昇思学习营第七期·昇腾开发板 第三次学习打卡
encode-decode结构
编码器-解码器结构适应于处理变长序列的输入和输出,常用于机器翻译和语音识别。编码器将变长序列转化为固定长度状态,而解码器则从该状态生成新的变长序列。此架构允许模型处理不同长度的输入和输出序列,具有广泛的应用前景。
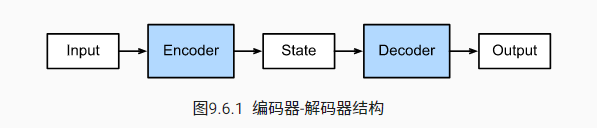
encode的输入是变长的序列向量,每个向量之间会在batch内填充为固定长度,神经网络限制,不能输入变长的向量。
encode输出固定长度的向量,但序列数量和输入数量保持不变,也就是一个输入产生一个输出。每个输出之间是独立的。
encode的网络可以不固定,比如常见nlp任务用rnn,。
encode将可变序列编码为固定状态,decode将固定状态输入映射为其它可变序列。
decode的网络可以不固定,其中ctc 结合search策略也可以用来做decode。
模板解释
- encoder
在编码器接口中,我们只指定长度可变的序列作为编码器的输入X。任何继承这个Encoder基类的模型将完成代码实现 - decoder
解码器接口中,我们新增一个init_state函数用于将编码器的输出(enc_outputs)转换为编码后的状态。注意,此步骤可能需要额外的输入,例如:输入序列的有效长度,逐个生成长度可变的标记序列,解码器在每个时间步都可以将输入(例如:在前一时间步生成的标记)和编码后的状态映射成当前时间步的输出标记。
- encoder-decoder
最后,“编码器-解码器”结构包含了一个编码器和一个解码器,并且还包含了可选的额外的参数。在前向传播中,编码器的输出产生编码状态,解码器将使用该状态作为其输入之一。
总结
-
“编码器-解码器”结构可以处理长度可变的序列作为输入和输出,因此适用于机器翻译,语音识别等序列转换问题。
-
编码器将长度可变的序列作为输入,并将其转换为具有形状固定的状态。
-
