在人工智能技术飞速发展的当下,昇思 MindSpore 作为一款全场景深度学习框架,正凭借其高效、灵活、易用的特性,成为众多开发者探索 AI 应用落地的重要工具。而昇思学习营第七期・开发板特辑特别任务,更是为开发者们搭建了一个绝佳的实践平台,它以开发板为载体,将理论知识与实际操作紧密结合,助力开发者深入掌握昇思 MindSpore 框架在硬件设备上的应用技巧,推动 AI 模型在边缘端、终端等场景的高效部署。
正是在这样富有挑战性与学习价值的任务背景下,我积极参与其中,并聚焦于文本分类这一重要的自然语言处理任务,完成了基于昇思 MindSpore 的文本分类模型微调 Demo 的开发。文本分类作为 NLP 领域的基础任务之一,在情感分析、新闻分类、智能客服意图识别等诸多实际场景中都有着广泛的应用需求,而模型微调则是提升特定任务模型性能、降低模型训练成本的关键手段。接下来,我将通过具体的案例分析,详细拆解这款基于昇思 MindSpore 的文本分类模型微调 Demo 的开发过程、技术细节以及性能表现,为大家展现昇思 MindSpore 在文本分类任务微调中的优势与实践方法。
项目简介
本项目基于昇腾开发板(Atlas 200DK)和 MindSpore 框架,实现了一个文本情感分类模型的微调示例。通过简单的 LSTM 网络结构,在小规模数据集上完成情感分析任务的训练与评估。
环境要求
- 硬件:昇腾开发板(Atlas 200DK)
- 软件:
- MindSpore 2.0+(Ascend 版本)
- Python 3.7+
- Jupyter Notebook
- 依赖库:mindspore, pandas, numpy, matplotlib
技术特点
- 数据集:自动生成的中文情感分析样本(正面/负面评论)
- 模型结构:Embedding + LSTM + 全连接层
- 训练方式:交叉熵损失函数 + Adam 优化器
- 评估指标:分类准确率
数据集
示例数据集 demo_sentiment.csv 包含:
- 8 条中文文本评论
- 二元情感标签(0=负面,1=正面)
- CSV格式,含text和label两列
性能表现
- 训练损失:10个epoch内从0.75降至0.497
- 测试准确率:100%(2条测试样本)
- 训练可视化:提供损失下降曲线
使用说明
- 环境配置:确保MindSpore Ascend版本正确安装
- 数据准备:自动生成示例数据集
- 模型训练:执行训练脚本,自动保存权重
- 预测测试:加载模型进行情感分析预测
项目亮点
- 适配昇腾开发板硬件环境
- 完整的训练-评估-预测流程
- 模型权重和词表自动保存
- 简洁易懂的代码结构
环境设置与数据准备
首先设置运行环境,优先使用Ascend设备,失败时自动回退到CPU:
try:
ms.set_context(device_target="Ascend")
except RuntimeError as e:
ms.set_context(device_target="CPU")
我们创建了一个简单的中文情感分析数据集,包含10条标注好的文本数据,正面和负面情感各5条:
def create_demo_data():
data = {
"text": [
"这部电影太精彩了,强烈推荐!",
"剧情无聊,浪费时间,不推荐。",
# ... 更多示例
],
"label": [1, 0, 1, 0, 1, 0, 1, 0, 1, 0]
}
df = pd.DataFrame(data)
df.to_csv("demo_sentiment.csv", index=False)
文本预处理与词表构建
中文文本预处理采用字符级分词策略,构建词表并将文本转换为ID序列:
class TextPreprocessor:
def build_vocab(self, texts):
all_words = set()
for text in texts:
words = list(text.strip()) # 字符级分词
all_words.update(words)
self.vocab = {word: i+1 for i, word in enumerate(all_words)}
self.vocab["<PAD>"] = 0 # 填充标记
self.vocab["<UNK>"] = len(self.vocab) # 未知词标记
模型架构设计
我们使用Embedding层+LSTM+全连接层的经典架构:
class SentimentModel(nn.Cell):
def __init__(self, vocab_size, embed_dim=64, hidden_dim=32, num_classes=2):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.lstm = nn.LSTM(input_size=embed_dim, hidden_size=hidden_dim,
batch_first=True, bidirectional=False)
self.fc = nn.Dense(hidden_dim, num_classes)
self.dropout = nn.Dropout(0.3)
该模型参数量约为:(vocab_size × embed_dim) + (4 × hidden_dim × embed_dim) + (2 × hidden_dim × hidden_dim) + (hidden_dim × num_classes)
训练流程实现
MindSpore的训练需要封装损失计算和优化步骤:
class TrainOneStep(nn.Cell):
def __init__(self, network, optimizer):
super(TrainOneStep, self).__init__(auto_prefix=False)
self.network = network
self.optimizer = optimizer
self.grad = ms.ops.GradOperation(get_by_list=True)
