模型推理和性能优化:
大模型推理是指利用已经训练完成的大型人工智能模型,对新的输入数据进行分析、理解和生成输出的过程。在这一过程中,模型基于其在训练阶段学到的知识,对新的输入内容进行预测、分类、生成或其他形式的处理。
推理过程:
当前主流的大模型采用的架构是 Decode-Only 架构,也就是只使用了 Transformer 架构中的解码器部分,并不使用编码器部分。整个推理过程主要分为两个阶段:一个是 Prefill 阶段,一个是 Decode 的阶段。
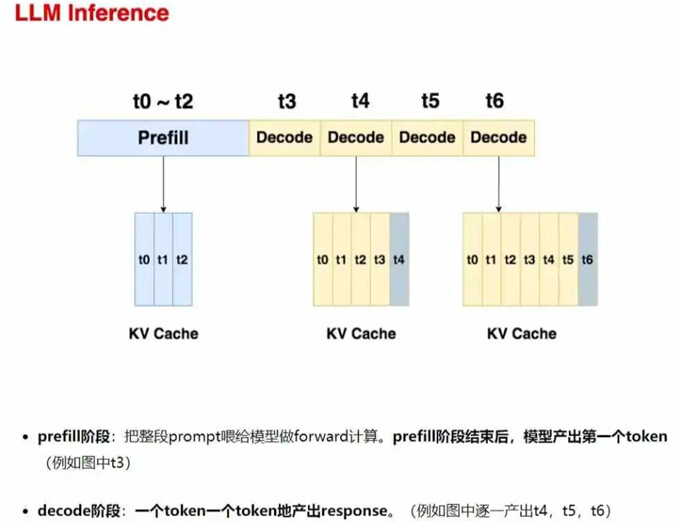
在大模型对话中,用户输入的问题称为prompt。模型首先生成第一个回答单词(Prefill阶段),即根据prompt理解并输出初始词;随后基于已生成内容逐步预测后续单词(Decode阶段),直至回答完成。两阶段运算逻辑相同,但输入不同:Prefill依赖用户提问,Decode则基于已生成的文本。整个过程本质是自回归生成,即每一步都基于历史信息预测下一个最可能的词,最终形成完整回复。举个例子,假设你问大模型一句话:“今天吃饭了吗?”,大模型最终回答你:“我不需要吃饭,不过谢谢你的关心,你呢,今天吃什么了?”

