1 系统环境
硬件环境(Ascend/GPU/CPU): Ascend/GPU/CPU
MindSpore版本: mindspore=2.0.0
执行模式(PyNative/ Graph):不限
Python版本: Python=3.9.7
操作系统平台: 不限
2 报错信息
2.1 问题描述
使用mindspore.dataset.Dataset.split切分数据集时,randomize=True切分出来的数据不够随机,数据集标签为0~23
使用NumpySlicesDataset函数加载数据(shuffle=False),split中randmoize=True切分出来效果如下图
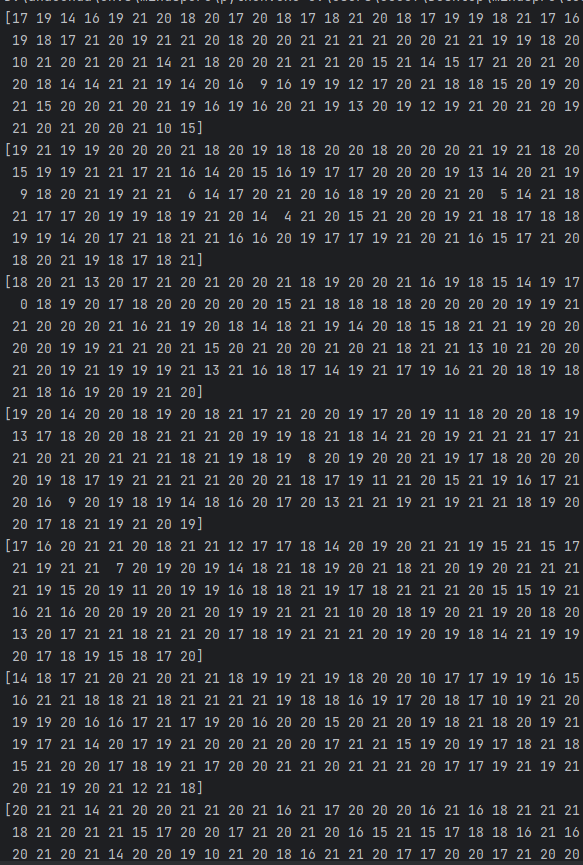
使用NumpySlicesDataset函数加载数据(shuffle=True),split中randmoize=Flase切分出来效果如图
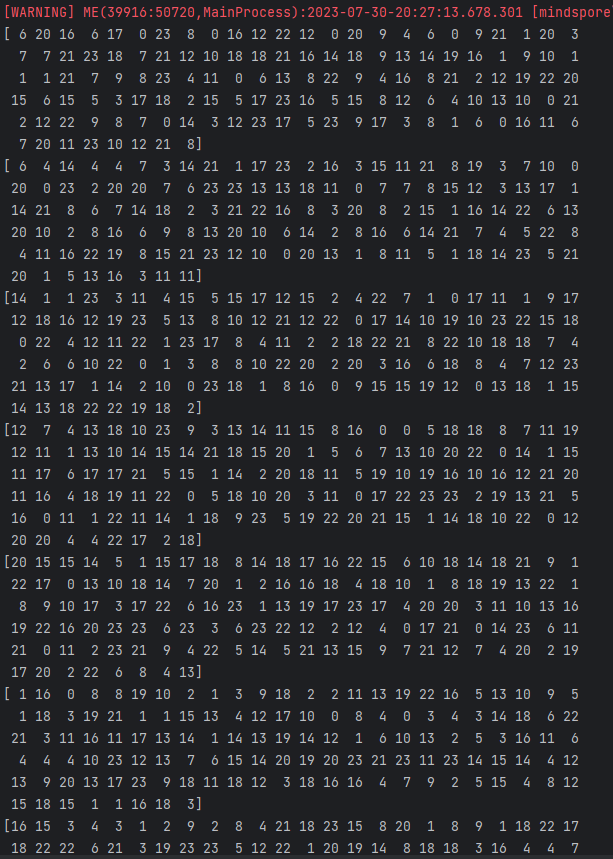
2.2 脚本信息
dataset = ds.NumpySlicesDataset((X,Y),['data','lable'],shuffle=False)
dataset = dataset.map(operations=ds.trainforms.TypeCast(ms.int32),input_columns="lable")
batch_size = 128
train_dataset,test_dataset = dataset.split([0.8,0.2],randomize=False)
train_dataset = train_dataset.batch(batch_size=batch_size)
test_dataset = test_dataset.batch(batch_size=128)
for data,label in test_dataset.create_tuple_iterator():
print(label)
3 解决方案
创建数据集的时候打开shuffle操作,然后对数据集进行相应的切分。
dataset = ds.NumpySlicesDataset((X,Y),['data','lable'],shuffle=True)
dataset = dataset.map(operations=ds.trainforms.TypeCast(ms.int32),input_columns="lable")
batch_size = 128
train_dataset,test_dataset = dataset.split([0.8,0.2],randomize=False)
train_dataset = train_dataset.batch(batch_size=batch_size)
test_dataset = test_dataset.batch(batch_size=128)
for data,label in test_dataset.create_tuple_iterator():
print(label)