BLIP(Bootstrapped Language-Image Pretraining)模型是2022年提出的一种多模态预训练模型,旨在更好地融合视觉和语言信息,提升图像-文本联合学习的效率。通过结合对比学习、图文匹配和生成任务,模型能够更高效地学习图像与文本之间的关系。还在模型训练的过程中,引入了自引导机制,使得模型在训练的过程中,可以自我提升性能。其核心创新包括多模态混合预训练框架、自举式数据增强、多任务联合优化和模态间交互增强。这些设计使BLIP在图像-文本匹配、图像描述生成和视觉问答等任务中表现卓越。BLIP通过生成高质量数据、增强模态交互及多任务协同,显著提升了模型性能,是多模态学习模型领域的里程碑式工作。
论文的创新点
论文的创新点主要体现在以下几个方面:
1.多模态混合预训练框架
BLIP提出了一种统一的预训练框架,同时支持图像-文本匹配、图像-文本检索、图像描述生成和视觉问答(VQA)等多种任务。这种设计避免了传统方法中需要为不同任务设计不同模型的局限性。
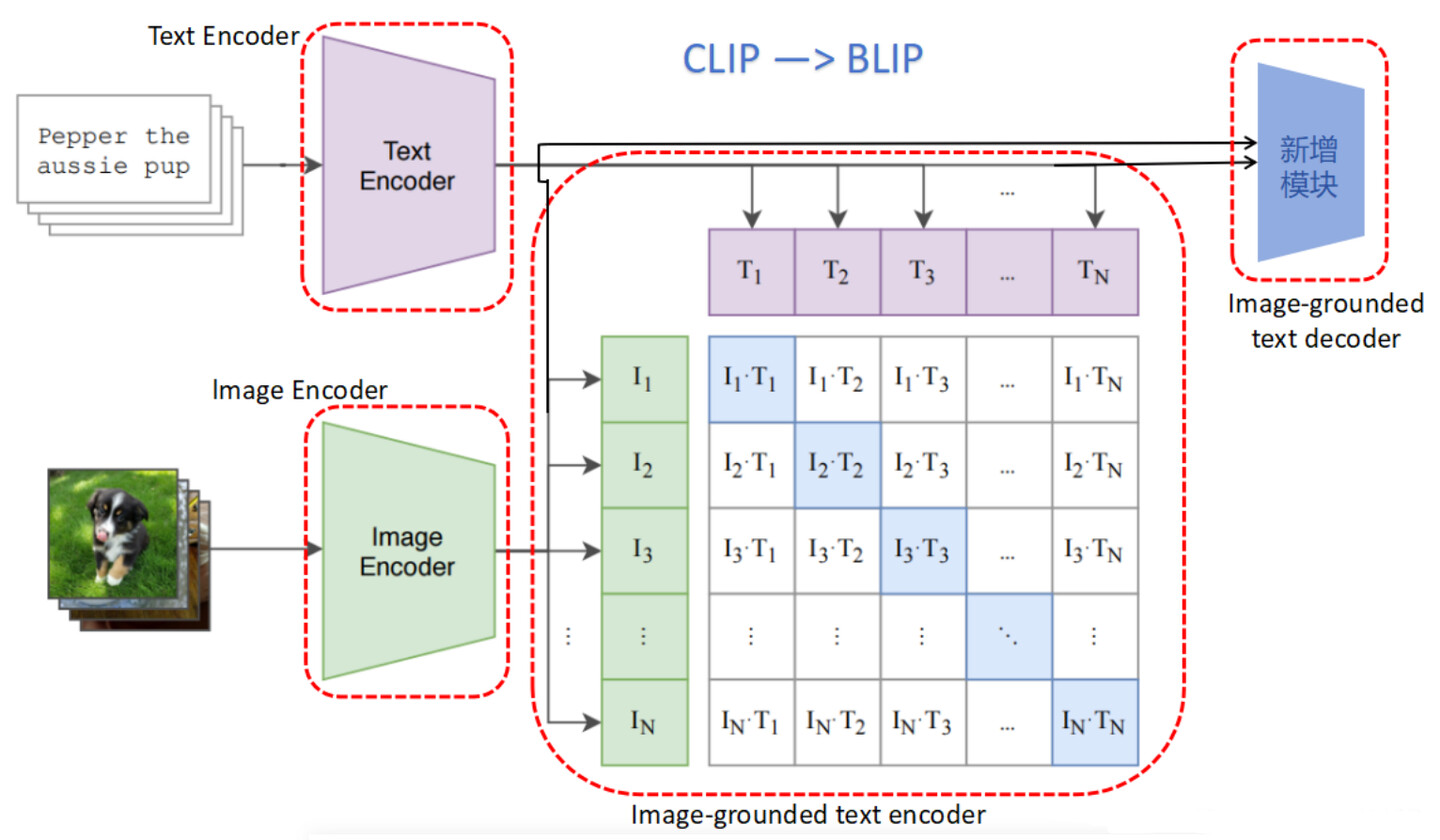
通过上文 lmage Encoder、Text Encoder、Image-grounded text encoder、Image-grounded text decoder 的描述不难发现,四个模块之间共用了一些参数,如下图所示,相同颜色表示共用参数:
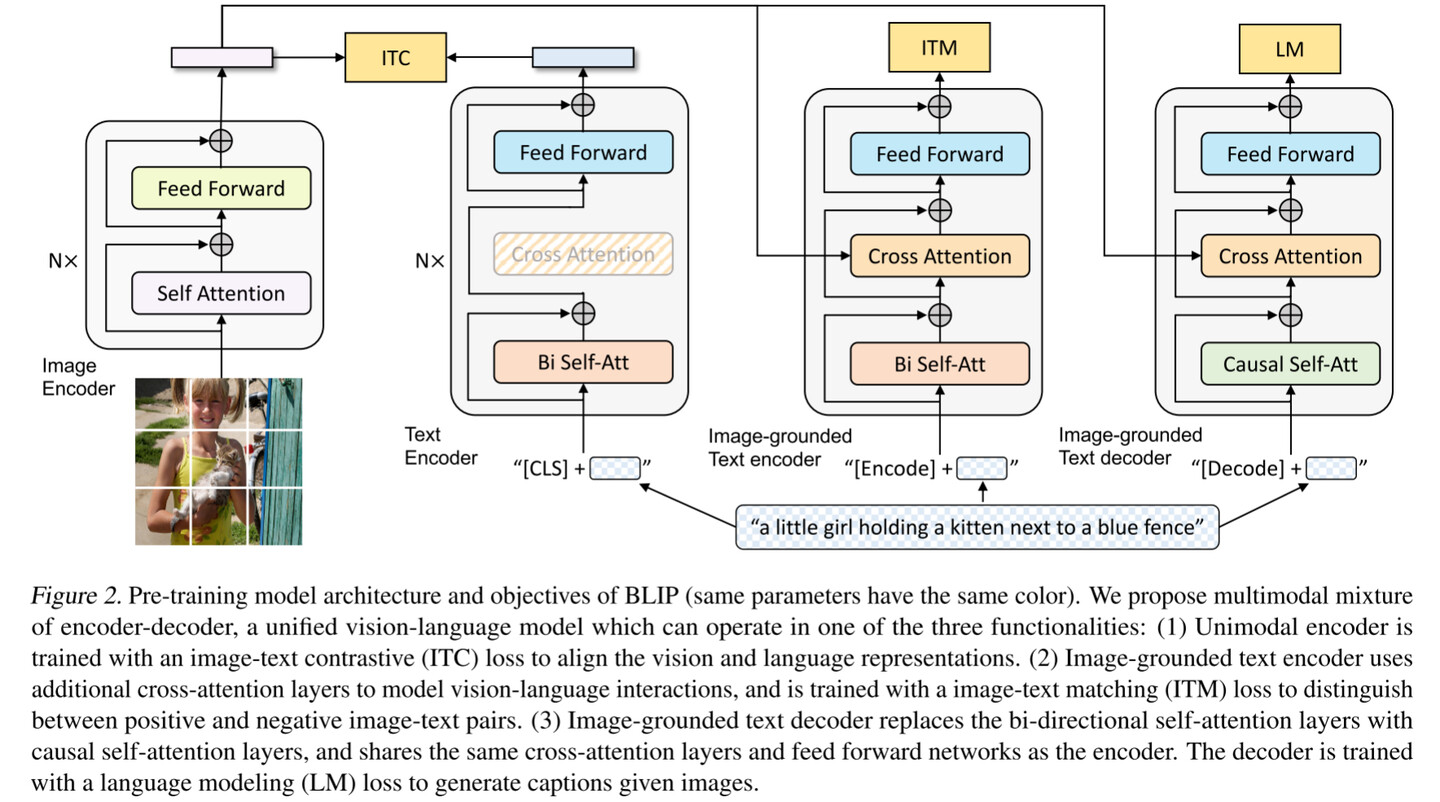
BLIP的预训练模型架构和目标(相同参数具有相同颜色)。提出了一种统一的视觉-语言模型–多模态混合编码器–解码器,该模型具有以下三个功能:(1)使用图像-文本对比度(ITC)损失训练单模态编码器,以匹配视觉和语言表示。(2)基于图像的文本编码器使用额外的交叉注意层来建模视觉-语言交互,并使用图像-文本匹配(ITM)损失来训练以区分正的和负的图像-文本对。(3)基于图像的文本解码器用因果自注意层代替了双向自注意层,并与编码器共享相同的交叉注意层和前馈网络。解码器用语言建模(LM)损失来训练以生成给定图像的字幕。
整个数据优化流程如下:
(1)数据过滤:
初始 Web 数据对 Filter 过滤,得到高质量子集
(2)合成数据生成:
Captioner 为 Web 图像生成合成的描述文本 。
(3)数据增强:
将过滤后的 Web 数据 和合成的描述文本数据 加入到原始数据集中,进一步增强数据量和质量。
(4)人工标注数据的贡献:
高质量的人工标注数据 作为模型优化的重要参考,用于对 Filter 和 Captioner 进行微调。
最终,扩展和优化后的数据集被用来训练新的多模态模型。
2.自举式数据增强(Bootstrapped Data Augmentation)
