场景,并为其他 NLP 任务提供了新的方法。
2、基于 Transformer 的序列到序列模型架构,**并结合了流行的预训练模型。这种兼容性使得利用预训练模型进行编码和解码成为可能,从而显著提升了序列生成任务的性能。
3、预训练编码器和解码器权重共享的,**这种方法不仅能提高模型性能,还能显著降低模型的内存占用。共享权重的方式在大多数任务中都表现出了良好的效果,尤其在计算资源有限的情况下尤为重要。
# 03
结果
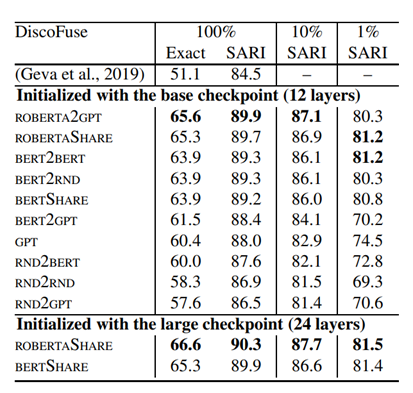
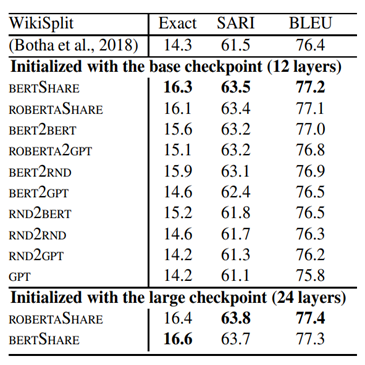
作者试验了多种编码器-解码器组成的transformer模型在句子级融合与拆分任务中的表现。可以看出,不同的组合在不同的数据集上的得分都有所差异。
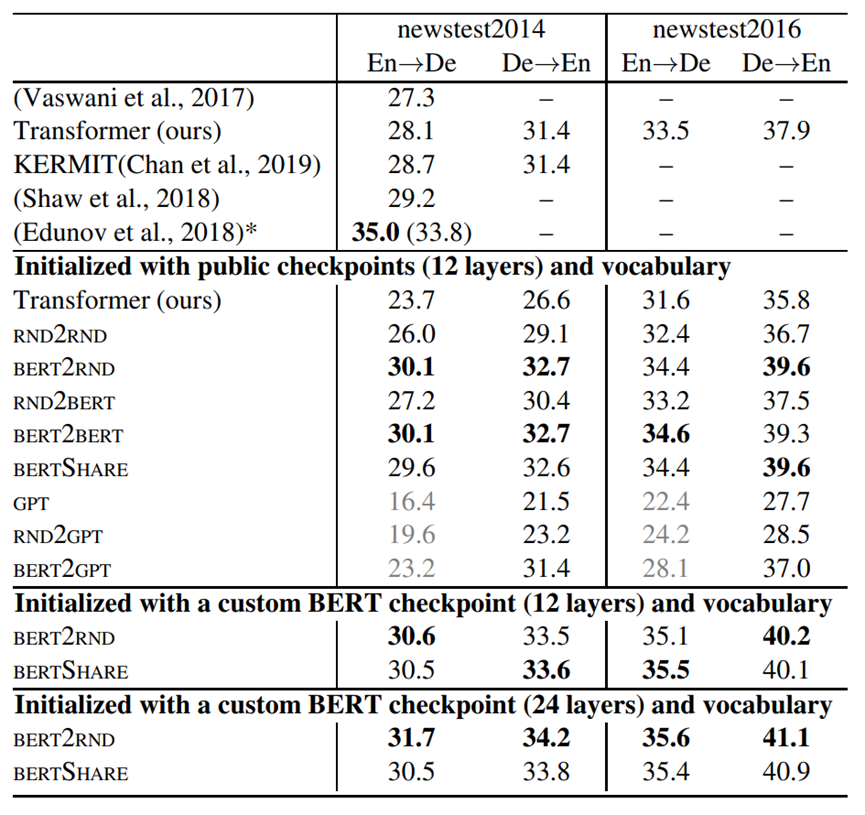
在机器翻译任务中,24层BERT-RND的组合展现出最佳的性能。
# 04
使用MindSpore NLP进行模型评估
加载了预训练的google/bert_for_seq_generation_L-24_bbc_encoder 模型,在BBC数据集的Test集上选取了一条进行了实验,用rouge指标作为评判标准。Test集里一共有1000 samples,受限于设备和实际情况,受限于设备和实际情况,我们挑选一条做展示。
uk coal plunges into deeper loss shares in uk coal have fallen after the mining group reported losses had deepened to £51. 6m in 2004 from £1. 2m. the uk s biggest coal producer blamed geological problems industrial action and operating flaws at its deep mines for its worsening fortunes. the south yorkshire company led by new chief executive gerry spindler said it hoped to return to profit in 2006. in early trade on thursday its shares were down 10 % at 119 pence. uk coal said it was making significant progress in shaking up the business. it had introduced new wage structures a new daily maintenance regime for machinery at its mines and methods to continue mining in adverse conditions. the company said these actions should significantly uplift earnings. it expected2005 to be a transitional year and to return to profitability in 2006. the recent rise in coal prices has failed to benefit the company as most of its output had already been sold it said. total production costs were £1. 30 per gigajoule uk coal said but the average selling price was just £1. 18 per gigajoule. we have a long journey ahead to fix these issues. we continue to make progress and great strides have already been made said mr spindler. uk coal operates 15 deep and surface mines across nottinghamshire derbyshire leicestershire yorkshire the west midlands northumberland and durham. aires aires washington [UNK] revolutionary [UNK] [UNK] robertson und und 新 und [UNK]eta mal aires aires aires aires [UNK]
[{‘rouge-1’: {‘r’: 0.9931506849315068, ‘p’: 0.9294871794871795, ‘f’: 0.9602648956677339},
‘rouge-2’: {‘r’: 0.9908675799086758, ‘p’: 0.9194915254237288, ‘f’: 0.9538461488531337},
‘rouge-l’: {‘r’: 0.9931506849315068, ‘p’: 0.9294871794871795, ‘f’: 0.9602648956677339}}]
完整代码已上传到Github仓库中,您可以通过以下链接查看并运行:
# 05
结论
1、预训练编码器至关重要: 使用预训练编码器显著提高了序列生成任务的性能,尤其是在理解输入文本方面。
2、共享编码器和解码器的权重能够提高性能: 共享编码器和解码器的参数在大多数任务中能够提高性能,并减少内存占用,尤其对于大规模的 NLP 任务更为高效。
3、较大模型的效果更好: 较大的模型相对较小模型有更好的性能,但它们容易在小数据集上过拟合 ,需要谨慎调整。