1 报错描述
1.1 系统环境
ardware Environment(Ascend/GPU/CPU): CPU Software
Environment: – MindSpore version (source or binary): 1.6.0
Python version (e.g., Python 3.7.5): 3.7.6
OS platform and distribution (e.g., Linux Ubuntu 16.04): Ubuntu 4.15.0-74-generic – GCC/Compiler version (if compiled from source):
1.2 基本信息
1.2.1脚本
此案例使用自定义可迭代数据集进行训练,在训练过程中,第一个epoch数据正常迭代,第二个epoch就会报错,自定义数据代码如下:
import numpy as np
import mindspore.dataset as ds
from tqdm import tqdm
class IterDatasetGenerator:
def __init__(self, datax, datay, classes_per_it, num_samples, iterations):
self.__iterations = iterations
self.__data = datax
self.__labels = datay
self.__iter = 0
self.classes_per_it = classes_per_it
self.sample_per_class = num_samples
self.classes, self.counts = np.unique(self.__labels, return_counts=True)
self.idxs = range(len(self.__labels))
self.indexes = np.empty((len(self.classes), max(self.counts)), dtype=int) * np.nan
self.numel_per_class = np.zeros_like(self.classes)
for idx, label in tqdm(enumerate(self.__labels)):
label_idx = np.argwhere(self.classes == label).item()
self.indexes[label_idx, np.where(np.isnan(self.indexes[label_idx]))[0][0]] = idx
self.numel_per_class[label_idx] = int(self.numel_per_class[label_idx]) + 1
def __next__(self):
spc = self.sample_per_class
cpi = self.classes_per_it
if self.__iter >= self.__iterations:
raise StopIteration
else:
batch_size = spc * cpi
batch = np.random.randint(low=batch_size, high=10 * batch_size, size=(batch_size), dtype=np.int64)
c_idxs = np.random.permutation(len(self.classes))[:cpi]
for i, c in enumerate(self.classes[c_idxs]):
index = i*spc
ci = [c_i for c_i in range(len(self.classes)) if self.classes[c_i] == c][0]
label_idx = list(range(len(self.classes)))[ci]
sample_idxs = np.random.permutation(int(self.numel_per_class[label_idx]))[:spc]
ind = 0
for i in sample_idxs:
batch[index+ind] = self.indexes[label_idx]
ind = ind + 1
batch = batch[np.random.permutation(len(batch))]
data_x = []
data_y = []
for b in batch:
data_x.append(self.__data)
data_y.append(self.__labels)
self.__iter += 1
item = (data_x, data_y)
return item
def __iter__(self):
return self
def __len__(self):
return self.__iterations
np.random.seed(58)
data1 = np.random.sample((500,2))
data2 = np.random.sample((500,1))
dataset_generator = IterDatasetGenerator(data1,data2,5,10,10)
dataset = ds.GeneratorDataset(dataset_generator,["data","label"],shuffle=False)
epochs=3
for epoch in range(epochs):
for data in dataset.create_dict_iterator():
print("success")
1.2.2报错
报错信息:
RuntimeError: Exception thrown from PyFunc. Unable to fetch data from GeneratorDataset, try iterate the source function of GeneratorDataset or check value of num_epochs when create iterator.
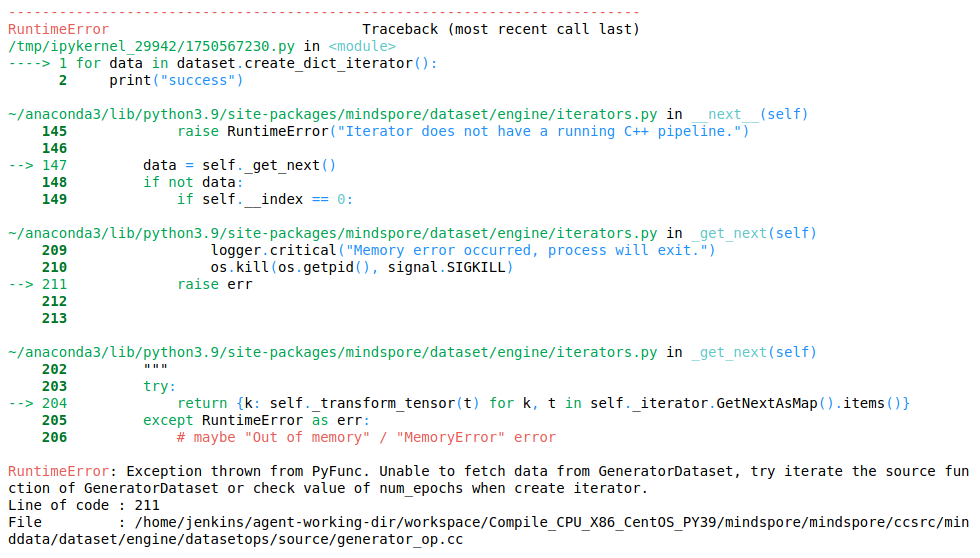
2 原因分析
每次数据迭代的过程中,self.__iter会累加,第二个epoch的预取时,self.__iter已经累计到设置好的iterations的值,导致self.__iter >= self.__iterations,循环结束。
3 解决方法