BLIP 使用了图像-文本配对数据进行训练,这与CLIP类似,CLIP 的数据来源于 Web 上爬来的图像-文本对,采用对比学习的方式,基本属于自监督了,不太需要做数据标注;而BLIP的输入数据集由两部分组成:Web 数据和人工标注数据。BLIP 为了去除Web 数据噪声大的缺点,提出了一种创新的数据增强方法——Captioning and Filtering (CapFilt) 模块,并使用人工标注数据进行微调,通过模型自身生成高质量的图像-文本对来扩充训练数据。具体来说,BLIP利用预训练模型生成图像描述,并过滤掉低质量的数据,从而构建更干净的训练集,CapFilt包含两个模块:一个是captioner,给网络图像生成caption,另一个是Filter,过滤原始网络文本和合成文本中的噪声caption。实验结果表明,通过captioner和filter的协作,BLIP模型能够在各种下游任务上取得了稳定的性能提升,包括图像-文本检索、图像标题、视觉问答、视觉推理和视觉对话。
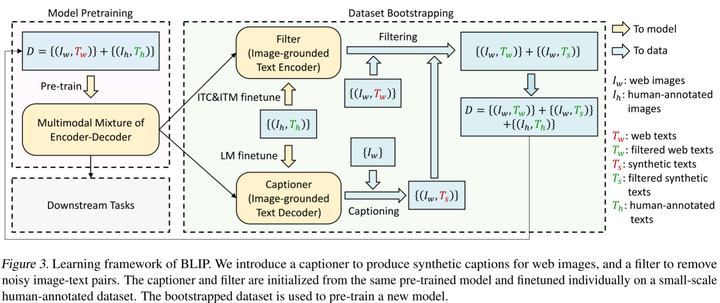
BLIP的学习框架。我们引入了一个字幕器来为网页图像生成合成字幕,并引入了一个过滤器来去除图像-文本对中的噪声。字幕和过滤器从相同的预训练模型初始化,并在小规模人类注释数据集上单独微调。引导数据集用于预训练新模型。
3**.多任务联合优化**
BLIP在预训练阶段联合优化了多个任务目标,包括图像-文本对比学习、图像-文本匹配、(图像到)文本生成任务和广义的文本到图像重构任务。预训练 MED 过程中联合优化了 3 个目标,包括 2 个理解任务的目标函数和 1 个生成任务的目标函数。这种多任务学习机制使得模型能够更好地理解视觉和语言之间的对齐关系。
图文对比损失 (Image-Text Contrastive Loss, ITC):ITC 用于训练 lmage Encoder 和 Text Encoder,通过对比学习对齐图像和文本的特征空间。具体方法是最大化正样本图像 - 文本对的相似度且最小化负样本图像 - 文本对的相似度,从映射的角度讲就是将语义相关的图像 - 文本对映射到空间中的相邻点且语义不相关的图像 - 文本对映射到不相邻的点。这里还使用了 ALBEF 中的动量编码器,目的是产生一些伪标签以辅助模型的训练;
图文匹配损失 (Image-Text Matching Loss, ITM):ITM 用于训练 Image-grounded text encoder,通过学习图像 - 文本对的联合表征实现视觉和语言之间的细粒度对齐。具体方法是通过一个二分类任务,预测图像文本对是正样本还是负样本。这里还使用了 ALBEF 中的 hard negative mining 技术以更好地捕捉负样本信息;
语言建模损失 (Language Modeling Loss, LM):LM 用于训练 Image-grounded text decoder,实现生成图像的文本描述任务。具体方法是通过优化交叉熵损失函数,训练模型以自回归的方式最大化文本的概率。这里还使用了 0.1 的标签平滑计算损失;
4.模态间交互增强
BLIP引入了跨模态注意力机制,增强了图像和文本之间的交互能力。通过这种机制,模型能够更精准地捕捉图像和文本之间的细粒度关联。
数据集上的评价指标得分
