mindspore框架支持在数据下沉时训练动态的切换数据集吗
使用model.train接口似乎不支持动态切换,dataset对象一旦确定,目前没看到文档中说明支持切换数据集对象:但如果自定义训练过程的话,数据集如何处理,是否切换就完全由自己决定,不过自定义训练过程的话数据下沉需要自己额外实现,可能有些麻烦;
不过如果使用自定义数据集的话,在同一个dataset对象内,也是可以实现切换不同数据源的逻辑的
用户您好,欢迎使用MindSpore,请参考上述解答试试~
就是自定义训练因为数据下沉太麻烦了,所以采用自定义数据集,现在是采用MindDataset去处理MindRecord格式数据,不过我想实现一边下载一边训练模型,下载一个数据模型训练一次使用model.train接口并且采用数据下沉看了源码,好像要重新生成dataset_helper,目前还在验证,兄有什么方法能实现自定义数据集一边下载一边训练吗也就是说dataset对象是个动态的
可以试试 GeneratorDataset自定义数据集,里面的逻辑自己实现的,通常情况下就是一些本地的数据文件里读取,你可以替换成是从网络下载;
文档此处的样例示例代码中是随机生成了一些数据:
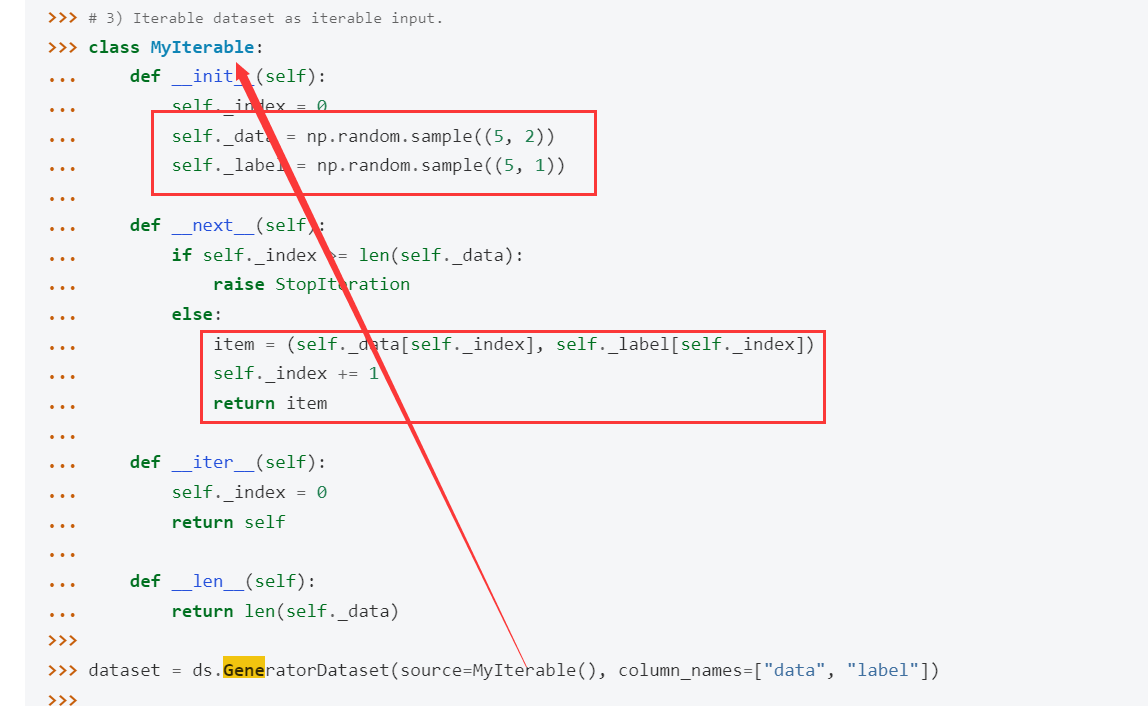
你可以把这边的逻辑改成是从网络下载试试
如果采用GeneratorDataset这种自定义的话那要如何实现训练时的数据下沉操作呢,现在我通过回调机制在epoch开始时重新下载一个覆盖原来的数据,通过cb_params.train_dataset参数重新创建新数据,训练时使用model.train接口训练采用数据下沉操作,通过这种操作可以继续进行训练不过他的步数会出现错误,因为我使用的sink_size=-1,没有重新初始化dataset_helper,后面重新初始化dataset_helper出现进程等待直到ModelArts报错,像是找不到数据集一样,请问这是和图模式有关吗?重新初始化dataset_helper会影响通讯算子吗?