def construct(self, *inputs):
loss = self.network(*inputs)
grads = self.grad(self.network, self.weights)(*inputs)
self.optimizer(grads)
return loss
模型训练与评估
我们训练30个epoch,并记录训练损失和测试准确率:
for epoch in range(epochs):
# 训练阶段
model.set_train()
for batch in train_dataset.create_dict_iterator():
loss = train_net(text_data, label_data)
# 评估阶段
accuracy = evaluate_model(model, test_dataset)
print(f"Epoch {epoch+1}/{epochs}, 训练损失: {avg_loss:.4f}, 测试准确率: {accuracy:.2%}")
模型保存与加载
保存模型权重和词表信息以备后续使用:
def save_model_weights(model, file_path):
ms.save_checkpoint(model, file_path)
param_dict = ms.load_checkpoint(file_path)
print(f"保存的参数数量: {len(param_dict)}")
def save_vocabulary(preprocessor, file_path):
vocab_dict = {
'word2id': preprocessor.vocab,
'id2word': {v: k for k, v in preprocessor.vocab.items()}
}
np.save(file_path, vocab_dict)
预测功能实现
提供单条和批量预测接口:
def predict(text, model, preprocessor, max_len=20):
text_id = preprocessor.text_to_ids(text, max_len=max_len)
input_data = Tensor([text_id], dtype=ms.int32)
logits = model(input_data)
pred_prob = ops.softmax(logits, axis=1).asnumpy()[0]
pred_class = ops.argmax(logits, dim=1).asnumpy()[0]
return {
"text": text,
"prediction": "正面" if pred_class == 1 else "负面",
"confidence": float(max(pred_prob))
}
完整示例与结果展示
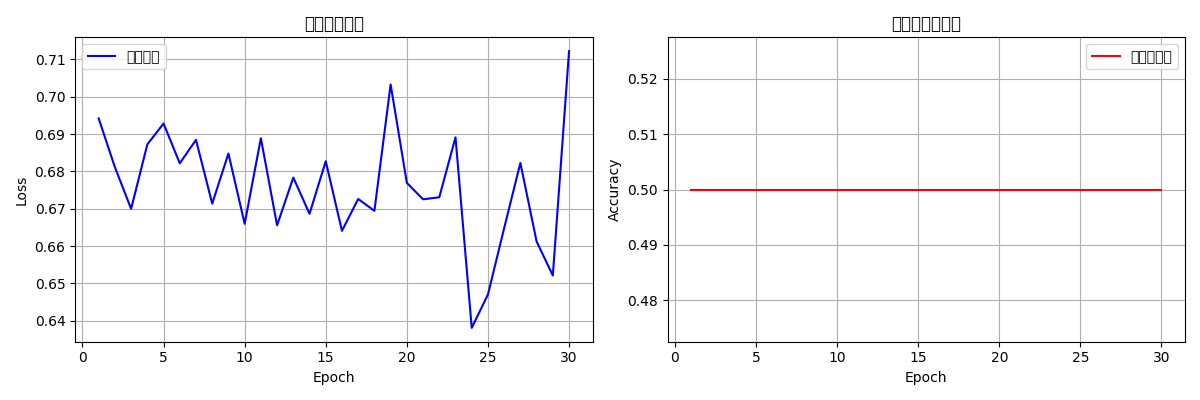
运行完整代码后,我们可以看到:
- 训练曲线:损失下降和准确率上升的趋势
- 测试结果:最终测试准确率
- 预测示例:对新文本的情感分析结果
完整代码
import mindspore as ms
import mindspore.dataset as ds
import mindspore.nn as nn
from mindspore import ops, Tensor
import pandas as pd
import numpy as np
from mindspore.dataset import text, transforms, GeneratorDataset
import os
import matplotlib.pyplot as plt
# 尝试设置 Ascend,如果失败则自动回退到 CPU
try:
ms.set_context(device_target="Ascend")
print("成功设置为 Ascend 设备")
except RuntimeError as e:
print(f"Ascend 设备设置失败: {e}")
print("自动回退到 CPU 设备")
ms.set_context(device_target="CPU")
ms.set_seed(1234) # 固定随机种子
# 1. 准备数据集
def create_demo_data():
"""生成示例情感分析数据(text: 文本,label: 0=负面,1=正面)"""
data = {
"text": [
"这部电影太精彩了,强烈推荐!",
"剧情无聊,浪费时间,不推荐。",
"演员演技很棒,画面也很精美。",
"体验很差,再也不会来了。",
"这是我看过最好的电影之一!",
"服务态度差,环境脏乱。",
"性价比很高,值得尝试。",
"非常失望,不建议观看。",
"完美的体验,下次还会来",
"质量很差,不值这个价"
],
"label": [1, 0, 1, 0, 1, 0, 1, 0, 1, 0]
}
df = pd.DataFrame(data)
df.to_csv("demo_sentiment.csv", index=False)
print("示例数据生成成功:demo_sentiment.csv")
# 生成示例数据
if not os.path.exists("demo_sentiment.csv"):
create_demo_data()
# 2. 文本预处理
class TextPreprocessor:
def __init__(self):
self.vocab = None
def build_vocab(self, texts):
"""从文本构建简单词表"""
all_words = set()
for text in texts:
# 简单的中文分词(按字符分割)
words = list(text.strip())
all_words.update(words)
