模型推理
介绍
举个例子,学生学习和考试,学生平时课堂学习,写作业等,可以看成是 AI 模型的训练,学生写作业,老师批改作业,以及老师答疑,都是在给学生反馈哪些是正确的哪些是错误的,通过这个过程学生掌握了课本里面的知识。 到了考试以后,考题多数情况下是跟平时做的题目不一样(肯定不是现成一模一样的题目),学生需要利用掌握的知识来分析解答考试题目,这个就是推理的过程。 但是有一点需要说明,考试的知识点肯定要在课本知识范围内,即考试不能超纲,否则学生也答不上来或者答的效果不好,AI 推理本质也是一样,上述说的全新数据也是要在 AI 训练数据的大范围内,例如一个人脸识别的模型,训练的时候拿的都是人脸数据,包含男人、女人、老人、小孩等等,但是推理的时候拿一张小猫的图片让其识别,大概率会识别错误。
原理
大模型推理框架的原理主要基于深度学习算法和神经网络。深度学习算法通过模拟人脑神经元的连接方式,构建出具有强大学习能力的神经网络模型。在训练阶段,模型通过不断地学习大量数据中的特征,逐步优化其参数,以提高预测和分类的准确性。在推理阶段,模型根据输入的数据,通过神经网络模型进行前向传播,输出预测结果。
过程
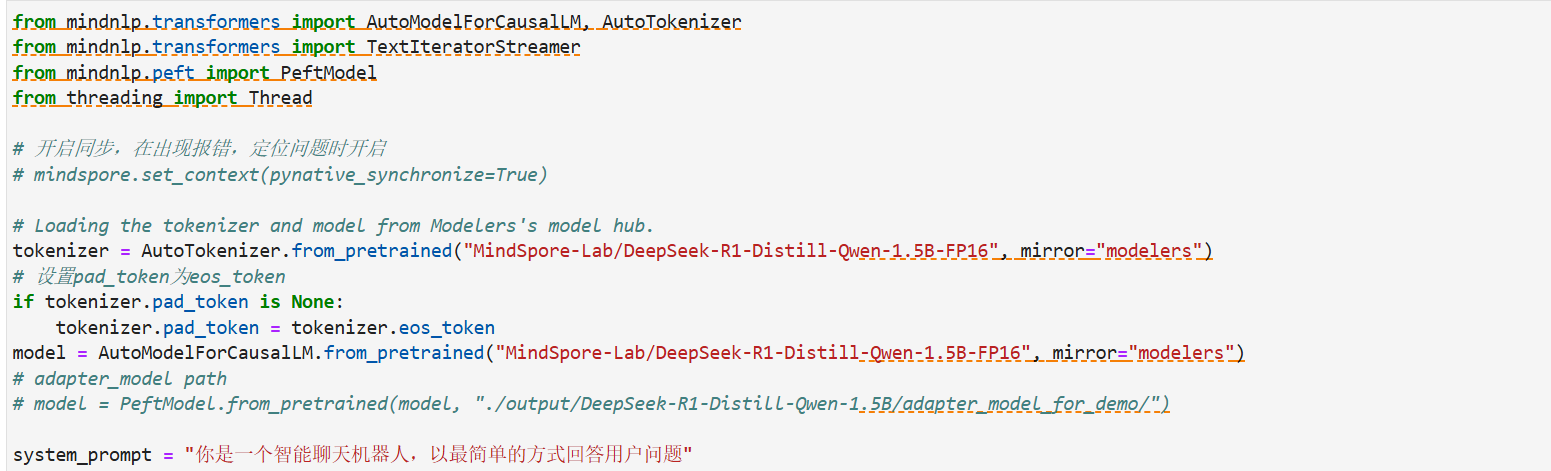
权重加载:最终的模型包含两部分:base model和LoRA adapter,其中base model加载原权重,LoRA adapter通过PeftModel.from_pretrained进行加载。
![]()
启动推理:通过model.generate启动
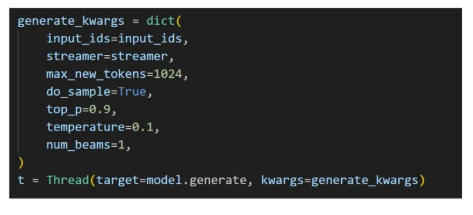
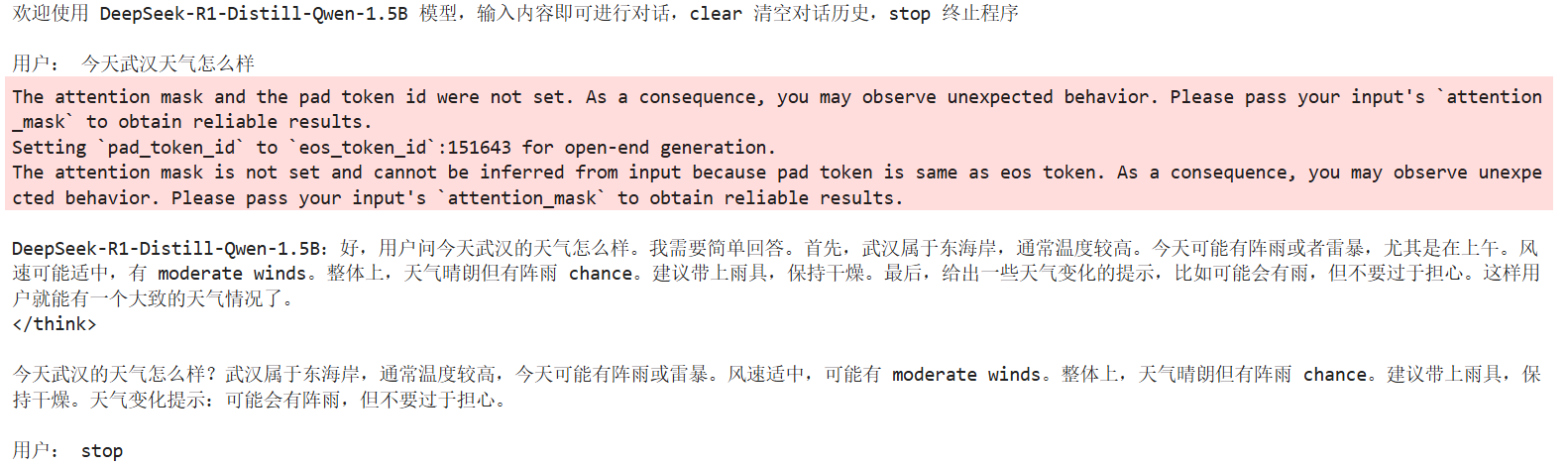