BLIP基于PyTorch实现,在两组16 个GPU节点的计算资源上进行预训练。视觉编码器以 ImageNet-1K 上预训练的 ViT 权重初始化,文本编码器以 BERT-Base 的权重初始化。使用 2880 的 Batch Size 训练 20 Epochs。该方法在一系列视觉语言任务上取得了最先进的结果,例如图像文本检索(平均召回率+2.7%)、图像字幕(在CIDEr数据集上 +2.8%)和VQA(在VQA score上+1.6%)。当以zero-shot方式直接转换到视频语言任务时,BLIP也表现出了很强的生成能力。
使用下面4个数据集,图片数加起来大概是 4M。
-
Conceptual Captions
-
SBU Captions
-
COCO
-
Visual Genome
还引入了噪声更大的 Conceptual 12M 数据集,最终将图像总数增加到 14.1M (有的数据集失效了)。
作者还尝试了一个额外的 web 数据集 LAION ,该数据集包含 115M 图像,具有更多的噪声文本。
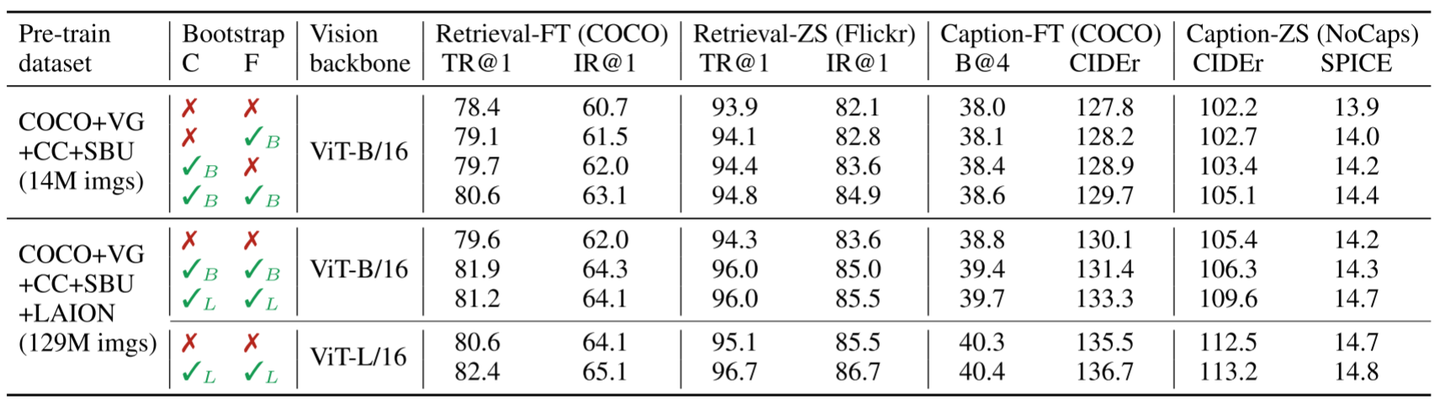
1.CapFilt的消融实验效果
在不同数据集上对预训练的模型进行比较,以证明CapFilt对下游任务的有效性,包括图像-文本检索和具有微调、zero-shot设置的图像字幕。
当使用 14M 的数据集设置时,联合使用字幕器 Captioner 和过滤器 Filter 可以观察到性能改进,而且它们的效果相互互补,证明了 CapFilt 方法能够从嘈杂的原始数据中提炼出有用的数据。
当使用更大的数据集 129M 的设置或者更大的模型 ViT-L 时,CapFilt 可以进一步提高性能,这验证了它在数据大小和模型大小方面的可扩展性。而且,仅仅增加字幕器和过滤器的模型尺寸时,也可以提高性能。
添加图片注释,不超过 140 字(可选)
作者展示了一些示例的字幕与对应的图片。是直接从网络上爬取的原始字幕,是字幕器生成的字幕。图4中的红色文本是 Filter 删除的文本,绿色文本是 Filter 保留下来的文本。可以看出几张图片里面,红色的文本不是不好,只是没有绿色的文本对图片的描述更加贴切。这个结果说明了 CapFilt 方法确实是能够提升图文对数据集的质量。

网络文本 和合成文本 的示例。过滤器接受绿色文本,而拒绝红色文本。
2.多样性是合成字幕的关键
在CapFilt中,BLIP采用Nucleus采样(细胞核采样)以生成合成字幕。Nucleus采样是一种随机解码方法,其中每个令牌都是从累积概率质量超过阈值p的一组令牌中采样的。将其与波束搜索进行比较,波束搜索是一种确定性解码方法,旨在以最高概率生成字幕。实验表明Nucleus采样导致明显更好的性能,因此推测这种方法生成的数据更具多样性(Diversity),波束搜索产生的特性较少。

合成字幕生成的束搜索和核采样之间的比较。模型在14M图像上进行了预训练。
3**.参数共享与解耦**
评估了使用不同参数共享策略预训练的模型,其中预训练是在14M图像和Web文本上执行的。结果表明,与不共享相比,共享除SA之外的所有层会导致更好的性能,同时还减小了模型大小,从而提高了训练效率。如果SA层是共享的,则由于编码任务和解码任务之间的冲突,模型的性能会降低。在CapFilt期间,字幕器和过滤器在COCO上单独进行端到端的微调。