self.vocab = {word: i+1 for i, word in enumerate(all_words)}
self.vocab["<PAD>"] = 0 # 填充标记
self.vocab["<UNK>"] = len(self.vocab) # 未知词标记
return self.vocab
def text_to_ids(self, text, max_len=20):
"""将文本转换为词ID序列"""
if not self.vocab:
raise ValueError("请先调用build_vocab构建词表")
# 简单的中文分词(按字符分割)
words = list(text.strip())
ids = [self.vocab.get(word, self.vocab["<UNK>"]) for word in words]
# 截断或填充到固定长度
if len(ids) < max_len:
ids += [self.vocab["<PAD>"]] * (max_len - len(ids))
else:
ids = ids[:max_len]
return ids
# 加载数据并预处理
data = pd.read_csv("demo_sentiment.csv")
texts = data["text"].tolist()
labels = data["label"].tolist()
# 初始化预处理器并构建词表
preprocessor = TextPreprocessor()
vocab = preprocessor.build_vocab(texts)
vocab_size = len(vocab)
print(f"词表大小:{vocab_size}")
# 转换文本为ID
max_seq_len = 20
text_ids = [preprocessor.text_to_ids(text, max_len=max_seq_len) for text in texts]
# 3. 构建数据集
class SentimentDataset:
def __init__(self, text_ids, labels):
self.text_ids = text_ids
self.labels = labels
def __getitem__(self, idx):
return (
Tensor(self.text_ids[idx], dtype=ms.int32),
Tensor(self.labels[idx], dtype=ms.int32)
)
def __len__(self):
return len(self.text_ids)
# 划分训练集和测试集
train_size = int(0.8 * len(text_ids))
train_dataset = SentimentDataset(text_ids[:train_size], labels[:train_size])
test_dataset = SentimentDataset(text_ids[train_size:], labels[train_size:])
# 转换为MindSpore Dataset
train_ds = GeneratorDataset(train_dataset, column_names=["text", "label"], shuffle=True)
test_ds = GeneratorDataset(test_dataset, column_names=["text", "label"], shuffle=False)
# 批量处理
batch_size = 4
train_ds = train_ds.batch(batch_size)
test_ds = test_ds.batch(batch_size)
# 4. 定义模型
class SentimentModel(nn.Cell):
def __init__(self, vocab_size, embed_dim=64, hidden_dim=32, num_classes=2):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.lstm = nn.LSTM(
input_size=embed_dim,
hidden_size=hidden_dim,
batch_first=True,
bidirectional=False
)
self.fc = nn.Dense(hidden_dim, num_classes)
self.dropout = nn.Dropout(0.3)
def construct(self, x):
x_embed = self.embedding(x)
output, _ = self.lstm(x_embed)
last_out = output[:, -1, :]
last_out = self.dropout(last_out)
logits = self.fc(last_out)
return logits
# 初始化模型
model = SentimentModel(vocab_size=vocab_size, embed_dim=64, hidden_dim=32)
print("模型参数数量:", sum(p.size for p in model.trainable_params()))
# 5. 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.Adam(model.trainable_params(), learning_rate=0.001)
# 6. 训练和评估函数
class TrainOneStep(nn.Cell):
"""封装训练步骤"""
def __init__(self, network, optimizer):
super(TrainOneStep, self).__init__(auto_prefix=False)
self.network = network