第一次的输入是“今天吃饭了吗”这句话,模型的输出是回答中的第一个词,也就是“我”。随后,将得到的输出和输入加在一起,得到 “今天吃饭了吗?我” 作为新的 Prompt 输入给大模型,然后大模型输出"不”,依次类推…直到满足一定的条件则停止输出,模型回答完毕。
性能优化: KV Cache
在LLM中,自回归生成是核心机制,模型基于提示词逐步预测下一个token,依赖Transformer的自注意力机制。每个token通过计算Query(Q)、Key(K)、Value(V)向量,用当前Q与历史K的点积得到注意力分数,再加权汇总V生成输出。为提升效率,历史K/V向量被缓存为KV Cache,避免重复计算,但会占用显存。优化KV Cache(如裁剪、压缩)可显著加速推理并降低资源消耗。
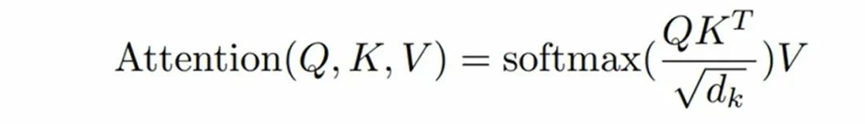
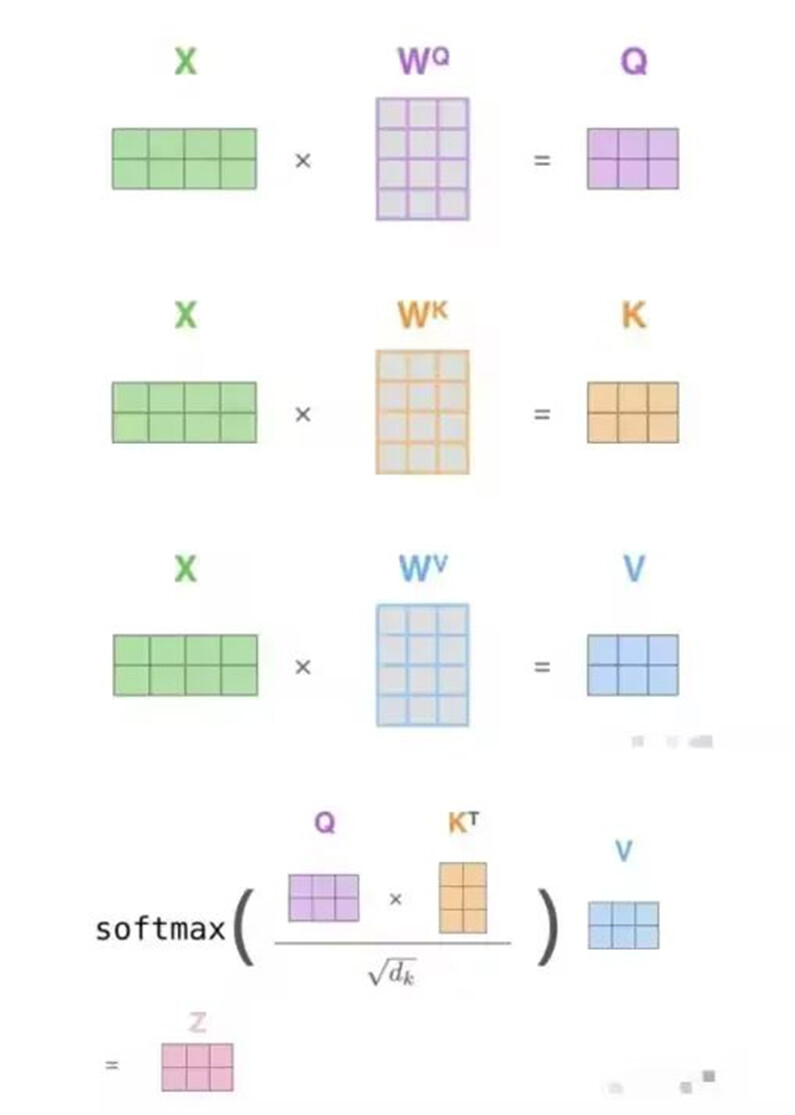
KV Cache如今已经是主流大语言模型的通用技术,通过缓存每一步生成过程中的Key和Value向量(即KV Cache),避免重复计算,节省算力。这部分缓存不会一直常驻GPU显存,而是会随着请求的增长,动态的增长和释放。所以KV Cache的管理至关重要,不合理的KV Cache管理会出现大量的内存碎片,导致内存等资源浪费,进而限制并发、拉低整体吞吐。
代码实训过程:
推理过程实现
