如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
1 环境准备
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,可以在昇思教程中进入ModelArts官网
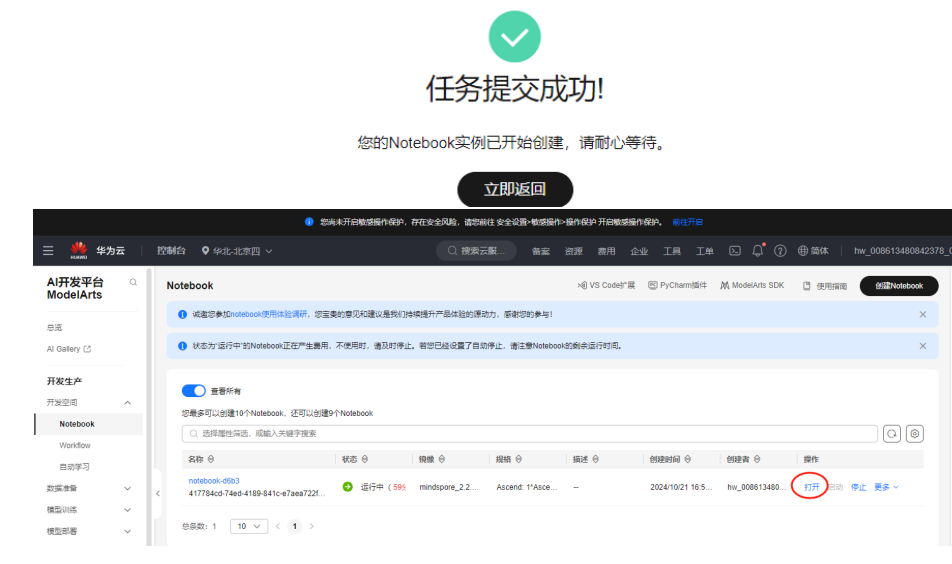
创建notebook,点击【打开】启动,进入ModelArts调试环境页面。
注意选择西南-贵阳一,mindspore_2.3.0
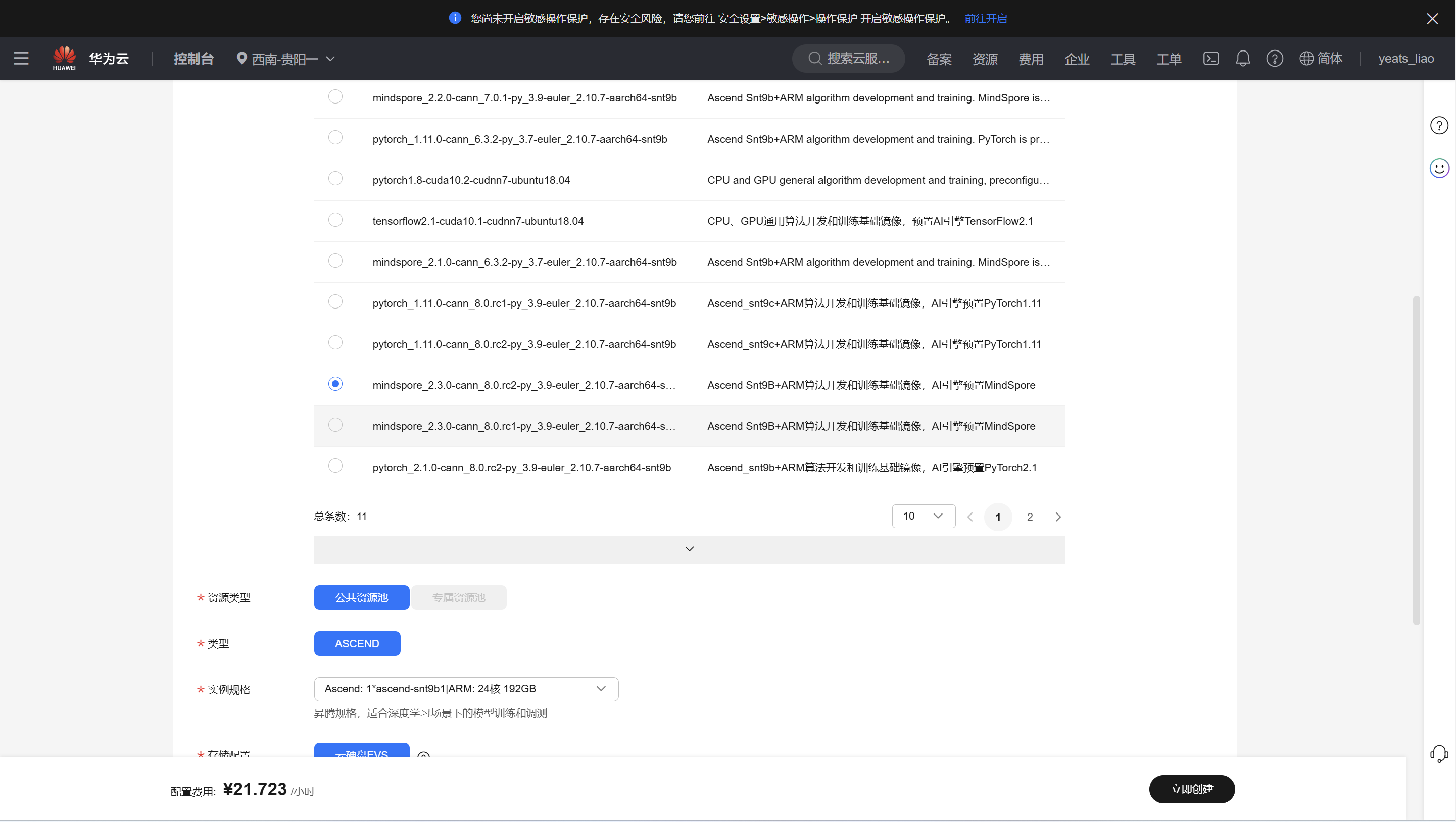
等待环境搭建完成
下载案例notebook文件
小型CNN模型之SqueezeNet网络:applications/squeezenet-mindspore/SqueezeNet.ipynb at master · mindspore-lab/applications · GitHub
选择ModelArts Upload Files上传.ipynb文件
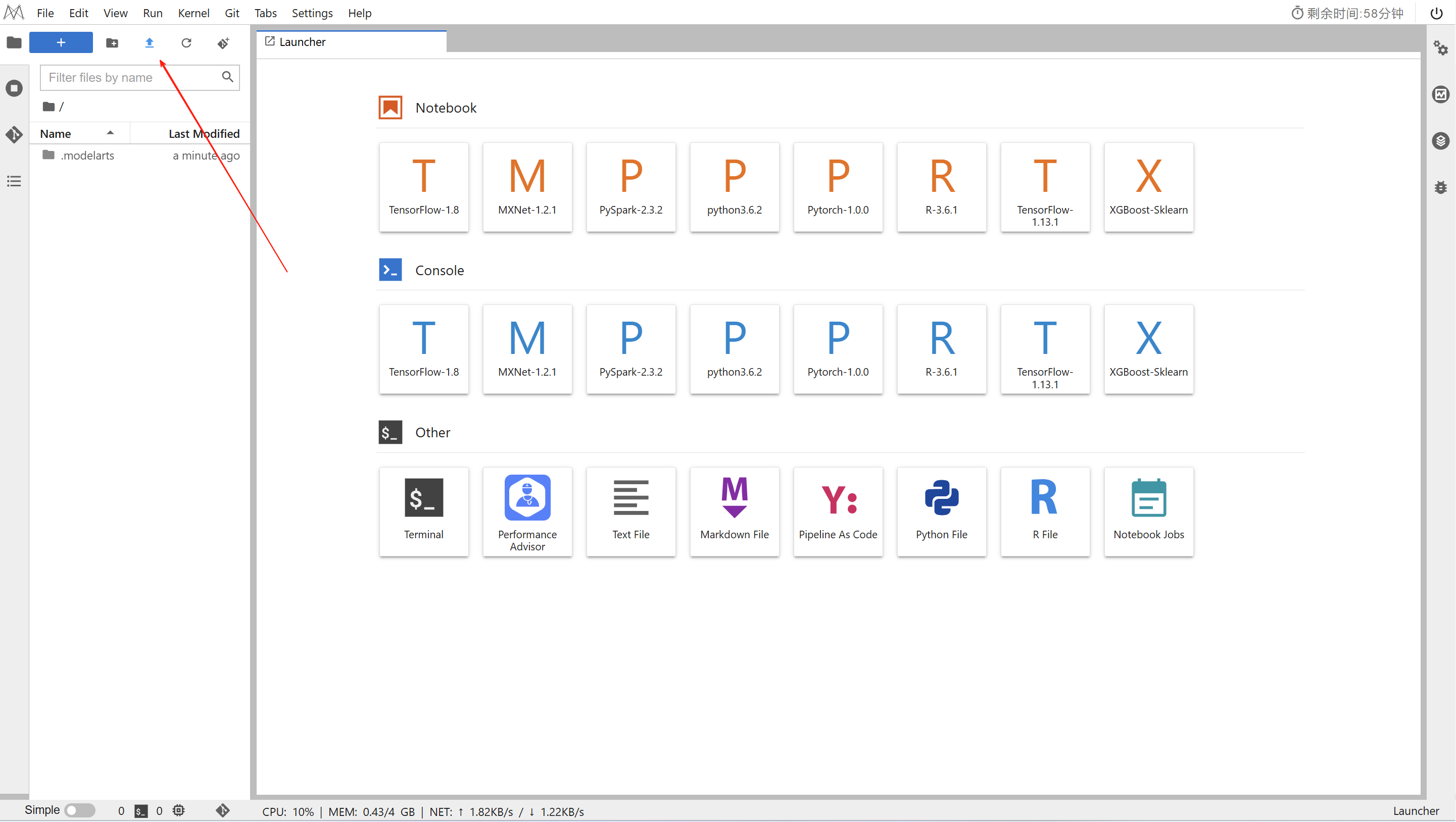
进入昇思MindSpore官网,点击上方的安装获取安装命令
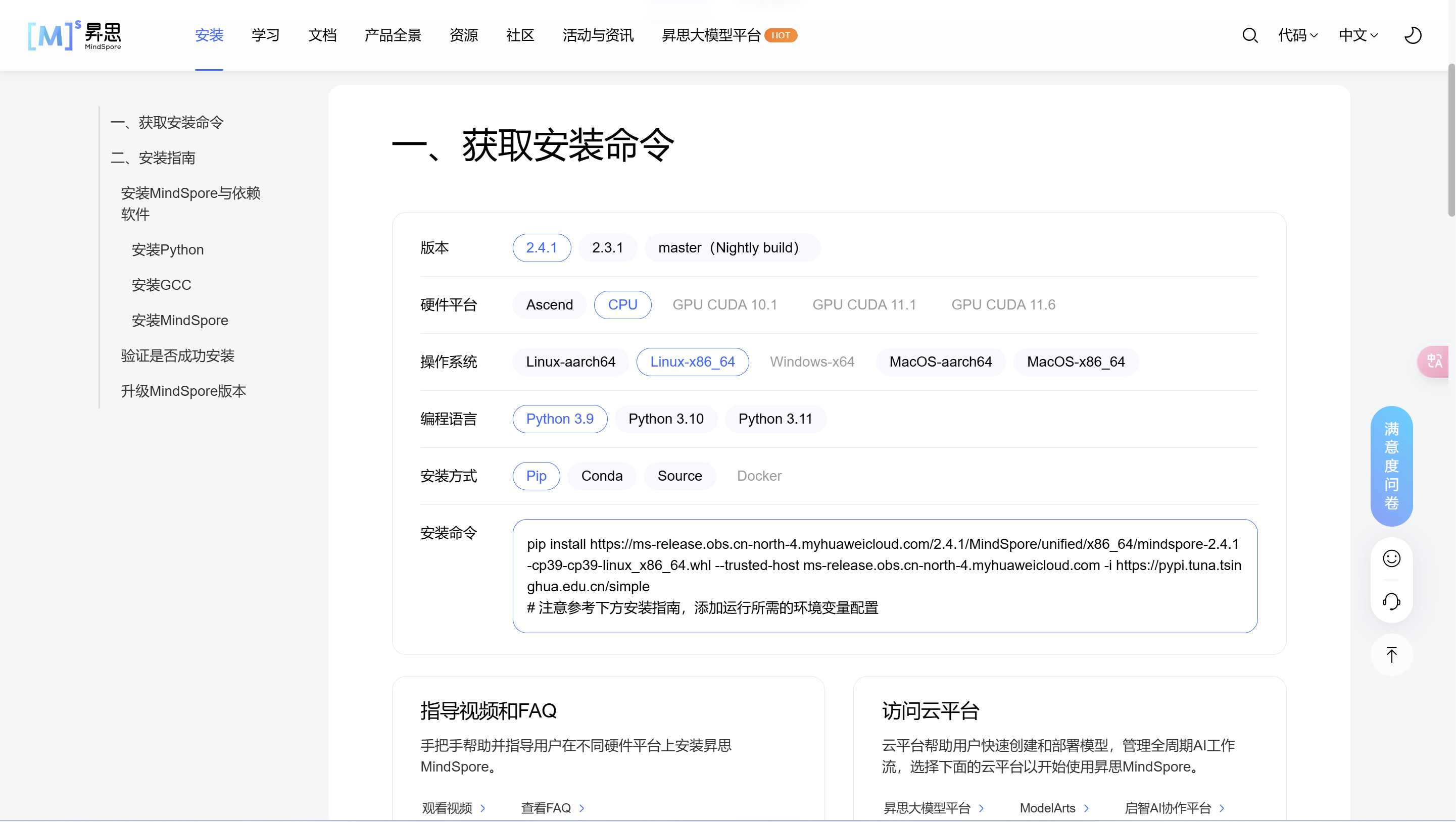
MindSpore版本升级,镜像自带的MindSpore版本为2.3,该活动要求在MindSpore2.4.0版本体验,所以需要进行MindSpore版本升级。

命令如下:
export no_proxy='a.test.com,127.0.0.1,2.2.2.2'
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.4.0/MindSpore/unified/aarch64/mindspore-2.4.0-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
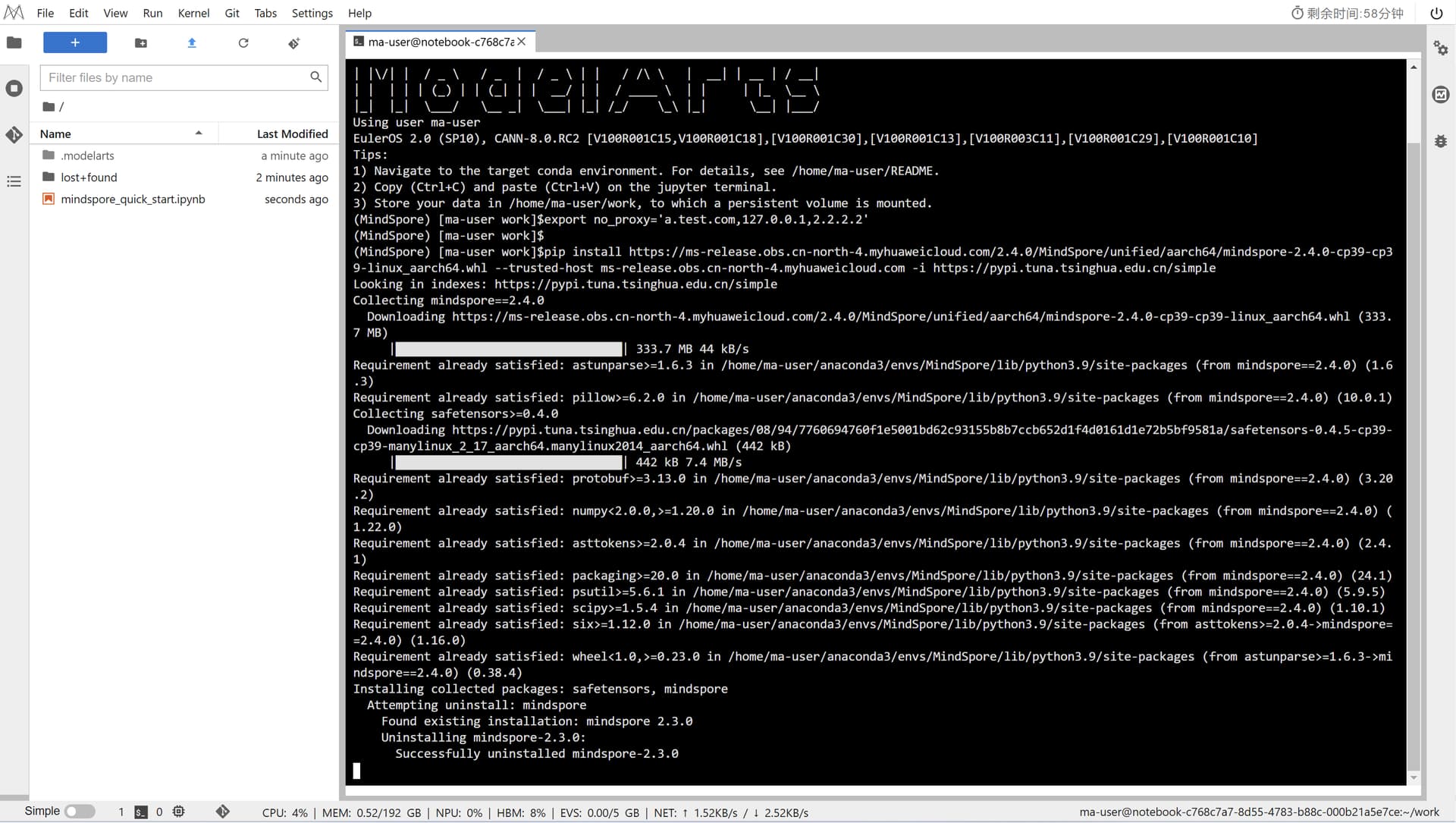
回到Notebook中,在第一块代码前加命令
pip install --upgrade pip
pip install mindvision
pip install download
2 案例实现
1. 准备工作:安装工具和下载数据
● 安装依赖:首先用!pip install download安装了一个下载工具,用于后续下载数据集。
● 下载数据集:从华为云服务器下载了CIFAR-10数据集(二进制格式,约162MB),并解压到指定文件夹./datasets-cifar10-bin。这个数据集包含10类图像(如飞机、汽车、鸟等),用于训练和测试模型。
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
download(url, "./datasets-cifar10-bin", kind="tar.gz", replace=True)

2. 数据处理:加载和预处理数据
● 加载数据:使用MindCV的工具create_dataset加载训练集和验证集,指定数据路径和拆分方式(train和test)。
● 数据预处理:对图像进行变换(如调整大小到224x224像素),并创建数据加载器(loader_train和loader_val),设置批量大小为64,方便模型批量处理数据。
import mindspore
import mindcv
import os
from mindcv.data import create_dataset, create_transforms, create_loader
cifar10_dir = './datasets-cifar10-bin/cifar-10-batches-bin' # your dataset path
num_classes = 10 # num of classes
num_workers=4
# create dataset
dataset_train = create_dataset(name='cifar10', root=cifar10_dir, split='train', shuffle=True)
# create transforms
trans = create_transforms(dataset_name='cifar10', image_resize=224)
# Perform data augmentation operations to generate the required dataset.
loader_train = create_loader(dataset=dataset_train,
batch_size=64,
is_training=True,
num_classes=num_classes,
transform=trans,
num_parallel_workers=num_workers)
num_batches = loader_train.get_dataset_size()
# Load validation dataset
dataset_val = create_dataset(
name='cifar10', root=cifar10_dir, split='test', shuffle=True, num_parallel_workers=num_workers
)
# Perform data enhancement operations to generate the required dataset.
loader_val = create_loader(dataset=dataset_val,
batch_size=64,
is_training=False,
num_classes=10,
transform=trans,
num_parallel_workers=num_workers)
images, labels = next(loader_train.create_tuple_iterator())
print("Tensor of image", images.shape)
print("Labels:", labels)
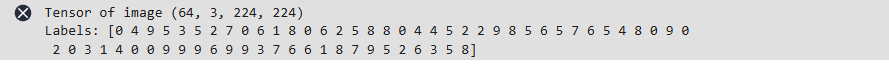
3. 构建模型:使用SqueezeNet并调整输出层
● 加载预训练模型:从MindCV导入SqueezeNet1.0模型,默认加载在ImageNet上的预训练权重(用于图像分类的经典模型,参数较少,适合小数据集微调)。
● 修改最后一层:原模型输出为1000类,但CIFAR-10只有10类,因此将最后一层卷积层修改为输出10类,适配分类任务。
from mindcv.models import create_model
network = create_model(model_name='squeezenet1_0', num_classes=1000, pretrained=True)
network

for param in network.get_parameters():
print(param.name)
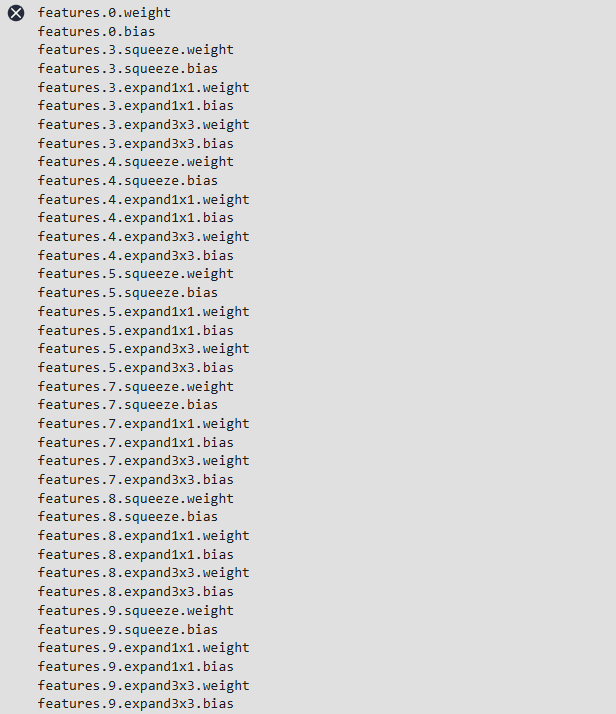
for param in network.get_parameters():
if param.name == "classifier.1.weight":
param.name = "classifier.weight"
for param in network.get_parameters():
if param.name == "classifier.1.bias":
param.name = "classifier.bias"
for param in network.get_parameters():
if param.name in ["classifier.weight", "classifier.bias"]:
print(param.name)
![]()
# Number of input features to the final layer (remains the same)
from mindspore import nn
num_features = network.classifier[1].in_channels
# Replace the final Conv2d layer
network.classifier[1] = nn.Conv2d(num_features, 10, kernel_size=1, has_bias=True)
network

for param in network.get_parameters():
print(param.name)
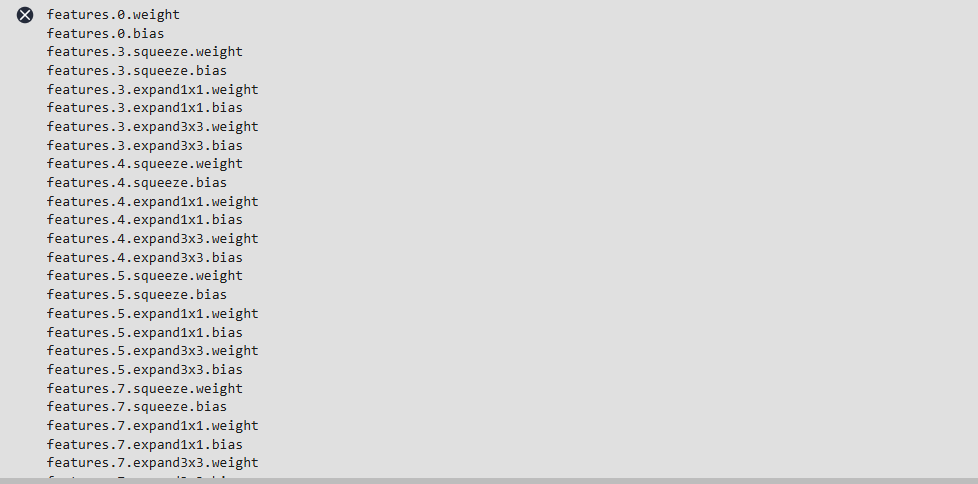
4. 训练配置:设置优化器、损失函数和回调
● 损失函数:使用交叉熵损失函数(CE),计算预测与真实标签的误差。
● 优化器:选择Adam优化器,设置学习率调度器(带热身阶段),帮助模型更稳定地学习。
● 回调函数:
○ LossMonitor:训练时每50步打印一次损失值,观察训练进度。
○ TimeMonitor:每50步打印一次耗时,监控训练速度。
○ ModelCheckpoint:每完成一个 epoch(一轮完整训练)保存一次模型参数,方便后续加载继续训练或测试。
from mindcv.loss import create_loss
loss = create_loss(name='CE')
from mindcv.scheduler import create_scheduler
# learning rate scheduler
lr_scheduler = create_scheduler(steps_per_epoch=num_batches,
warmup_epochs=5,
lr=0.0001)
from mindcv.optim import create_optimizer
# create optimizer
opt = create_optimizer(network.trainable_params(), opt='adam', lr=lr_scheduler)
from mindspore import Model
# Encapsulates examples that can be trained or inferred
model = Model(network, loss_fn=loss, optimizer=opt, metrics={'accuracy'})
5. 开始训练:迭代优化模型
● 模型训练了50个 epoch(轮次),每轮都会遍历整个训练集。训练过程中,损失值逐渐下降(从初始约2.4逐步降低到接近0.05),表明模型在学习数据模式。
● 每次迭代会输出当前 epoch、步数和损失值,最后保存训练好的模型到./ckpt文件夹。
from mindspore import LossMonitor, TimeMonitor, CheckpointConfig, ModelCheckpoint
# Set the callback function for saving network parameters during training.
ckpt_save_dir = './ckpt'
ckpt_config = CheckpointConfig(save_checkpoint_steps=num_batches)
ckpt_cb = ModelCheckpoint(prefix='squeezenet-cifar10',
directory=ckpt_save_dir,
config=ckpt_config)
model.train(50, loader_train, callbacks=[LossMonitor(num_batches//50), TimeMonitor(num_batches//50), ckpt_cb], dataset_sink_mode=False)
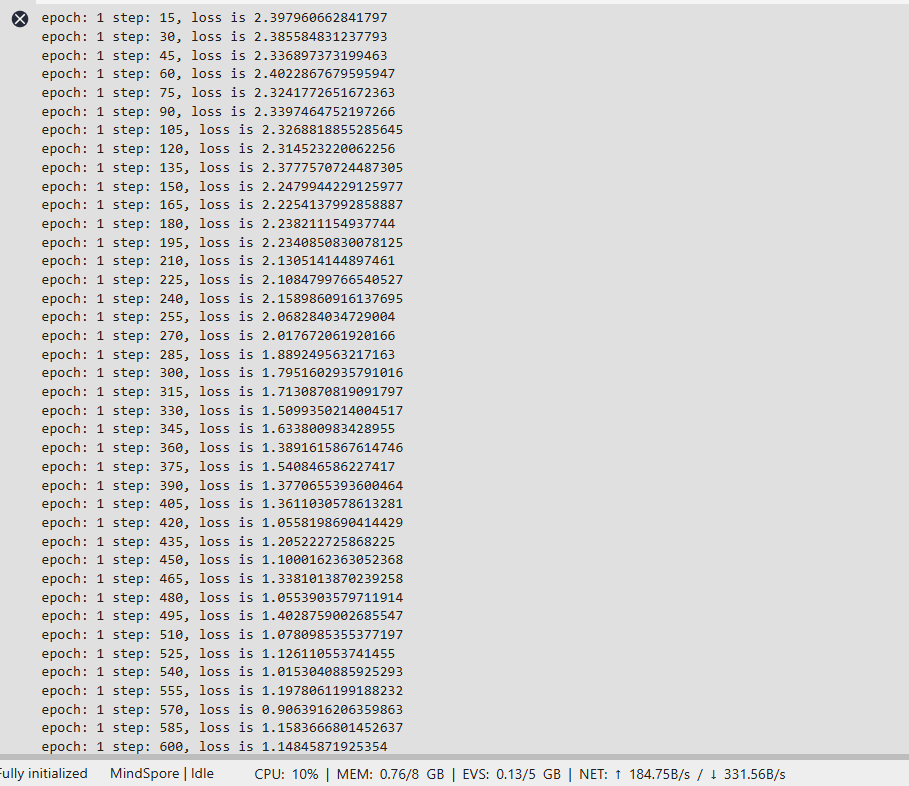
6. 模型评估:验证集上测试准确率
● 训练完成后,用验证集评估模型性能,得到准确率为90.53%,说明模型在未见数据上表现良好。
acc = model.eval(loader_val, dataset_sink_mode=False)
print(acc)
![]()
7. 可视化预测结果:直观查看预测效果
● 从验证集中随机选取15张图像,用模型预测它们的类别,并可视化结果:
○ 蓝色标签:预测正确(如预测“飞机”正确)。
○ 红色标签:预测错误(如误将“猫”预测为“狗”)。
○ 图像经过标准化处理(还原像素值范围)后显示,方便直观对比预测与真实标签。
import matplotlib.pyplot as plt
import mindspore as ms
import numpy as np
import math
def visualize_model(model, val_dl, num_classes=10):
# Load the data of the validation set for validation
images, labels = next(val_dl.create_tuple_iterator())
# Ensure only 15 images are used
images = images[:15]
labels = labels[:15]
# Predict image class
output = model.predict(images)
pred = np.argmax(output.asnumpy(), axis=1)
# Convert to numpy for visualization
images = images.asnumpy()
labels = labels.asnumpy()
# Define class names
class_name = {
0: "airplane", 1: "automobile", 2: "bird", 3: "cat", 4: "deer",
5: "dog", 6: "frog", 7: "horse", 8: "ship", 9: "truck"
}
# Set up the figure
plt.figure(figsize=(15, 7))
for i in range(15):
plt.subplot(3, 5, i + 1)
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title('Predict: {}'.format(class_name[pred[i]]), color=color)
# Image processing for display
picture_show = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
visualize_model(model, loader_val)