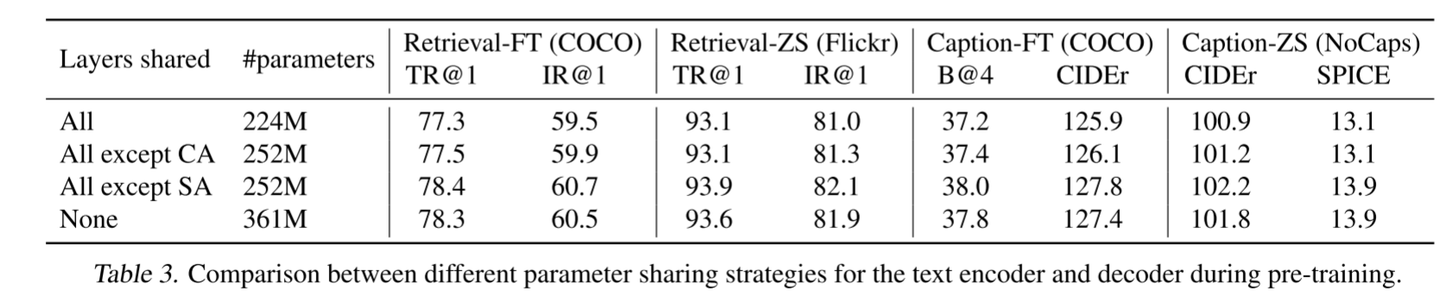
预训练过程中文本编码器和解码器不同参数共享策略的比较。
研究了字幕和过滤器以与预训练相同的方式共享参数的效果。下游任务的绩效下降,我们主要归因于确认偏差。由于参数共享,由字幕器产生的噪声字幕不太可能被过滤掉,如较低的噪声比(8%与25%相比)所指示的。

标题和过滤器之间共享参数的效果。模型在14M图像上进行了预训练。
4.各个下游任务 BLIP 与其他 VLP 模型的对比
检索任务实验结果
BLIP在 COCO 和 Flickr30K数据集比较检索任务实验结果。与现有方法相比,BLIP 实现了显着的性能提升。使用相同的 14M 预训练图像,BLIP 在 COCO 上的平均召回率 R@1 上比之前的最佳模型 ALBEF 高出 +2.7%。作者还通过将在 COCO 上微调的模型直接迁移到 Flickr30K 来做 Zero-Shot Retrieval。结果如图所示,其中 BLIP 的性能也大大优于现有的方法。
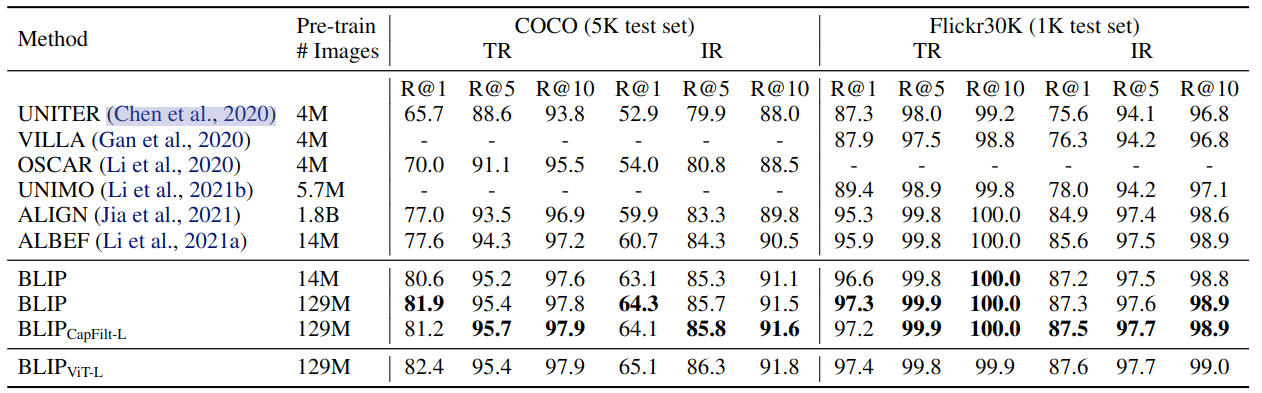
Fine-tuned 检索任务实验结果
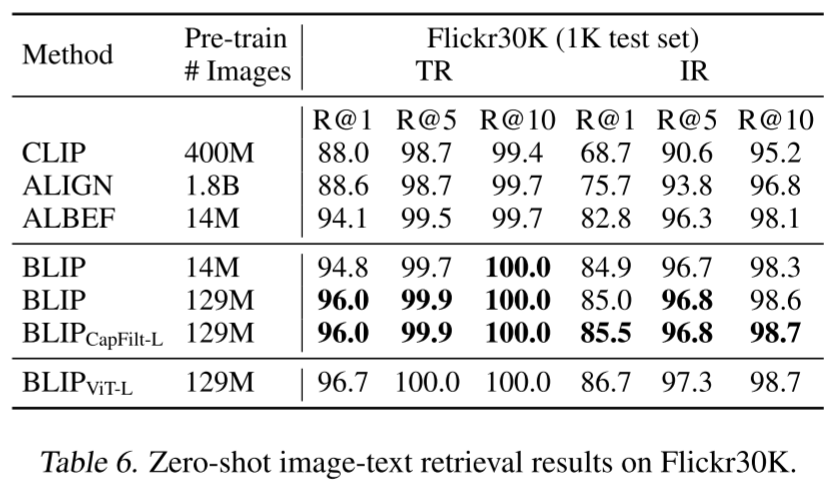
Zero-Shot 检索任务实验结果
图片字幕实验结果
BLIP在 COCO 和 NoCaps 数据集上比较图片字幕任务实验结果,两者都使用在 COCO 上微调的模型和 LM 损失进行评估。遵循 SimVLM 的做法在每个字幕的开头添加了一个提示 “a picture of”,得到的结果更好了。使用了 14M 预训练图像的 BLIP 大大优于使用相似数量预训练数据的方法。使用了 129M 图像的 BLIP 实现了与使用了 200M 的 LEMON 相比具有竞争力的性能。
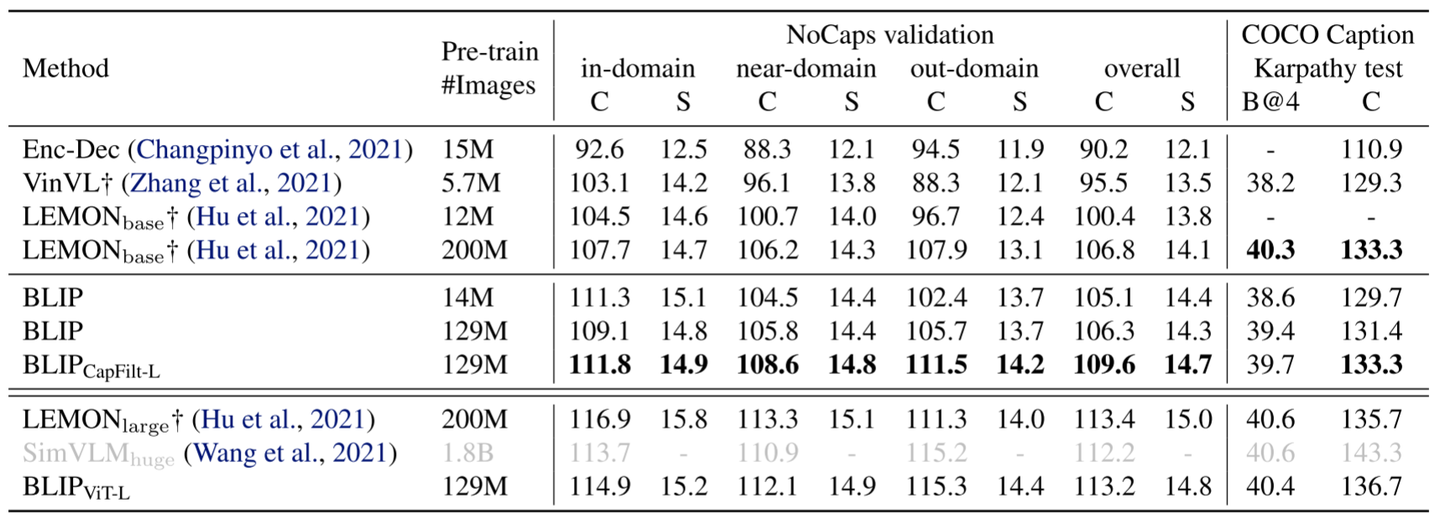
图片字幕实验结果
视觉问答 (Visual Question Answering, VQA) 实验结果
VQA 要求模型预测给定图像和问题的答案。BLIP 没有将 VQA 制定为多答案分类任务,而是按照 ALBEF 的做法把 VQA 视为一种答案生成的任务。使用 14M 图像,BLIP 在测试集上优于 ALBEF 1.64%。
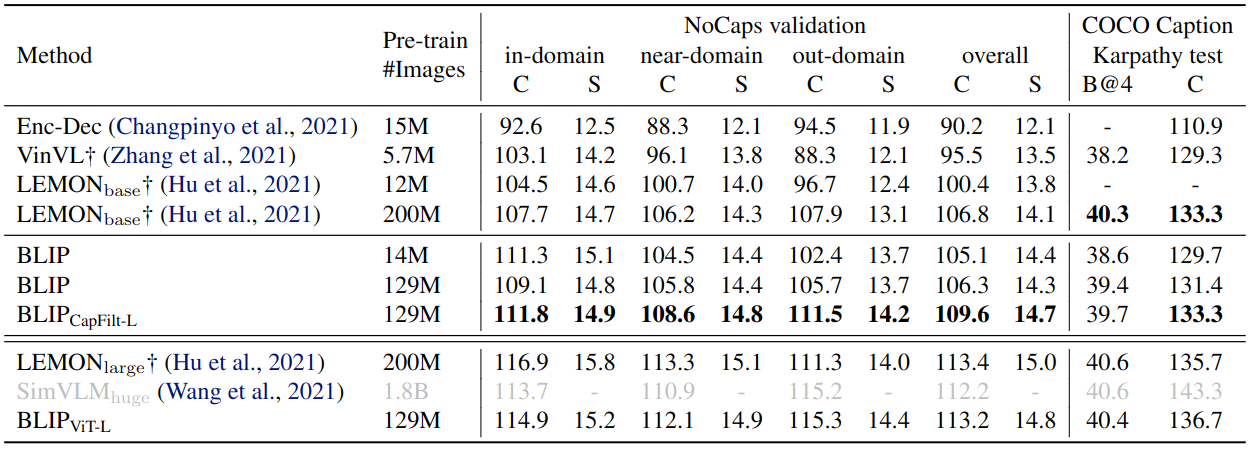
VQA 下游任务实验结果
自然语言视觉推理 (Natural Language Visual Reasoning, NLVR2) 实验结果
自然语言视觉推理任务要求模型预测一个句子是否描述了一对图像,是个二分类任务。为了能对两对图像进行推理,BLIP对预训练模型进行了简单的修改,实验结果优于所有现有方法,除了 ALBEF 执行定制预训练的额外步骤。NLVR2 的性能并没有从额外的网络图像中受益太多,这可能是由于网络数据和下游数据之间的域差距。
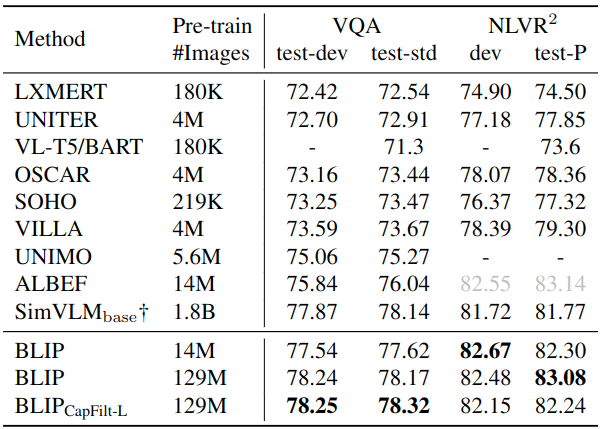