首先,将环境准备完成后,点击运行,开始推理。
运行一段时间后,弹出如下对话框
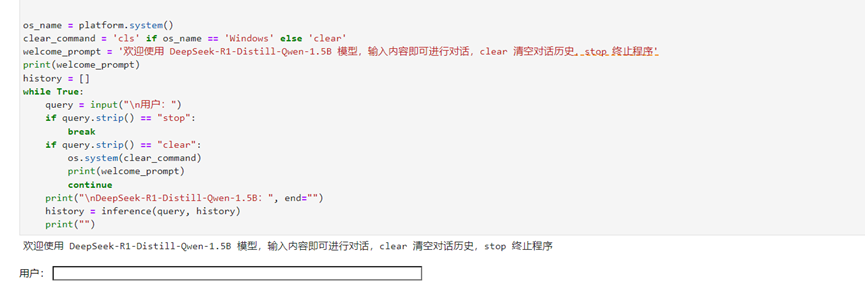
可在对话框中输入简单的提问,如你是谁?模型给出答案,推理效果实现

然后输入stop终止程序,完整的推理过程完整。
推理JIT优化:
首先,jit修饰器应该修饰模型decode的函数,但由于原代码将模型的logits计算、解码等过程整体封装成了一个model.generate函数,不好进行优化,所以需要手动实现解码逻辑。
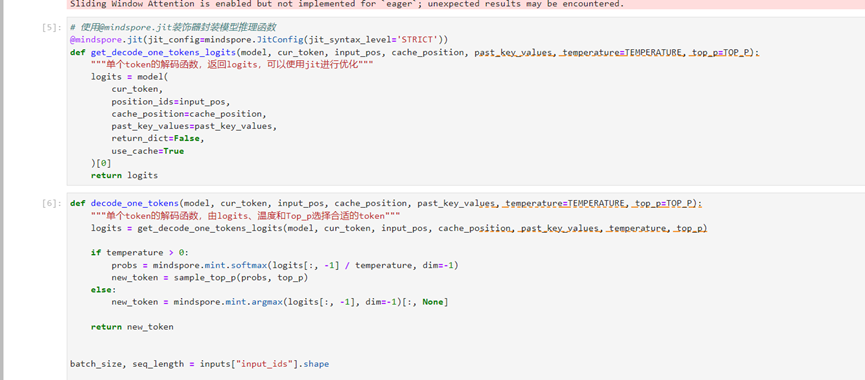
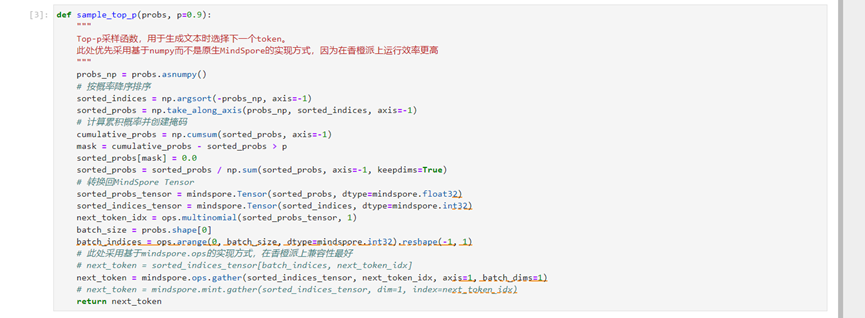
然后,实现Top_p函数,出于效率的考虑,优先使用numpy进行函数的实现而在gather函数的实现上,基于mindspore.mint的实现方,式会出现报错,故使用mindspore.ops来实现。
最后的运行结果如下图所示
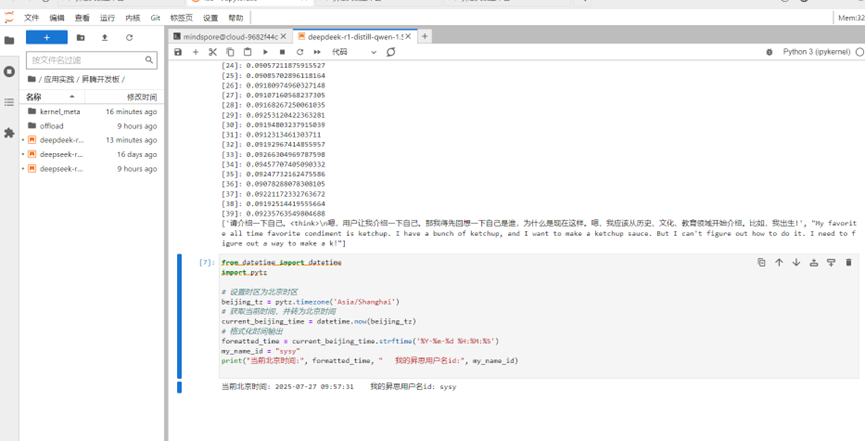
推理时间变短,性能得到了提升。
小结: 通过本次课的学习,我对模型的推理过程有了明确的认知,并学会了一下推理过程优化的方法,还通过代码实训模拟了模型的推理过程和推理JIT优化,提升了我的实践操作能力,也提高了我的认知水平。