一、模型推理介绍
大语言模型LLM的推理阶段,是模型在完成训练后,基于输入数据生成预测结果的过程。这一阶段对于模型实际应用至关重要,决定了在对话生成、文本摘要、问答等任务的表现。推理阶段不再更新模型参数,更在于高效、准确地利用已有参数进行预测。
推理主要流程:分词: 输入文本先经过tokenizer分词器转换为数字形式的序列,这些数字就是单词在词典中的索引编号;向量嵌入: 将数字序列通过embedding得到高维度的向量;解码器运算:将这些向量通过解码器进行复杂的推理运算,生成下一个词的数字索引,循环多次运算就能生成整个索引序列;输出: 用tokenizer分词器来还源这些数字序列,得到人类可以理解的自然语言。
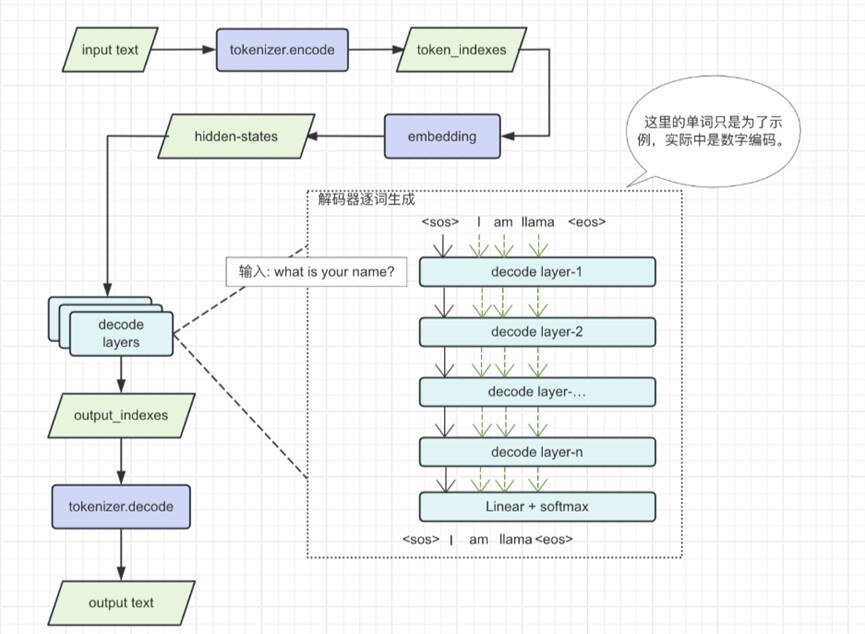