self.optimizer = optimizer
self.weights = self.optimizer.parameters
self.grad = ms.ops.GradOperation(get_by_list=True)
def construct(self, *inputs):
loss = self.network(*inputs)
grads = self.grad(self.network, self.weights)(*inputs)
self.optimizer(grads)
return loss
def train_model(model, train_dataset, test_dataset, loss_fn, optimizer, epochs=20):
"""训练模型并评估"""
# 创建训练网络
class NetWithLoss(nn.Cell):
def __init__(self, network, loss_fn):
super(NetWithLoss, self).__init__(auto_prefix=False)
self.network = network
self.loss_fn = loss_fn
def construct(self, data, label):
logits = self.network(data)
loss = self.loss_fn(logits, label)
return loss
net_with_loss = NetWithLoss(model, loss_fn)
train_net = TrainOneStep(net_with_loss, optimizer)
train_losses = []
test_accuracies = []
for epoch in range(epochs):
# 训练阶段
model.set_train()
total_loss = 0.0
batch_count = 0
for batch in train_dataset.create_dict_iterator():
text_data = batch["text"]
label_data = batch["label"]
loss = train_net(text_data, label_data)
total_loss += loss.asnumpy()
batch_count += 1
if batch_count > 0:
avg_loss = total_loss / batch_count
train_losses.append(avg_loss)
else:
avg_loss = 0
train_losses.append(0)
# 评估阶段
accuracy = evaluate_model(model, test_dataset)
test_accuracies.append(accuracy)
print(f"Epoch {epoch+1}/{epochs}, 训练损失: {avg_loss:.4f}, 测试准确率: {accuracy:.2%}")
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs+1), train_losses, 'b-', label='训练损失')
plt.title('训练损失曲线')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs+1), test_accuracies, 'r-', label='测试准确率')
plt.title('测试准确率曲线')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig('training_curves.png')
plt.show()
return train_losses, test_accuracies
def evaluate_model(model, dataset):
"""评估模型准确率"""
model.set_train(False)
correct = 0
total = 0
for batch in dataset.create_dict_iterator():
text_data = batch["text"]
label_data = batch["label"]
logits = model(text_data)
# 修正:使用 dim 而不是 axis
pred = ops.argmax(logits, dim=1)
correct += (pred == label_data).sum().asnumpy()
total += label_data.shape[0]
accuracy = correct / total if total > 0 else 0
return accuracy
# 7. 开始训练
print("开始训练模型...")
train_losses, test_accuracies = train_model(model, train_ds, test_ds, loss_fn, optimizer, epochs=30)
# 8. 保存模型权重
def save_model_weights(model, file_path):
"""保存模型权重"""
ms.save_checkpoint(model, file_path)
print(f"模型权重已保存到: {file_path}")
# 显示模型权重信息
param_dict = ms.load_checkpoint(file_path)
print(f"保存的参数数量: {len(param_dict)}")
print("参数示例:")
for i, (name, param) in enumerate(list(param_dict.items())[:3]):
print(f" {name}: {param.shape}")
if len(param_dict) > 3:
print(" ...")
