LoRA微调介绍

只动少部分的代码达到预期
蓝色部分是base model, 用get_peft_model实现实例化模型
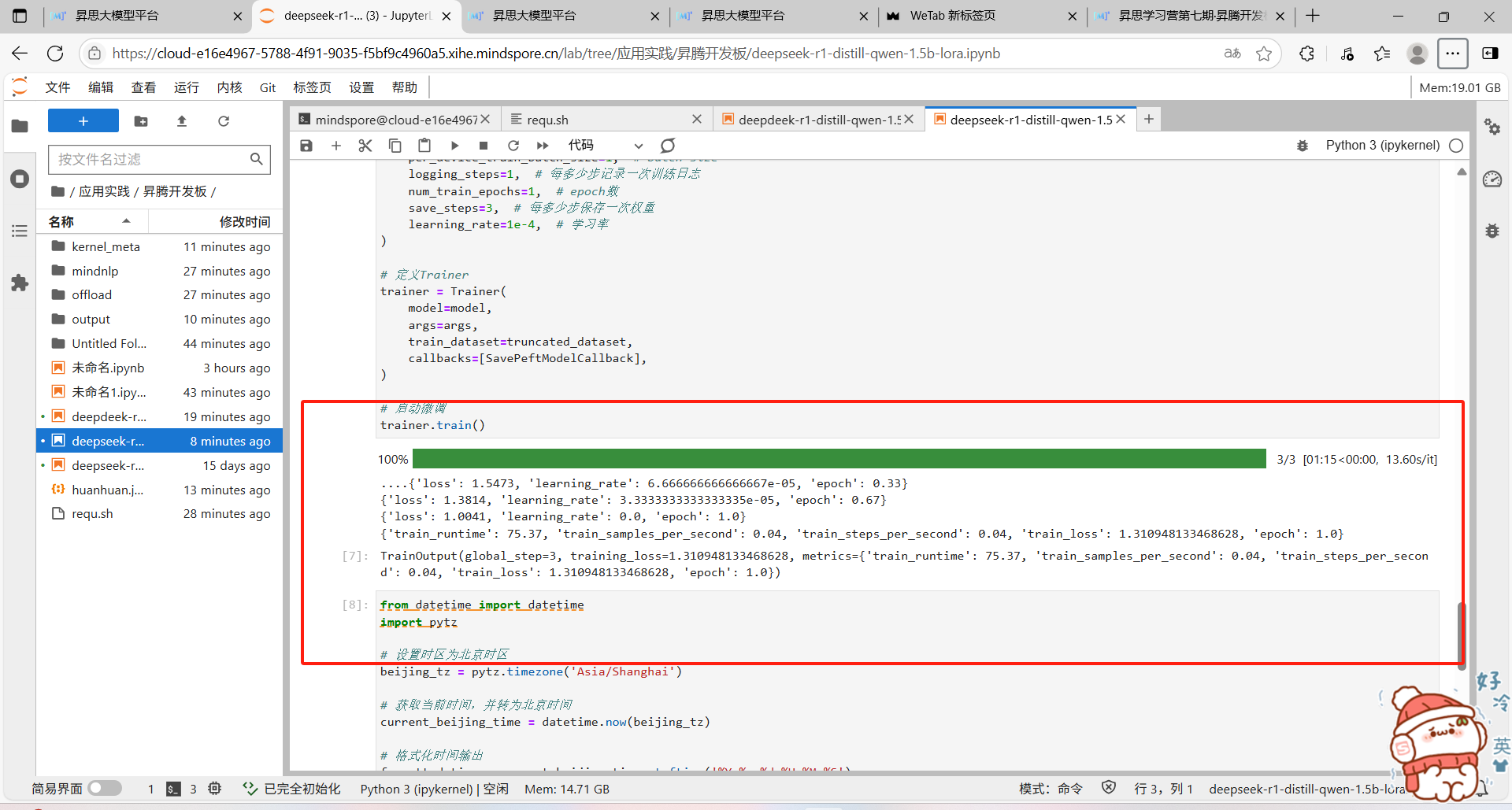
案例演示:本次案例只对少量数据进行微调
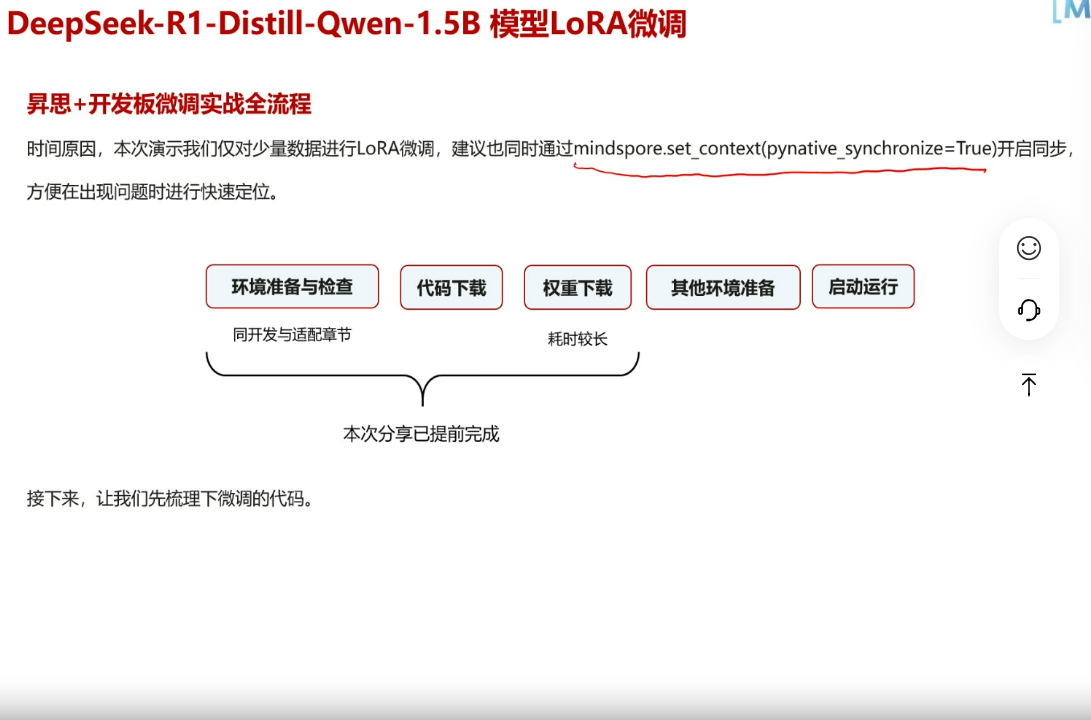
1.开启同步。mindspore.set_context(pynative_synchronize=TRUE),方便问题定位