在def __iter__(self):中加入清零操作,设置self.__iter = 0
import numpy as np
import mindspore.dataset as ds
from tqdm import tqdm
class IterDatasetGenerator:
def __init__(self, datax, datay, classes_per_it, num_samples, iterations):
self.__iterations = iterations
self.__data = datax
self.__labels = datay
self.__iter = 0
self.classes_per_it = classes_per_it
self.sample_per_class = num_samples
self.classes, self.counts = np.unique(self.__labels, return_counts=True)
self.idxs = range(len(self.__labels))
self.indexes = np.empty((len(self.classes), max(self.counts)), dtype=int) * np.nan
self.numel_per_class = np.zeros_like(self.classes)
for idx, label in tqdm(enumerate(self.__labels)):
label_idx = np.argwhere(self.classes == label).item()
self.indexes[label_idx, np.where(np.isnan(self.indexes[label_idx]))[0][0]] = idx
self.numel_per_class[label_idx] = int(self.numel_per_class[label_idx]) + 1
def __next__(self):
spc = self.sample_per_class
cpi = self.classes_per_it
if self.__iter >= self.__iterations:
raise StopIteration
else:
batch_size = spc * cpi
batch = np.random.randint(low=batch_size, high=10 * batch_size, size=(batch_size), dtype=np.int64)
c_idxs = np.random.permutation(len(self.classes))[:cpi]
for i, c in enumerate(self.classes[c_idxs]):
index = i*spc
ci = [c_i for c_i in range(len(self.classes)) if self.classes[c_i] == c][0]
label_idx = list(range(len(self.classes)))[ci]
sample_idxs = np.random.permutation(int(self.numel_per_class[label_idx]))[:spc]
ind = 0
for i in sample_idxs:
batch[index+ind] = self.indexes[label_idx]
ind = ind + 1
batch = batch[np.random.permutation(len(batch))]
data_x = []
data_y = []
for b in batch:
data_x.append(self.__data)
data_y.append(self.__labels)
self.__iter += 1
item = (data_x, data_y)
return item
def __iter__(self):
self.__iter = 0
return self
def __len__(self):
return self.__iterations
np.random.seed(58)
data1 = np.random.sample((500,2))
data2 = np.random.sample((500,1))
dataset_generator = IterDatasetGenerator(data1,data2,5,10,10)
dataset = ds.GeneratorDataset(dataset_generator,["data","label"],shuffle=False)
epochs=3
for epoch in range(epochs):
for data in dataset.create_dict_iterator():
print("success")
此时执行成功,输出如下:
4 类似问题
在mindspore1.3.0中,用户自定义训练,使用Generator dataset迭代数据报错。错误截图如下:
此报错中,dataset 的 len 函数返回值是36,但是真实的 next 返回的数据量只有35条,导致报错,可将返回值改为小于35的数进行快速验证。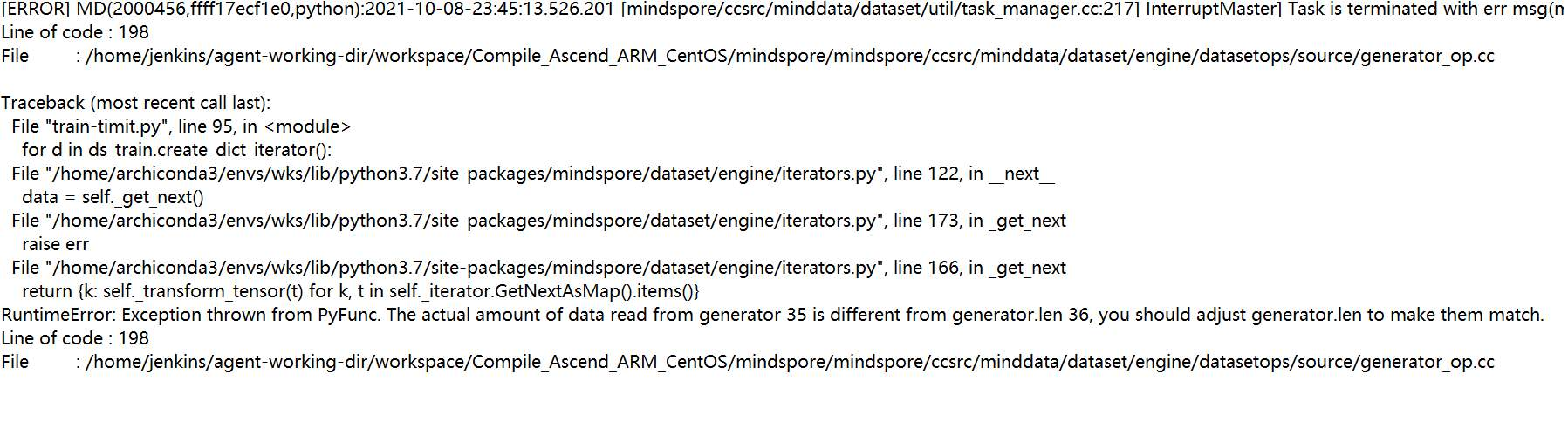
5 总结
5.1 定位报错问题的步骤
1、找到报错的用户代码行:for data in dataset.create_dict_iterator():; 2、根据报错信息提示,无法从GeneratorDataset获取数据,检查是否在自定义数据的时候就出现问题。打印运行中的过程数据,发现第一个epoch数据读取完后,真实读取的数据条数与__len__是相等的,没有问题。但由于没有清零操作,在第二个epoch预取时self.__iter >= self.__iterations,循环结束,导致第二个epoch取不到数据报错。
5.2 此类问题分析
此类问题的根本原因是需要获取的数据索引与数据量对不上,在构造可迭代的的数据集类时需要注意每次运行后数据清零的问题,在快速验证时,也需要满足索引小于数据总量的条件。
6 参考文档
mindspore文档->数据管道->数据加载->自定义数据集加载->构造可迭代的数据集类 https://www.mindspore.cn/doc/programming_guide/zh-CN/r1.1/dataset_loading.html#id7