NLVR2 下游任务实验结果
视觉对话 (Visual Dialog, VisDial) 实验结果
视觉对话任务在自然会话设置中扩展了 VQA,其中模型不仅需要基于图像-问题对预测答案,还需要考虑对话历史和图像的字幕。BLIP对预训练模型进行了修改,在 VisDial v1.0 验证集上实现了最先进的性能。
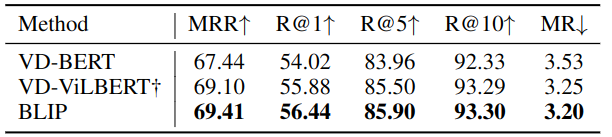
VisDial 下游任务实验结果
创新点优势分析
1.多模态混合预训练框架
通用性强:BLIP的统一框架能够同时处理多种任务,减少了模型设计和训练的复杂性。
效率高:通过共享预训练模型参数,BLIP在多个任务上实现了高效的迁移学习,避免了重复训练的成本。
2.自举式数据增强
数据质量高:通过模型生成和过滤数据,BLIP能够构建更高质量的图像-文本对,从而提升模型的泛化能力。
数据规模扩展:自举式方法能够有效利用未标注数据,缓解了多模态任务中标注数据不足的问题。
3.多任务联合优化
任务协同效应:联合优化多个任务目标使得模型能够同时学习图像-文本的对齐关系和文本生成能力,提升了整体性能。
鲁棒性增强:多任务学习机制使模型在面对不同任务时表现更加稳定,减少了过拟合的风险。
4.模态间交互增强
细粒度对齐:跨模态注意力机制能够捕捉图像和文本之间的细节关联,例如物体属性、空间关系等。
任务性能提升:在图像描述生成和视觉问答等任务中,模态间交互的增强显著提高了模型的准确性和生成质量。
使用 MindNLP 进行模型评估
图像字幕生成与评估过程参照代码实现,首先加载预训练的BLIP图像字幕生成模型和处理器。接着,在COCO2014验证集中选取2500张图像进行预处理并提取标注文件中对应字幕。然后,通过计算生成字幕与参考字幕的相似度,使用CIDEr评估指标来衡量生成字幕的质量。最后,根据评估结果记录相应的分数,从而评估模型的图像字幕生成性能。
CIDEr(Consensus-based Image Description Evaluation)是一种评估图像字幕生成质量的指标,它通过比较生成的字幕与一组参考字幕之间的相似性来衡量字幕的质量。其核心特点包括:
-
N-gram匹配:分析候选字幕和参考字幕间共享的1-gram到4-gram的数量。
-
TF-IDF加权:减少常见但不具区分性的n-gram的影响,增强关键短语的重要性。
-
共识度量:计算候选字幕n-gram向量与所有参考字幕共识向量间的余弦相似度。
-
综合得分:不同长度n-gram得分的加权平均值,范围从0到1。
CIDEr的优势在于它能够更好地反映字幕与图像内容之间的语义一致性,适应性强,并能更准确地识别描述图像关键特征的内容,广泛应用于图像字幕生成等自然语言处理任务中。
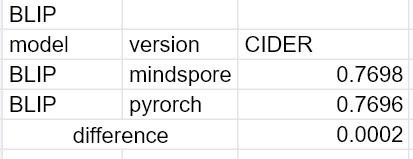
为了验证该模型的效果,我们使用 MindNLP 来加载blip-image-captioning-base 模型,并在数据集(COCO Caption 2014)上进行评估,由于资源限制只随机选取了coco2014验证集中的2500张图片进行测试,所以评分和官方结果有些许出入,但transformers实现与mindnlp误差仅有万分之二几乎可以忽略不计。