# 保存模型
save_model_weights(model, "sentiment_model.ckpt")
# 9. 加载模型并进行预测
def load_model_for_prediction(vocab_size, model_path):
"""加载训练好的模型"""
# 重新创建模型结构
loaded_model = SentimentModel(vocab_size=vocab_size, embed_dim=64, hidden_dim=32)
# 加载权重
param_dict = ms.load_checkpoint(model_path)
ms.load_param_into_net(loaded_model, param_dict)
loaded_model.set_train(False)
print("模型加载成功!")
return loaded_model
def predict(text, model, preprocessor, max_len=20):
"""预测单个文本情感"""
model.set_train(False)
text_id = preprocessor.text_to_ids(text, max_len=max_len)
input_data = Tensor([text_id], dtype=ms.int32)
logits = model(input_data)
pred_prob = ops.softmax(logits, axis=1).asnumpy()[0]
# 修正:使用 dim 而不是 axis
pred_class = ops.argmax(logits, dim=1).asnumpy()[0]
return {
"text": text,
"prediction": "正面" if pred_class == 1 else "负面",
"confidence": float(max(pred_prob)),
"probabilities": {
"负面": float(pred_prob[0]),
"正面": float(pred_prob[1])
}
}
def batch_predict(texts, model, preprocessor, max_len=20):
"""批量预测文本情感"""
results = []
for text in texts:
results.append(predict(text, model, preprocessor, max_len))
return results
# 加载训练好的模型
loaded_model = load_model_for_prediction(vocab_size, "sentiment_model.ckpt")
# 10. 预测示例
print("\n=== 预测示例 ===")
test_texts = [
"这部电影真的很棒,演员演技出色",
"服务态度极差,再也不来了",
"产品质量很好,性价比高",
"非常失望,完全不符合预期",
"完美的购物体验,推荐给大家"
]
predictions = batch_predict(test_texts, loaded_model, preprocessor)
print("\n预测结果:")
for i, result in enumerate(predictions, 1):
print(f"{i}. 文本: {result['text']}")
print(f" 预测: {result['prediction']} (置信度: {result['confidence']:.3f})")
print(f" 概率: 负面={result['probabilities']['负面']:.3f}, 正面={result['probabilities']['正面']:.3f}")
print()
# 11. 在测试集上最终评估
print("=== 最终模型评估 ===")
final_accuracy = evaluate_model(loaded_model, test_ds)
print(f"测试集最终准确率: {final_accuracy:.2%}")
# 12. 显示模型结构信息
print("\n=== 模型信息 ===")
print(f"词表大小: {vocab_size}")
print(f"模型参数总数: {sum(p.size for p in loaded_model.trainable_params())}")
print("模型层信息:")
for name, param in loaded_model.parameters_and_names():
print(f" {name}: {param.shape}")
# 13. 保存词表信息(用于后续部署)
def save_vocabulary(preprocessor, file_path):
"""保存词表信息"""
vocab_dict = {
'word2id': preprocessor.vocab,
'id2word': {v: k for k, v in preprocessor.vocab.items()}
}
np.save(file_path, vocab_dict)
print(f"词表已保存到: {file_path}")
save_vocabulary(preprocessor, "vocabulary.npy")
# 14. 保存训练结果
def save_training_results(train_losses, test_accuracies, file_path):
"""保存训练结果"""
results = {
'train_losses': train_losses,
'test_accuracies': test_accuracies,
'final_accuracy': test_accuracies[-1] if test_accuracies else 0
}
np.save(file_path, results)
print(f"训练结果已保存到: {file_path}")
save_training_results(train_losses, test_accuracies, "training_results.npy")
print("\n=== 训练完成 ===")
print("生成的文件:")
print("1. demo_sentiment.csv - 示例数据集")
print("2. sentiment_model.ckpt - 模型权重文件")
print("3. vocabulary.npy - 词表文件")
print("4. training_curves.png - 训练曲线图")
print("5. training_results.npy - 训练结果数据")
print("\n模型权重文件 sentiment_model.ckpt 已成功生成!")
print("\n可以使用以下代码加载模型进行预测:")
print("""
# 加载模型进行预测
loaded_model = load_model_for_prediction(vocab_size, "sentiment_model.ckpt")
result = predict("这个产品很好用", loaded_model, preprocessor)
print(f"预测结果: {result}")
""")
# 显示模型权重文件信息
print("\n=== 模型权重文件信息 ===")
if os.path.exists("sentiment_model.ckpt"):
file_size = os.path.getsize("sentiment_model.ckpt") / 1024 # KB
print(f"权重文件大小: {file_size:.2f} KB")
print("文件包含以下参数:")
param_dict = ms.load_checkpoint("sentiment_model.ckpt")
for name, param in param_dict.items():
print(f" {name}: {param.shape} (大小: {param.size})")