2.模块分布情况:
1>数据集方面的处理
2>base model ,loRA模型配置和实例化
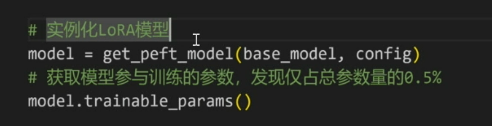
只有adapter参与训练,其他意义不大
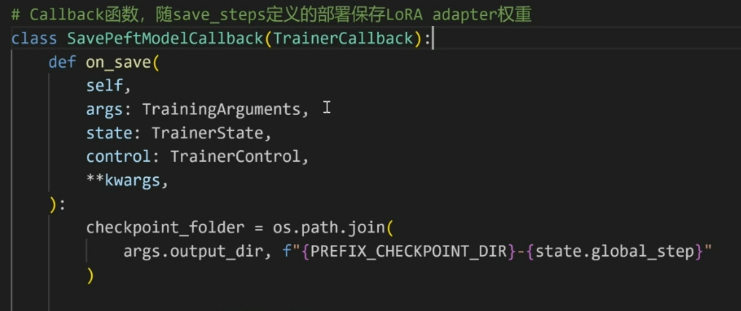
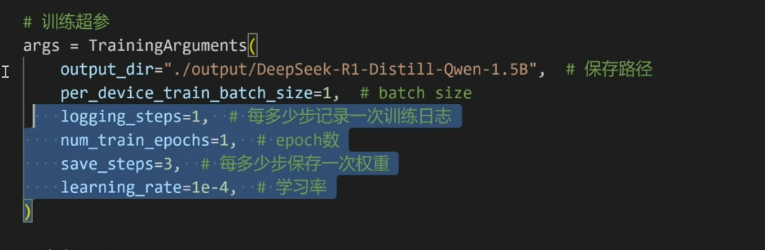