| Model | Version | CIDER |
|---|---|---|
| BLIP | mindspore | 0.7698 |
| BLIP | pytorch | 0.7696 |
Difference +0.0002
完整代码
已经上传到 GitHub 仓库中,您可以通过以下链接访问并运行:
BLIP MindNLP 在coco2014中的字幕生成测试代码:GitHub - 4everWZ/BLIP_Mindspore_test · GitHub
我们使用 MindNLP 加载 BLIP的图像字幕生成模型(blip-image-captioning-base),并在coco2014数据集上进行推理测试。以下是代码实现:
import os # os.environ[‘CUDA_HOME’] = ‘/home’ # print(os.environ[‘CUDA_HOME’]) import json from PIL import Image from tqdm import tqdm import mindspore from mindspore import context # context.set_context(device_target=“GPU”) # print(context.get_context(‘device_target’)) from mindspore import Tensor from mindnlp.transformers import BlipForConditionalGeneration import mindnlp from mindnlp.transformers import BlipProcessor from pycocoevalcap.cider.cider import Cider from pycocoevalcap.spice.spice import Spice from pycocotools.coco import COCO # Load the processor and model from MindNLP and MindSpore processor = BlipProcessor.from_pretrained(“Salesforce/blip-image-captioning-base”) model = BlipForConditionalGeneration.from_pretrained( “Salesforce/blip-image-captioning-base” ) # Define CIDEr and SPICE evaluation functions def evaluate_predictions(predictions, references): cider_scorer = Cider() spice_scorer = Spice() # Calculate CIDEr