[quote=“Serendipity, post:6, topic:673, full:true”]
如果采用GeneratorDataset这种自定义的话那要如何实现训练时的数据下沉操作呢,现在我通过回调机制在epoch开始时重新下载一个覆盖原来的数据,通过cb_params.train_dataset参数重新创建新数据,训练时使用model.train接口训练采用数据下沉操作,通过这种操作可以继续进行训练不过他的步数会出现错误,因为我使用的sink_size=-1,没有重新初始化dataset_helper,后面重新初始化dataset_helper出现进程等待直到ModelArts报错,像是找不到数据集一样,请问这是和图模式有关吗?重新初始化dataset_helper会影响通讯算子吗?
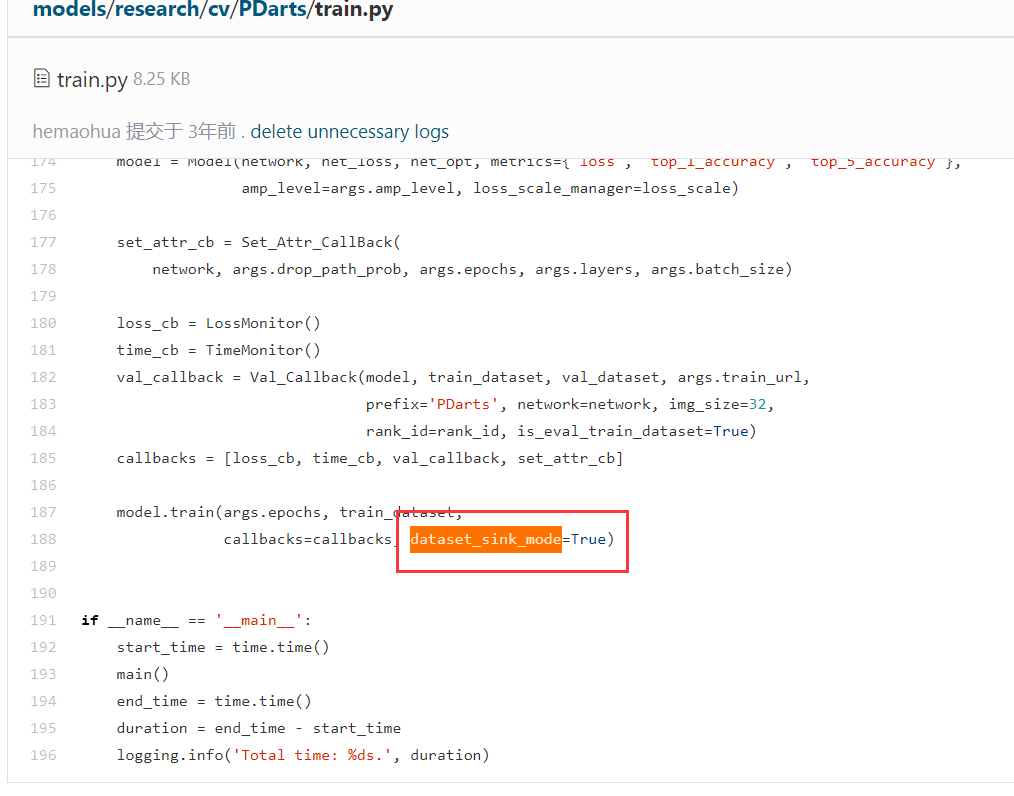
用model.train那种api的话,下沉不是把里面的 dataset_sink_mode参数设置为True就可以了么,和具体用的是哪个数据加载类没有关系,其它能用,GeneratorDataset也一样可以;数据下沉其实就是在训练某一个step的时候,有一个并行的队列在处理准备下一个step需要的数据,他会去调用GeneratorDataset等其它数据类来获取数据的,至于GeneratorDataset里的数据加载逻辑就自己定义了
可以参考下models仓库里的模型,虽然那些模型代码比较早了,可能现在的mindspore版本不能直接运行,但数据处理那边的逻辑基本是通用的,比如PDarts模型:
https://gitee.com/mindspore/models/blob/master/research/cv/PDarts/train.py
用户您好,MindSpore支撑人已经分析并给出了问题的原因,由于较长时间未看到您采纳回答,这里版主将进行采纳回答的结帖操作,如果还其他疑问请发新帖子提问,谢谢支持~