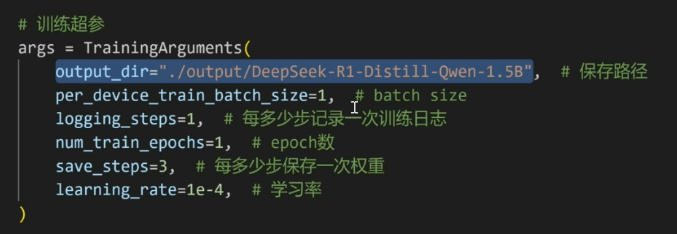
训练超参
最后整合到定义好的Trainer
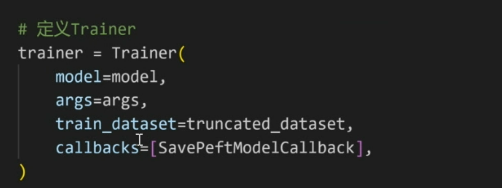
以上就是大致过程
二、对话模型示例
通过tokenizer把对话转化成数字索引

数据的处理逻辑
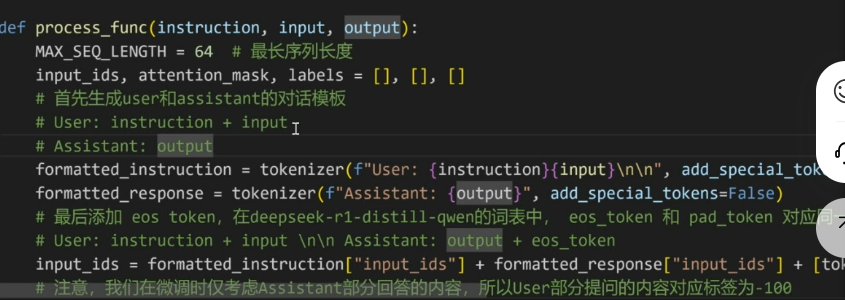