score cider_score, _ = cider_scorer.compute_score(references, predictions) # Calculate SPICE score spice_score, _ = spice_scorer.compute_score(references, predictions) return cider_score, spice_score # Load image and generate caption def generate_caption(image_path): # Load image image = Image.open(image_path).convert(‘RGB’) # Preprocess image and generate caption inputs = processor(images=image, return_tensors=“ms”) # Perform inference with MindSpore model outputs = model.generate(**inputs) caption = processor.decode(outputs[0], skip_special_tokens=True).strip() return caption # Load COCO annotations def load_coco_annotations(json_file): coco = COCO(json_file) img_ids = coco.getImgIds() return coco, img_ids # Get references for captions def get_references(coco, img_id): ann_ids = coco.getAnnIds(imgIds=img_id) anns = coco.loadAnns(ann_ids) return [ann[‘caption’] for ann in anns] # Evaluate CIDEr and SPICE on COCO dataset def evaluate_on_coco(json_file, image_folder, num_images=2500): coco, img_ids = load_coco_annotations(json_file) # Limit to first
num_imagesimages img_ids = img_ids[:num_images] references = {} predictions = {} # Iterate through each image in the COCO dataset with a progress bar for img_id in tqdm(img_ids, desc=“Processing Images”, unit=“image”): img_info = coco.loadImgs(img_id)[0] img_name = img_info[‘file_name’] img_path = os.path.join(image_folder, img_name) # Get reference captions references[img_name] = get_references(coco, img_id) # Generate image caption caption = generate_caption(img_path) print(f"Image: {img_name}, Caption: {caption}“) predictions[img_name] = [caption] # Calculate CIDEr and SPICE scores cider_score, spice_score = evaluate_predictions(predictions, references) return cider_score, spice_score # Define the path to COCO dataset JSON and image folder # COCO validation JSON json_file = “/home/lawrence/dataset/coco2014/annotations/captions_val2014.json” image_folder = “/home/lawrence/dataset/coco2014/val2014” # COCO validation images # Perform evaluation with the first 2500 images or total number of images total_images = len(os.listdir(image_folder)) cider_score, spice_score = evaluate_on_coco( json_file, image_folder, num_images=2500) # Print the results print(f"CIDEr score: {cider_score}”) print(f"SPICE score: {spice_score}")
总结
BLIP模型通过创新的多模态预训练框架多任务联合优化,统一了视觉语言任务的理解与生成功能,并且通过嵌入 Captioner 和 Filter 去除网络资源中的文本噪声,提高了模型在下游视觉语言任务上的性能。其优势在于通用性强、数据质量高、任务协同效应显著以及细粒度对齐能力突出。这些创新点使得BLIP在多模态领域具有广泛的应用潜力,作者在文末表明,BLIP 存在一些潜在的优化方向可以进一步提高性能:
-
多轮数据集的 Bootstrapping;
-
为每幅图像生成多个合成字幕,进一步扩大预训练语料库;
-
训练多个不同的 Captioner 和 Filter 进行集成。
参考链接:
BLIP: Bootstrapped Language-Image Pretraining
多模态论文笔记–CLIP、BLIP_blip模型-CSDN博客