解码器将形状固定的编码状态映射为长度可变的序列。
模型推理
用lora微调后的模型
若遇到如下错误
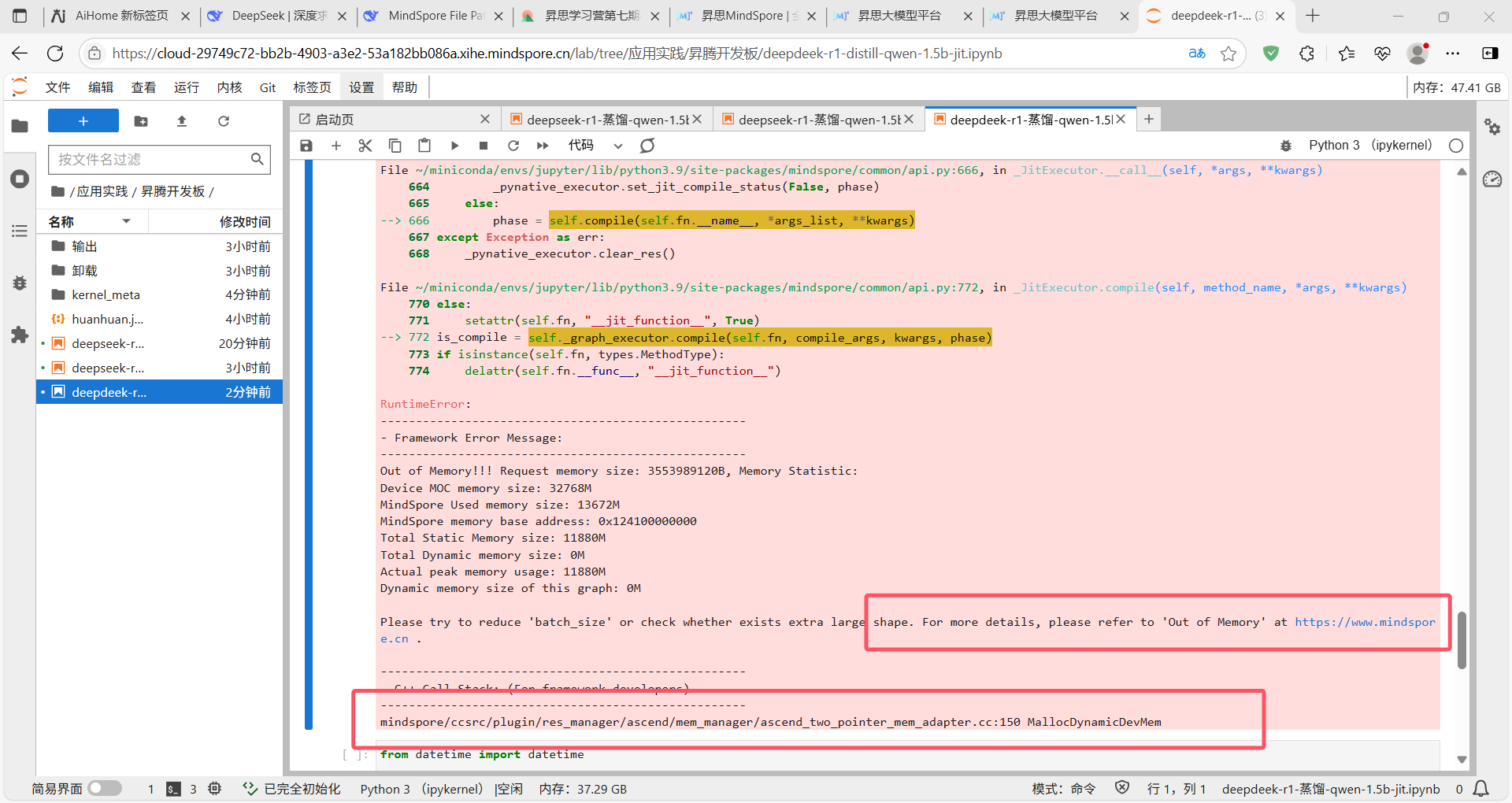
如果遇到这种报错就是显存不足。进行如下操作:
首先去终端中查看现存和占用显存程序的PID号;
使用此命令:npu-smi info
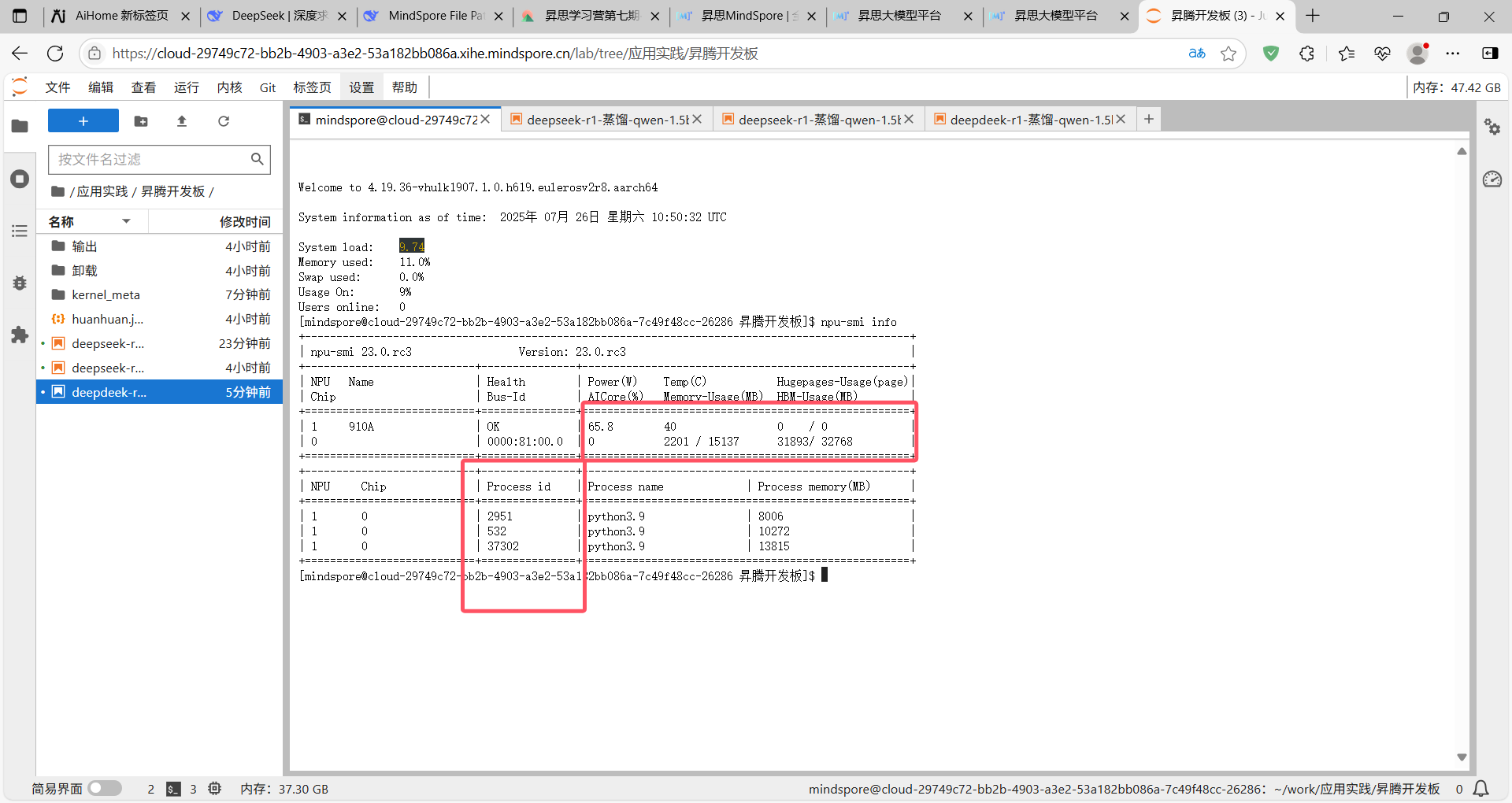
可以看到现存确实不足了,被三个python程序占用着:
2951
532
37302
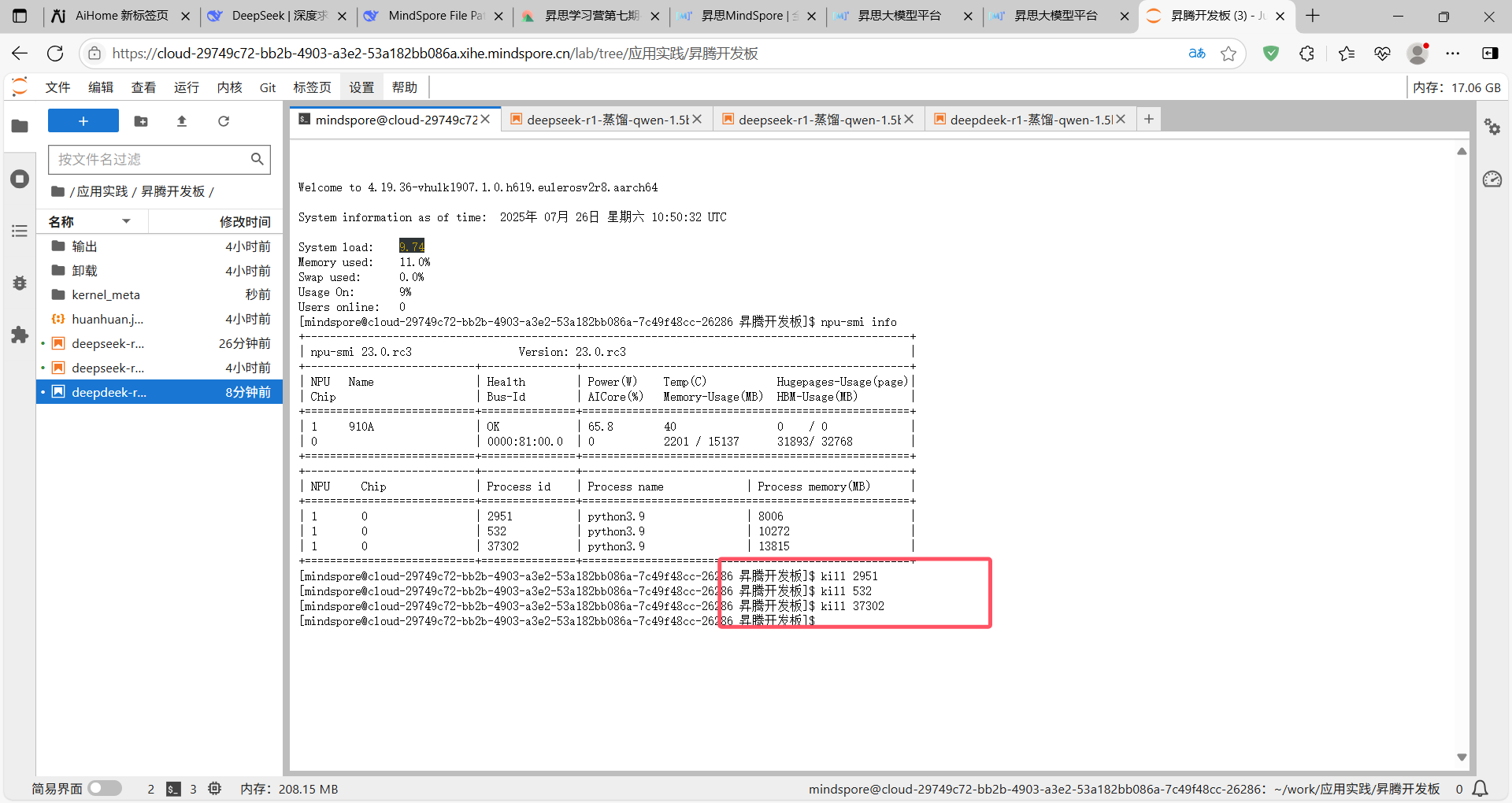
此时,我们需要在终端中kill掉这三个pid
kill 2951
kill 532
kill 37302
然后去重新运行程序:
顺利解决
小结
通过本次实操学习我了解了推理模型这一前沿科技,在这操作过程中我体会到 深度学习部署 不仅仅是训练好模型就了事了,真正的挑战往往出现在 工程落地 环节。