效果比较:以一个微调多轮后的LoRA权重为例,在微调前(不加载LoRA adapter),在问模型“你是谁”时,回答的是“DeepSeek-R1”,而在加载LoRA adapter之后,回答为“甄嬛”

效果调优:在进行长文本输出的过程当中,输出回答到一定长度后模型会输出重复内容,如下图所示,可在generate_kwargs中添加repetition_penalty=1.2,解决长文本输出重复问题
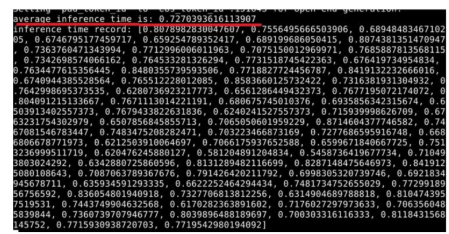
性能测试:凡是在推理过程中涉及采样(do_sample=True)的案例,可以通过配置如下变量,注释掉之前添加的同步模式代码,再运行代码,即可获取每个token的推理时长和平均时长。
export INFERENCE_TIME_RECORD=True
性能优化:
前序准备
1.实现解码逻辑(decode函数、prefill-decode阶段)
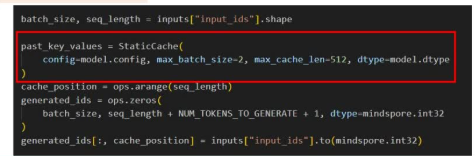
2.实例化StaticCache,动态Cache无法成图
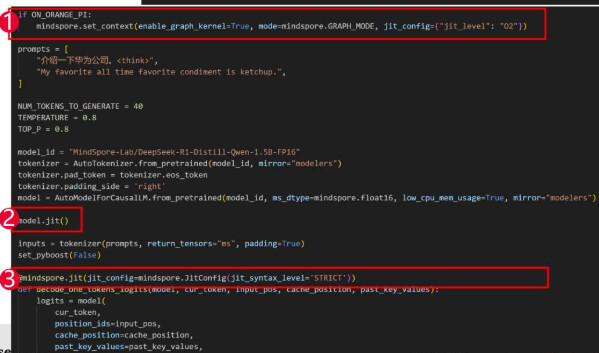
添加jit装饰器
1.设置O2整图下沉进一步优化
2.model.jit()
3.mindspore.jit装饰decode函数
实训环节
模型推理
加载模型
进行对话
性能优化
开启O2级别的jit优化,开启图算融合
mindspore.set_context(
enable_graph_kernel=True,
mode=mindspore.GRAPH_MODE,
jit_config={
“jit_level”: “O2”,
},
)
时间测试