二、编码-解码
Encoder-Decoder是一个模型构架,是一类算法统称,并不是特指某一个具体的算法,在这个框架下可以使用不同的算法来解决不同的任务。首先,编码(encode)由一个编码器将输入序列转化成一个固定维度的稠密向量,解码(decode)阶段将这个激活状态生成目标译文。

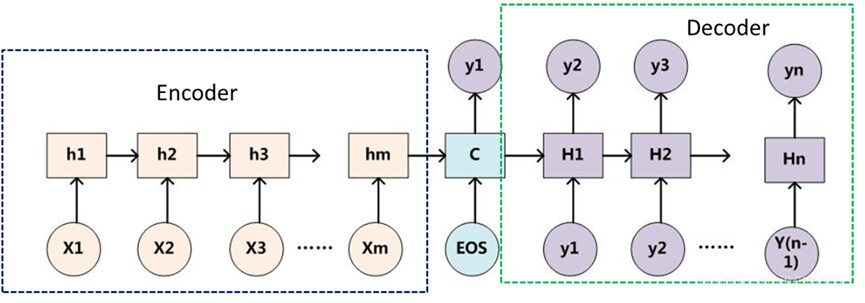
说明:1、不论输入和输出的长度是什么,中间的“向量c”长度都是固定的(这是它的缺陷所在)。2、根据不同的任务可以选择不同的编码器和解码器3、Encoder-Decoder的一个显著特征就是:它是一个end-to-end的学习算法。4、只要符合这种框架结构的模型都可以统称为Encoder-Decoder模型。
三、实操部分:
推理任务1
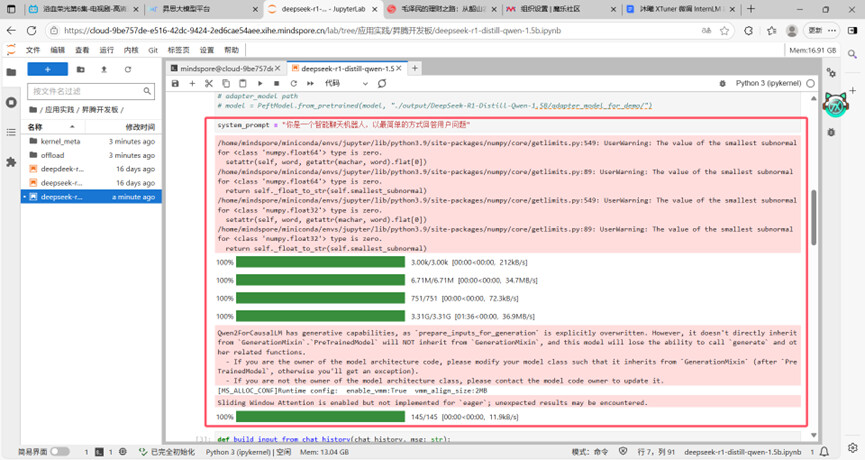
Mindspore和mindnlp对应正确。
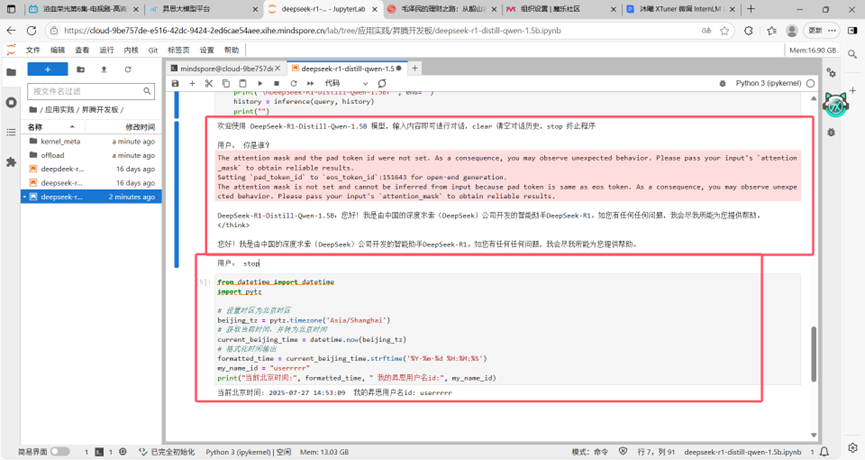
用户提问、回答、结束。
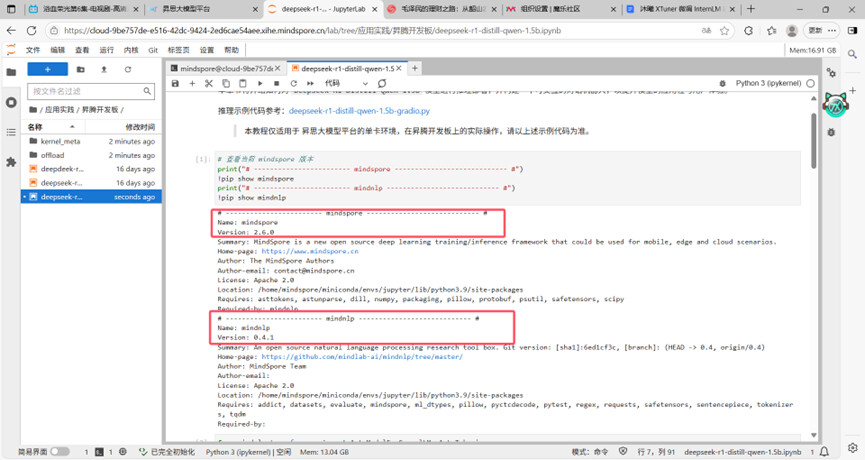
推理任务2
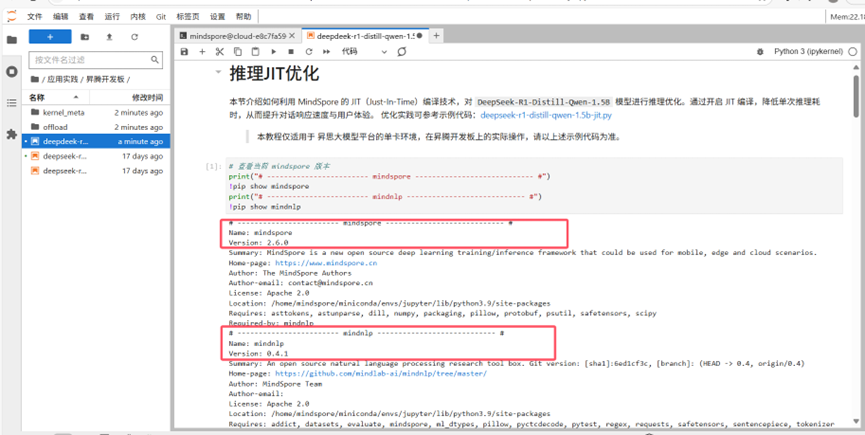
Mindspore和mindnlp对应正确。
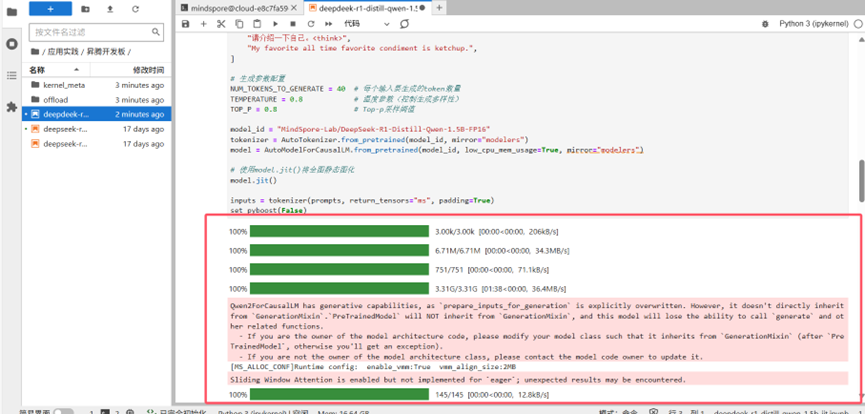
参数配置完成。
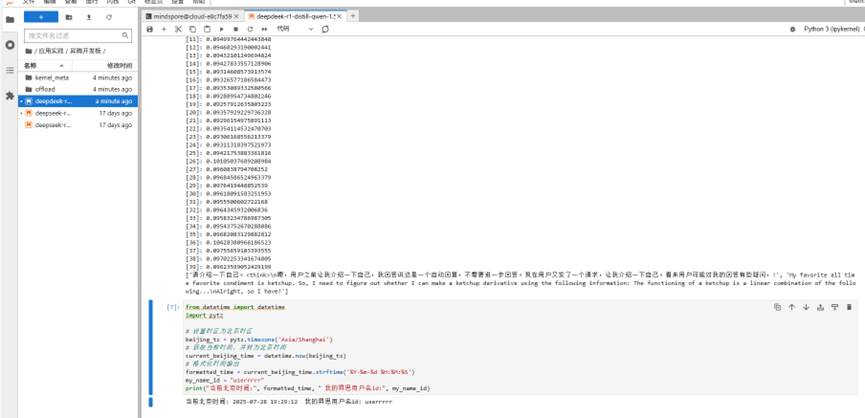
成功输出推理每一步所用的时间、用户名和时间。