User类似于用户,Assistant则是deepseek的回答,在对话结束后添加eso token用于提示模型对话结束
转化为数字索引后,由于对话格式不一(有长有短),需要对其进行限制
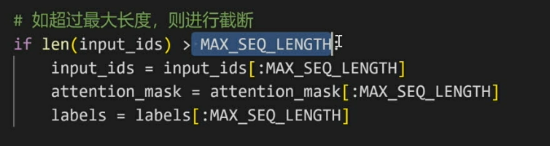

最后返回的三个内容,input_ids:实际对话的内容。attention_mask:attention 的掩码。labels:标签
通过map接口将操作作用在数据集上

map常为operation,input,ouput格式,与对应函数的参数要一致,不然会有乱码。
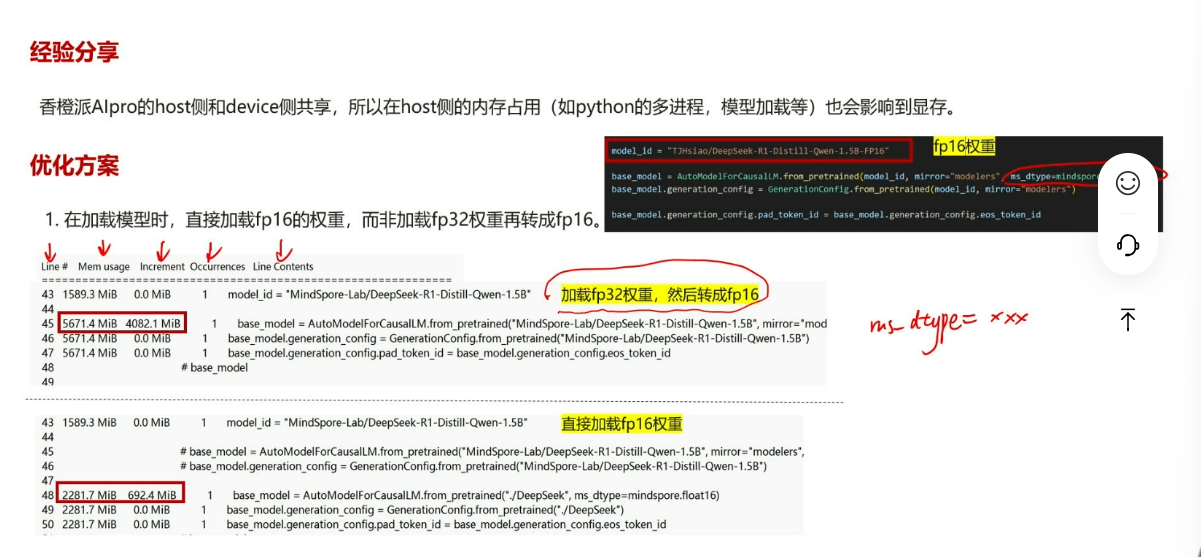
以下为常遇问题的经验分享


三、实训过程
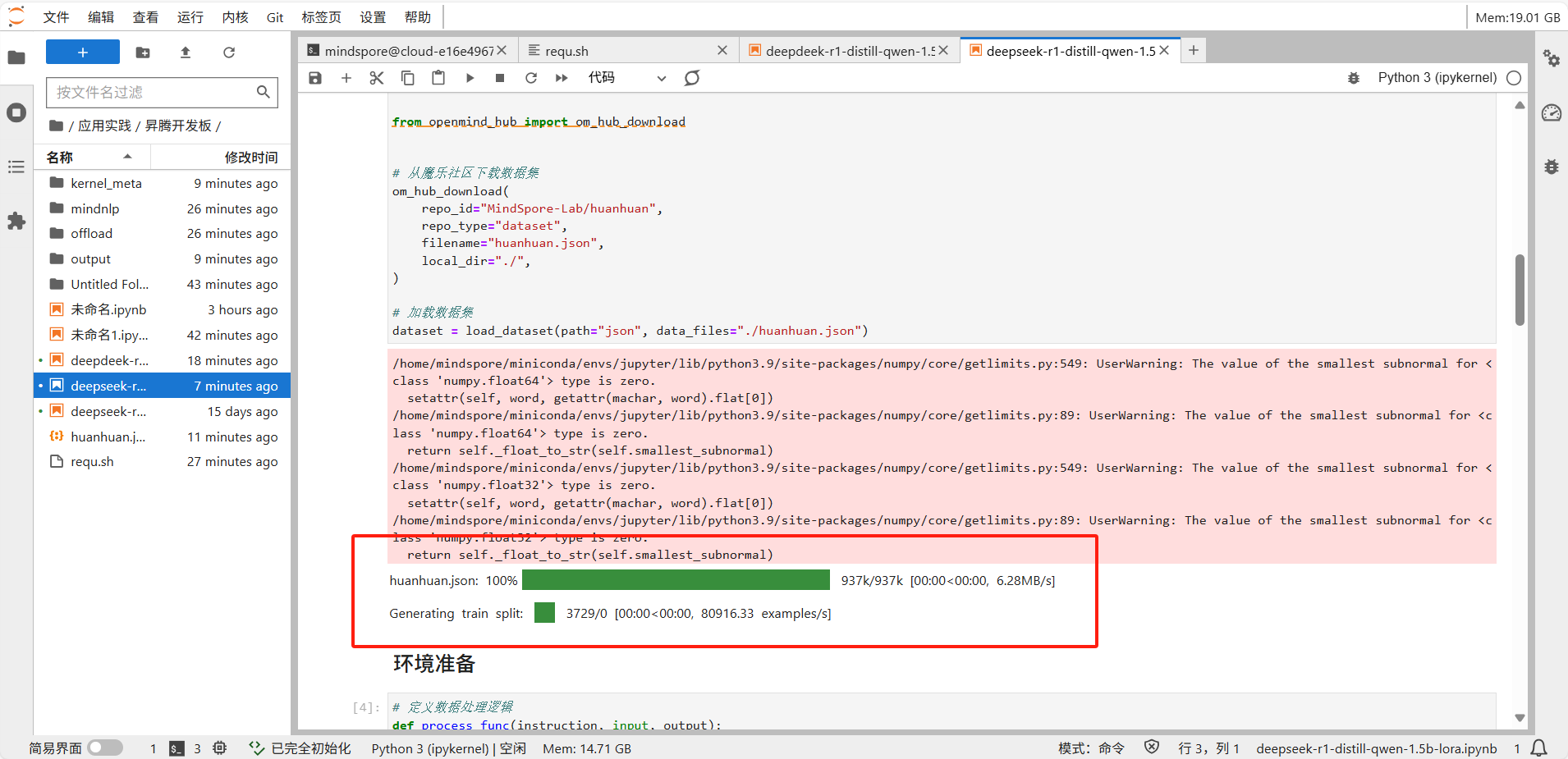
下载模型和数据集:
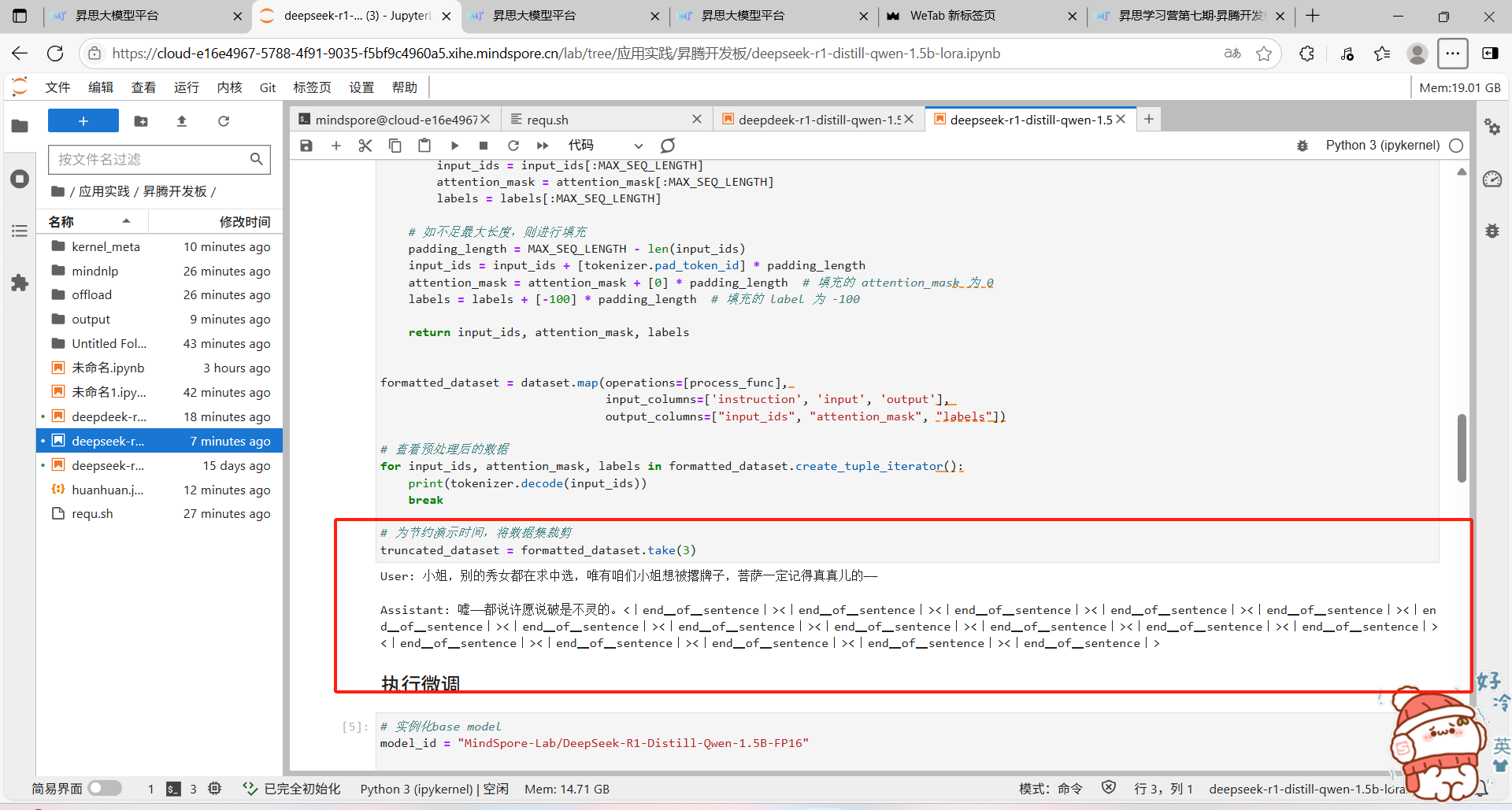
对数据集进行处理:
执行微调: