带你体验mindcv (一) 主要是初步了解了mindcv的基本使用方法,下面就具体展开来讲。
首先是配置
mindcv支持命令行直接传参,也支持yaml文件配置参数,同时也支持两种混合。
相关的代码在config.py里面。
配置项包含基础环境,数据集,数据增强,模型,损失函数,learning rate策略和优化器。
就拿基础环境来举例,
命令行的参数如下:
# System parameters
group = parser.add_argument_group('System parameters')
group.add_argument('--mode', type=int, default=0,
help='Running in GRAPH_MODE(0) or PYNATIVE_MODE(1) (default=0)')
group.add_argument('--distribute', type=str2bool, nargs='?', const=True, default=False,
help='Run distribute (default=False)')
group.add_argument('--val_while_train', type=str2bool, nargs='?', const=True, default=False,
help='Verify accuracy while training (default=False)')
group.add_argument('--val_interval', type=int, default=1,
help='Interval for validation while training. Unit: epoch (default=1)')
group.add_argument('--log_interval', type=int, default=100,
help='Interval for print training log. Unit: step (default=100)')
group.add_argument('--seed', type=int, default=42,
help='Seed value for determining randomness in numpy, random, and mindspore (default=42)')
复制
yaml文件如下:
# system
mode: 0
distribute: True
num_parallel_workers: 8
复制
指定yaml文件是 -c 进行指定。
例如python train.py -c ./configs/squeezenet/squeezenet_1.0_gpu.yaml --data_dir ./data
其中使用parse设置参数可以覆盖yaml文件中的参数设置。也就是命令行参数优先级要高。
接下来讲
自定义数据集上的模型微调训练
使用MindCV套件进行迁移学习,可以解决自定义数据集上的图像分类问题。
在深度学习任务中,常见遇到训练数据不足的问题,此时直接训练整个网络往往难以达到理想的精度。
一个比较好的做法是,使用一个在大规模数据集上(与任务数据较为接近)预训练好的模型,然后使用该模型来初始化网络的权重参数或作为固定特征提取器应用于特定的任务中。
如下使用ImageNet上预训练的DenseNet模型为例,介绍两种不同的微调策略,解决小样本情况下狼和狗的图像分类问题:
- 整体模型微调。
- 冻结特征网络(freeze backbone),只微调分类器。
数据准备
下载数据集
下载案例所用到的狗与狼分类数据集, 每个类别各有120张训练图像与30张验证图像。使用mindcv.utils.download接口下载数据集,并将下载后的数据集自动解压到当前目录下。
import os
from mindcv.utils.download import DownLoad
dataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip"
root_dir = "./"
if not os.path.exists(os.path.join(root_dir, 'data/Canidae')):
DownLoad().download_and_extract_archive(dataset_url, root_dir)
复制

目录结构如下:

数据集加载及处理
自定义数据集的加载
通过调用mindcv.data中的create_dataset函数,我们可轻松地加载预设的数据集以及自定义的数据集。
- 当参数
name设为空时,指定为自定义数据集。(默认值) - 当参数
name设为MNIST,CIFAR10等标准数据集名称时,指定为预设数据集。
同时,我们需要设定数据集的路径data_dir和数据切分的名称split (如train, val),以加载对应的训练集或者验证集。
from mindcv.data import create_dataset, create_transforms, create_loader
num_workers = 8
# 数据集目录路径
data_dir = "./data/Canidae/"
# 加载自定义数据集
dataset_train = create_dataset(root=data_dir, split='train', num_parallel_workers=num_workers)
dataset_val = create_dataset(root=data_dir, split='val', num_parallel_workers=num_workers)
复制
数据处理及增强
首先通过调用create_transforms函数, 获得预设的数据处理和增强策略(transform list),此任务中,因狼狗图像和ImageNet数据一致(即domain一致),我们指定参数dataset_name为ImageNet,直接用预设好的ImageNet的数据处理和图像增强策略。create_transforms 同样支持多种自定义的处理和增强操作,以及自动增强策略(AutoAug)。详见API说明。
我们将得到的transform list传入create_loader(),并指定batch_size和其他参数,即可完成训练和验证数据的准备,返回Dataset Object,作为模型的输入。
# 定义和获取数据处理及增强操作
trans_train = create_transforms(dataset_name='ImageNet', is_training=True)
trans_val = create_transforms(dataset_name='ImageNet',is_training=False)
loader_train = create_loader(
dataset=dataset_train,
batch_size=16,
is_training=True,
num_classes=2,
transform=trans_train,
num_parallel_workers=num_workers,
)
loader_val = create_loader(
dataset=dataset_val,
batch_size=5,
is_training=True,
num_classes=2,
transform=trans_val,
num_parallel_workers=num_workers,
)
复制
数据集可视化
对于create_loader接口返回的完成数据加载的Dataset object,我们可以通过 create_tuple_iterator 接口创建数据迭代器,使用 next 迭代访问数据集,读取到一个batch的数据。
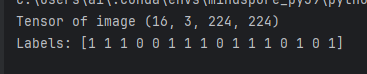
images, labels = next(loader_train.create_tuple_iterator())
print("Tensor of image", images.shape)
print("Labels:", labels)
复制
对获取到的图像及标签数据进行可视化,标题为图像对应的label名称。
import matplotlib.pyplot as plt
import numpy as np
# class_name对应label,按文件夹字符串从小到大的顺序标记label
class_name = {0: "dogs", 1: "wolves"}
plt.figure(figsize=(15, 7))
for i in range(len(labels)):
# 获取图像及其对应的label
data_image = images[i].asnumpy()
data_label = labels[i]
# 处理图像供展示使用
data_image = np.transpose(data_image, (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
data_image = std * data_image + mean
data_image = np.clip(data_image, 0, 1)
# 显示图像
plt.subplot(3, 6, i + 1)
plt.imshow(data_image)
plt.title(class_name[int(labels[i].asnumpy())])
plt.axis("off")
plt.show()
复制

数据集准备好后就可以开始模型微调了。
1. 整体模型微调
预训练模型加载
我们使用mindcv.models.densenet中定义DenseNet121网络,当接口中的pretrained参数设置为True时,可以自动下载网络权重。 由于该预训练模型是针对ImageNet数据集中的1000个类别进行分类的,这里我们设定num_classes=2, DenseNet的classifier(即最后的FC层)输出调整为两维,此时只加载backbone的预训练权重,而classifier则使用初始值。
from mindcv.models import create_model
network = create_model(model_name='densenet121', num_classes=2, pretrained=True)
复制
模型训练
使用已加载处理好的带标签的狼和狗图像,对DenseNet进行微调网络。注意,对整体模型做微调时,应使用较小的learning rate。
from mindcv.loss import create_loss
from mindcv.optim import create_optimizer
from mindcv.scheduler import create_scheduler
from mindspore import Model, LossMonitor, TimeMonitor
# 定义优化器和损失函数
opt = create_optimizer(network.trainable_params(), opt='adam', lr=1e-4)
loss = create_loss(name='CE')
# 实例化模型
model = Model(network, loss_fn=loss, optimizer=opt, metrics={'accuracy'})
model.train(10, loader_train, callbacks=[LossMonitor(5), TimeMonitor(5)], dataset_sink_mode=False)
复制

模型评估
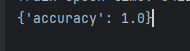
在训练完成后,我们在验证集上评估模型的精度。
res = model.eval(loader_val)
print(res)
复制
![]()
可视化模型推理结果
定义 visualize_mode 函数,可视化模型预测。
import matplotlib.pyplot as plt
import mindspore as ms
def visualize_model(model, val_dl, num_classes=2):
# 加载验证集的数据进行验证
images, labels= next(val_dl.create_tuple_iterator())
# 预测图像类别
output = model.predict(images)
pred = np.argmax(output.asnumpy(), axis=1)
# 显示图像及图像的预测值
images = images.asnumpy()
labels = labels.asnumpy()
class_name = {0: "dogs", 1: "wolves"}
plt.figure(figsize=(15, 7))
for i in range(len(labels)):
plt.subplot(3, 6, i + 1)
# 若预测正确,显示为蓝色;若预测错误,显示为红色
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title('predict:{}'.format(class_name[pred[i]]), color=color)
picture_show = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
复制
使用微调过后的模型对验证集的狼和狗图像数据进行预测。若预测字体为蓝色表示预测正确,若预测字体为红色表示预测错误。
visualize_model(model, loader_val)
复制

另外一种微调方法
2. 冻结特征网络, 微调分类器
冻结特征网络的参数
首先,我们要冻结除最后一层分类器之外的所有网络层,即将相应的层参数的requires_grad属性设置为False,使其不在反向传播中计算梯度及更新参数。
因为mindcv.models 中所有的模型均以classifier 来标识和命名模型的分类器(即Dense层),所以通过 classifier.weight 和 classifier.bias 即可筛选出分类器外的各层参数,将其requires_grad属性设置为False.
# freeze backbone
for param in network.get_parameters():
if param.name not in ["classifier.weight", "classifier.bias"]:
param.requires_grad = False
复制
微调分类器
因为特征网络已经固定,我们不必担心训练过程会distort pratrained features,因此,相比于第一种方法,我们可以将learning rate调大一些。
与没有预训练模型相比,将节约一大半时间,因为此时可以不用计算部分梯度。
# 加载数据集
dataset_train = create_dataset(root=data_dir, split='train', num_parallel_workers=num_workers)
loader_train = create_loader(
dataset=dataset_train,
batch_size=16,
is_training=True,
num_classes=2,
transform=trans_train,
num_parallel_workers=num_workers,
)
# 定义优化器和损失函数
opt = create_optimizer(network.trainable_params(), opt='adam', lr=1e-3)
loss = create_loss(name='CE')
# 实例化模型
model = Model(network, loss_fn=loss, optimizer=opt, metrics={'accuracy'})
model.train(10, loader_train, callbacks=[LossMonitor(5), TimeMonitor(5)], dataset_sink_mode=False)
复制

模型评估
训练完成之后,我们在验证集上评估模型的准确率。
dataset_val = create_dataset(root=data_dir, split='val', num_parallel_workers=num_workers)
loader_val = create_loader(
dataset=dataset_val,
batch_size=5,
is_training=True,
num_classes=2,
transform=trans_val,
num_parallel_workers=num_workers,
)
res = model.eval(loader_val)
print(res)
复制
可视化模型预测
使用微调过后的模型件对验证集的狼和狗图像数据进行预测。若预测字体为蓝色表示预测正确,若预测字体为红色表示预测错误。
visualize_model(model, loader_val)
复制

微调后的狼狗预测结果均正确,可见两种方式的效果都不错。