论文概述:
ALBERT提出了一个轻量化的bert模型,应用参数减少技术,以降低BERT模型的内存消耗并提高训练速度;引入了一种自监督损失函数,专注于句间连贯性,使模型对特定下游任务适应性更高。经过优化的模型在GLUE、RACE和SQuAD基准上取得了比BERT模型更好的结果,同时参数数量大大低于BERT-large。
论文创新点:
该模型的主要创新包括:
-
分解嵌入参数 ALBERT采用了一种分解策略,将词汇嵌入参数分解为两个较小的矩阵。这意味着,词汇的表示不会直接映射到隐层空间,而是通过两个步骤进行变换:第一步,将一维的独热向量(one-hot vector)先投影到一个较小的嵌入空间,维度为E。这是一个较低维度的表示,使得模型的参数数量更少。第二步,将这个低维嵌入投影到隐藏层空间,维度为H。
-
跨层共享参数 共享参数有多种可选择的策略,例如,仅在各层之间共享前馈网络(FFN)参数,或者仅共享注意力参数。ALBERT 的策略是在各层之间共享所有参数。
-
预测句子顺序
不同于BERT中使用的NSP,ALBERT使用句子顺序预测(SOP)损失,放弃了主题预测能力,而专注于对句子间连贯性的建模。
创新点分析:
Albert相较于bert有以下两点优势:
1.参数更少,降本提效。Albert通过分解嵌入参数和共享层参数使得参数量比bert-large少约18倍。显著降低的训练所需时间,提高了模型的效率。
2.更能适应判断句间连贯性相关的任务。Albert使用句子顺序预测(SOP)损失,专注于对句子间连贯性的建模,因此在涉及句子间关系的任务中有更好的表现
数据集上的评价指标得分:

Table 2: Dev set results for models pretrained over BOOKCORPUS and Wikipedia for 125k steps.Here and everywhere else, the Avg column is computed by averaging the scores of the downstreamtasks to its left (the two numbers of F1 and EM for each SQuAD are first averaged).
bert和albert-xxlarge在上图中五个数据集上的得分均高于bert-large,而前者参数量仅为后者的70%左右。
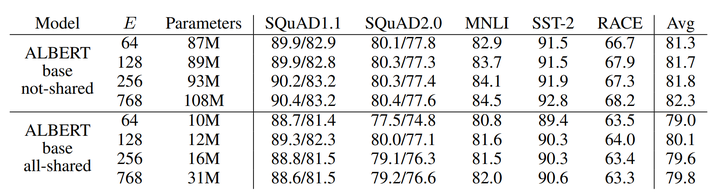
Table 3: The effect of vocabulary embedding size on the performance of ALBERT-base.
对于ALBERT-base模型,嵌入参数分解在显著降低参数数量的情况下,仅降低了大约2.4%的性能。
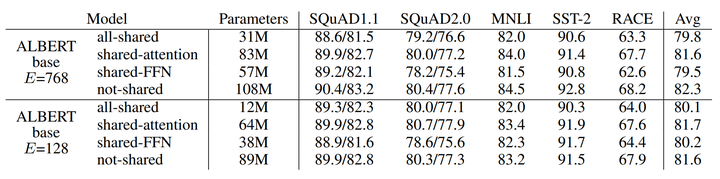
Table 4: The effect of cross-layer parameter-sharing strategies, ALBERT-base configuration.
不同的跨层参数共享策略会对模型性能产生影响,共享所有层的参数可以减少超过一半的参数,仅仅带来不到3%的性能损失。

Table 5: The effect of sentence-prediction loss, NSP vs. SOP, on intrinsic and downstream tasks.
使用SOP在下游任务中展现出比NSP更高的性能
使用MindNLP进行模型评估:
整个过程根据mindnlp官方提供的example和相关功能的使用文档实现。首先加载与原论文一致的GLUE数据集中的文本分类任务sst-2 的Validation部分。
接着为数据集中地id创建标签映射。然后构造一个函数,利用MindSpore数据集将数据包装为可迭代的dataset对象,同时加载封装好的AlbertTokenizer进行分词,变为MindSpore可处理的的dev_dataset。加载在sst-2训练集上微调好的模型,指定labels数为数据集的标签数。
随后构造推理函数,其将模型设置为推理模式,然后开始遍历数据集每个批次。将数据输入模型获取预测logits。最后转换为最终预测标签preds。收集所有预测标签和真实标签,计算以下指标。
-
准确率(accuracy)
-
F1 分数(f1)
-
精确率(precision)
-
召回率(recall)

截取自本项目GitHub 仓库中代码运行结果示例

使用Mindnlp精确复现原论文模型在相同数据集上的结果
完整代码
已经上传到 GitHub 仓库中,您可以通过以下链接访问并运行:
总结:
ALBERT通过分解嵌入参数并共享层参数,打造出一款轻量化的BERT,有效减少了训练成本,同时使用SOP训练模型对于句子间连贯性的学习,在多种下游任务上展现出卓越的性能。
建议各位开发者利用MindNLP等工具来加载并复现该模型。MindNLP提供了一套与PyTorch风格一致的简洁接口,借助MindNLP,开发者可以快速上手并验证模型性能,而不需要重复实现底层细节。此外,MindNLP的文档和示例代码也为用户提供了良好的支持,帮助他们更快地理解和应用相关技术。