问题困扰了很久,尝试过AI也无法解答,求mindspore大佬求助
采用香橙派20T上的jupyterlab
代码1:
from download import download
import os
import mindspore as ms
from mindspore.dataset import ImageFolderDataset
import mindspore.dataset.vision as transforms
from mindspore import nn, ops
from mindspore.train import LossMonitor, TimeMonitor, CheckpointConfig, ModelCheckpoint
from mindspore import train
import numpy as np
from typing import Optional, Dict
import cv2
from mindspore.nn import LossBase
# ======================
# 1. 数据集准备与预处理
# ======================
# 假设FER2013数据集已经下载并解压到本地
data_path = ‘./fer2013’ # 请替换为你的FER2013数据集路径
num_classes = 7 # FER2013有7种情绪类别
# 定义灰度图像的预处理
class ToGrayscale:
"""将3通道图像转换为1通道灰度图像(FER2013实际是单通道,但被解码为3通道)"""
def \__call_\_(self, image):
\# 由于FER2013是灰度图像,被解码为3通道(三个通道值相同),取第一个通道即可
return image\[:, :, 0:1\]
# 灰度图像的均值和标准差(根据FER2013数据集统计)
# 假设灰度值范围是0-255,归一化到-1到1,所以mean=127.5, std=127.5
mean = [127.5]
std = [127.5]
# 训练集预处理
dataset_train = ImageFolderDataset(os.path.join(data_path, “Training”), shuffle=True)
trans_train = [
transforms.Decode(), # 解码图像
transforms.Resize(48), # 调整大小为48x48
transforms.RandomHorizontalFlip(prob=0.5), # 水平翻转增强
transforms.RandomRotation(10), # 小角度旋转增强
ToGrayscale(), # 转换为1通道灰度
transforms.Normalize(mean=mean, std=std),
transforms.HWC2CHW() # 转换为CHW格式
]
dataset_train = dataset_train.map(operations=trans_train, input_columns=[“image”])
dataset_train = dataset_train.batch(batch_size=32, drop_remainder=True) # 增大batch size适应小图像
# 验证集预处理
dataset_val = ImageFolderDataset(os.path.join(data_path, “PublicTest”), shuffle=False)
trans_val = [
transforms.Decode(),
transforms.Resize(48),
ToGrayscale(),
transforms.Normalize(mean=mean, std=std),
transforms.HWC2CHW()
]
dataset_val = dataset_val.map(operations=trans_val, input_columns=[“image”])
dataset_val = dataset_val.batch(batch_size=32, drop_remainder=True)
# 获取数据集大小
step_size = dataset_train.get_dataset_size()
# ======================
# 2. 模型架构修改
# ======================
class Attention(nn.Cell):
def \__init_\_(self,
dim: int,
num_heads: int = 8,
keep_prob: float = 1.0,
attention_keep_prob: float = 1.0):
super(Attention, self).\__init_\_()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = ms.Tensor(head_dim \*\* -0.5)
self.qkv = nn.Dense(dim, dim \* 3)
self.attn_drop = nn.Dropout(p=1.0-attention_keep_prob)
self.out = nn.Dense(dim, dim)
self.out_drop = nn.Dropout(p=1.0-keep_prob)
self.attn_matmul_v = ops.BatchMatMul()
self.q_matmul_k = ops.BatchMatMul(transpose_b=True)
self.softmax = nn.Softmax(axis=-1)
def construct(self, x):
"""Attention construct."""
b, n, c = x.shape
qkv = self.qkv(x)
qkv = ops.reshape(qkv, (b, n, 3, self.num_heads, c // self.num_heads))
qkv = ops.transpose(qkv, (2, 0, 3, 1, 4))
q, k, v = ops.unstack(qkv, axis=0)
attn = self.q_matmul_k(q, k)
attn = ops.mul(attn, self.scale)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
out = self.attn_matmul_v(attn, v)
out = ops.transpose(out, (0, 2, 1, 3))
out = ops.reshape(out, (b, n, c))
out = self.out(out)
out = self.out_drop(out)
return out
class FeedForward(nn.Cell):
def \__init_\_(self,
in_features: int,
hidden_features: Optional\[int\] = None,
out_features: Optional\[int\] = None,
activation: nn.Cell = nn.GELU,
keep_prob: float = 1.0):
super(FeedForward, self).\__init_\_()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.dense1 = nn.Dense(in_features, hidden_features)
self.activation = activation()
self.dense2 = nn.Dense(hidden_features, out_features)
self.dropout = nn.Dropout(p=1.0-keep_prob)
def construct(self, x):
"""Feed Forward construct."""
x = self.dense1(x)
x = self.activation(x)
x = self.dropout(x)
x = self.dense2(x)
x = self.dropout(x)
return x
class ResidualCell(nn.Cell):
def \__init_\_(self, cell):
super(ResidualCell, self).\__init_\_()
self.cell = cell
def construct(self, x):
"""ResidualCell construct."""
return self.cell(x) + x
class TransformerEncoder(nn.Cell):
def \__init_\_(self,
dim: int,
num_layers: int,
num_heads: int,
mlp_dim: int,
keep_prob: float = 1.,
attention_keep_prob: float = 1.0,
drop_path_keep_prob: float = 1.0,
activation: nn.Cell = nn.GELU,
norm: nn.Cell = nn.LayerNorm):
super(TransformerEncoder, self).\__init_\_()
layers = \[\]
for \_ in range(num_layers):
normalization1 = norm((dim,))
normalization2 = norm((dim,))
attention = Attention(dim=dim,
num_heads=num_heads,
keep_prob=keep_prob,
attention_keep_prob=attention_keep_prob)
feedforward = FeedForward(in_features=dim,
hidden_features=mlp_dim,
activation=activation,
keep_prob=keep_prob)
layers.append(
nn.SequentialCell(\[
ResidualCell(nn.SequentialCell(\[normalization1, attention\])),
ResidualCell(nn.SequentialCell(\[normalization2, feedforward\]))
\])
)
self.layers = nn.SequentialCell(layers)
def construct(self, x):
"""Transformer construct."""
return self.layers(x)
class PatchEmbedding(nn.Cell):
MIN_NUM_PATCHES = 4
def \__init_\_(self,
image_size: int = 48, # 修改为FER2013的尺寸
patch_size: int = 8, # 修改patch size为8,这样有(48/8)^2=36个patch
embed_dim: int = 256, # 适当减小embed_dim
input_channels: int = 1): # 修改为1通道(灰度图像)
super(PatchEmbedding, self).\__init_\_()
self.image_size = image_size
self.patch_size = patch_size
self.num_patches = (image_size // patch_size) \*\* 2
self.conv = nn.Conv2d(input_channels, embed_dim, kernel_size=patch_size, stride=patch_size, has_bias=True)
def construct(self, x):
"""Path Embedding construct."""
x = self.conv(x)
b, c, h, w = x.shape
x = ops.reshape(x, (b, c, h \* w))
x = ops.transpose(x, (0, 2, 1))
return x
from mindspore.common.initializer import Normal
from mindspore.common.initializer import initializer
from mindspore import Parameter
def init(init_type, shape, dtype, name, requires_grad):
"""Init."""
initial = initializer(init_type, shape, dtype).init_data()
return Parameter(initial, name=name, requires_grad=requires_grad)
class ViT(nn.Cell):
def \__init_\_(self,
image_size: int = 48, # FER2013图像尺寸
input_channels: int = 1, # 灰度图像,1通道
patch_size: int = 6, # 适合小图像的patch size
embed_dim: int = 96, # 适当减小
num_layers: int = 6, # 减少层数以适应小数据集
num_heads: int = 8, # 减少头数
mlp_dim: int = 384, # 减小mlp维度
keep_prob: float = 0.8, # 增加dropout防止过拟合
attention_keep_prob: float = 0.9,
drop_path_keep_prob: float = 0.9,
activation: nn.Cell = nn.GELU,
norm: Optional\[nn.Cell\] = nn.LayerNorm,
pool: str = 'cls',
num_classes: int = 7) -> None: # 修改为7类情绪
super(ViT, self).\__init_\_()
self.patch_embedding = PatchEmbedding(image_size=image_size,
patch_size=patch_size,
embed_dim=embed_dim,
input_channels=input_channels)
num_patches = self.patch_embedding.num_patches
self.cls_token = init(init_type=Normal(sigma=0.02),
shape=(1, 1, embed_dim),
dtype=ms.float32,
name='cls',
requires_grad=True)
self.pos_embedding = init(init_type=Normal(sigma=0.02),
shape=(1, num_patches + 1, embed_dim),
dtype=ms.float32,
name='pos_embedding',
requires_grad=True)
self.pool = pool
self.pos_dropout = nn.Dropout(p=1.0-keep_prob)
self.norm = norm((embed_dim,))
self.transformer = TransformerEncoder(dim=embed_dim,
num_layers=num_layers,
num_heads=num_heads,
mlp_dim=mlp_dim,
keep_prob=keep_prob,
attention_keep_prob=attention_keep_prob,
drop_path_keep_prob=drop_path_keep_prob,
activation=activation,
norm=norm)
self.dropout = nn.Dropout(p=1.0-keep_prob)
self.dense = nn.Dense(embed_dim, num_classes)
def construct(self, x):
"""ViT construct."""
x = self.patch_embedding(x)
cls_tokens = ops.tile(self.cls_token.astype(x.dtype), (x.shape\[0\], 1, 1))
x = ops.concat((cls_tokens, x), axis=1)
x += self.pos_embedding
x = self.pos_dropout(x)
x = self.transformer(x)
x = self.norm(x)
x = x\[:, 0\]
if self.training:
x = self.dropout(x)
x = self.dense(x)
return x
# ======================
# 3. 训练配置与执行
# ======================
# 定义超参数
epoch_size = 50 # 增加训练轮次
momentum = 0.9
lr_max = 0.0001 # 适当减小学习率
# 从头开始训练(不加载ImageNet预训练权重,因为输入尺寸和通道数不同)
network = ViT(
image_size=48,
input_channels=1,
patch_size=6,
embed_dim=96, # 减小embed_dim便于小数据集
num_layers=6, # 保持层数
num_heads=8, # embed_dim(128)必须能被num_heads(8)整除 (128/8=16)
mlp_dim=384, # 4 \* embed_dim (4\*128=512)
keep_prob=0.8,
attention_keep_prob=0.9,
num_classes=num_classes
)
# 定义学习率(使用余弦退火)
lr = nn.cosine_decay_lr(min_lr=float(0),
max_lr=lr_max,
total_step=epoch_size \* step_size,
step_per_epoch=step_size,
decay_epoch=epoch_size)
# 定义优化器
network_opt = nn.Adam(network.trainable_params(), lr, momentum)
# 定义损失函数(num_classes=7)
class CrossEntropySmooth(LossBase):
"""CrossEntropy with label smoothing."""
def \__init_\_(self, sparse=True, reduction='mean', smooth_factor=0.1, num_classes=7):
super(CrossEntropySmooth, self).\__init_\_()
self.onehot = ops.OneHot()
self.sparse = sparse
self.on_value = ms.Tensor(1.0 - smooth_factor, ms.float32)
self.off_value = ms.Tensor(1.0 \* smooth_factor / (num_classes - 1), ms.float32)
self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction)
def construct(self, logit, label):
if self.sparse:
label = self.onehot(label, ops.shape(logit)\[1\], self.on_value, self.off_value)
loss = self.ce(logit, label)
return loss
network_loss = CrossEntropySmooth(sparse=True,
reduction="mean",
smooth_factor=0.1,
num_classes=num_classes)
# 设置检查点
ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size, keep_checkpoint_max=10)
ckpt_callback = ModelCheckpoint(prefix=‘emotion_vit’, directory=‘./emotion_ckpt’, config=ckpt_config)
# 初始化模型
ascend_target = (ms.get_context(“device_target”) == “Ascend”)
if ascend_target:
model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O2")
else:
model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O0")
# 训练模型
print(“Starting training…”)
model.train(epoch_size,
dataset_train,
callbacks=\[ckpt_callback, LossMonitor(100), TimeMonitor(100)\],
dataset_sink_mode=False)
# ======================
# 4. 模型评估
# ======================
# 评估模型
print(“Evaluating model…”)
result = model.eval(dataset_val)
print(f"Validation result: {result}")
# ======================
# 5. 推理与可视化
# ======================
# 定义情绪类别
emotion_classes = [‘angry’, ‘disgust’, ‘fear’, ‘happy’, ‘neutral’, ‘sad’, ‘surprise’]
def index2emotion():
"""Dictionary for mapping index to emotion category."""
mapping = {}
for index, emotion in enumerate(emotion_classes):
mapping\[index\] = emotion
return mapping
# 推理数据集预处理
dataset_infer = ImageFolderDataset(os.path.join(data_path, “PrivateTest”), shuffle=True)
trans_infer = [
transforms.Decode(),
transforms.Resize(48),
ToGrayscale(),
transforms.Normalize(mean=mean, std=std),
transforms.HWC2CHW()
]
dataset_infer = dataset_infer.map(operations=trans_infer,
input_columns=\["image"\],
num_parallel_workers=1)
dataset_infer = dataset_infer.batch(1)
# 可视化函数(简化版)
def show_emotion_result(img_path, result, out_file=None):
"""Display emotion prediction result on image."""
img = cv2.imread(img_path)
emotion, confidence = list(result.items())\[0\]
\# 在图像上显示预测结果
cv2.putText(img, f"Emotion: {emotion}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 255, 0), 2)
cv2.putText(img, f"Confidence: {confidence:.2f}", (10, 60), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 255, 0), 2)
if out_file:
cv2.imwrite(out_file, img)
print(f"Result saved to {out_file}")
\# 显示图像(可选)
cv2.imshow("Emotion Detection", img)
cv2.waitKey(1000) # 显示1秒
cv2.destroyAllWindows()
# 进行推理
print(“Running inference on test images…”)
for i, data in enumerate(dataset_infer.create_dict_iterator(output_numpy=True)):
if i >= 5: # 只测试前5张图片
break
image = data\["image"\]
img_path = data\["image_path"\]\[0\].decode() # 假设数据集中有image_path字段
\# 进行预测
image_tensor = ms.Tensor(image)
prob = model.predict(image_tensor)
probabilities = ops.softmax(prob)\[0\].asnumpy()
\# 获取最高概率的类别
label = np.argmax(probabilities)
confidence = probabilities\[label\]
mapping = index2emotion()
output = {mapping\[label\]: confidence}
print(f"Image {i+1}: {output}")
\# 显示结果
show_emotion_result(img_path, output,
out_file=f"./emotion_result\_{i}.jpg")
print(“Emotion detection completed!”)
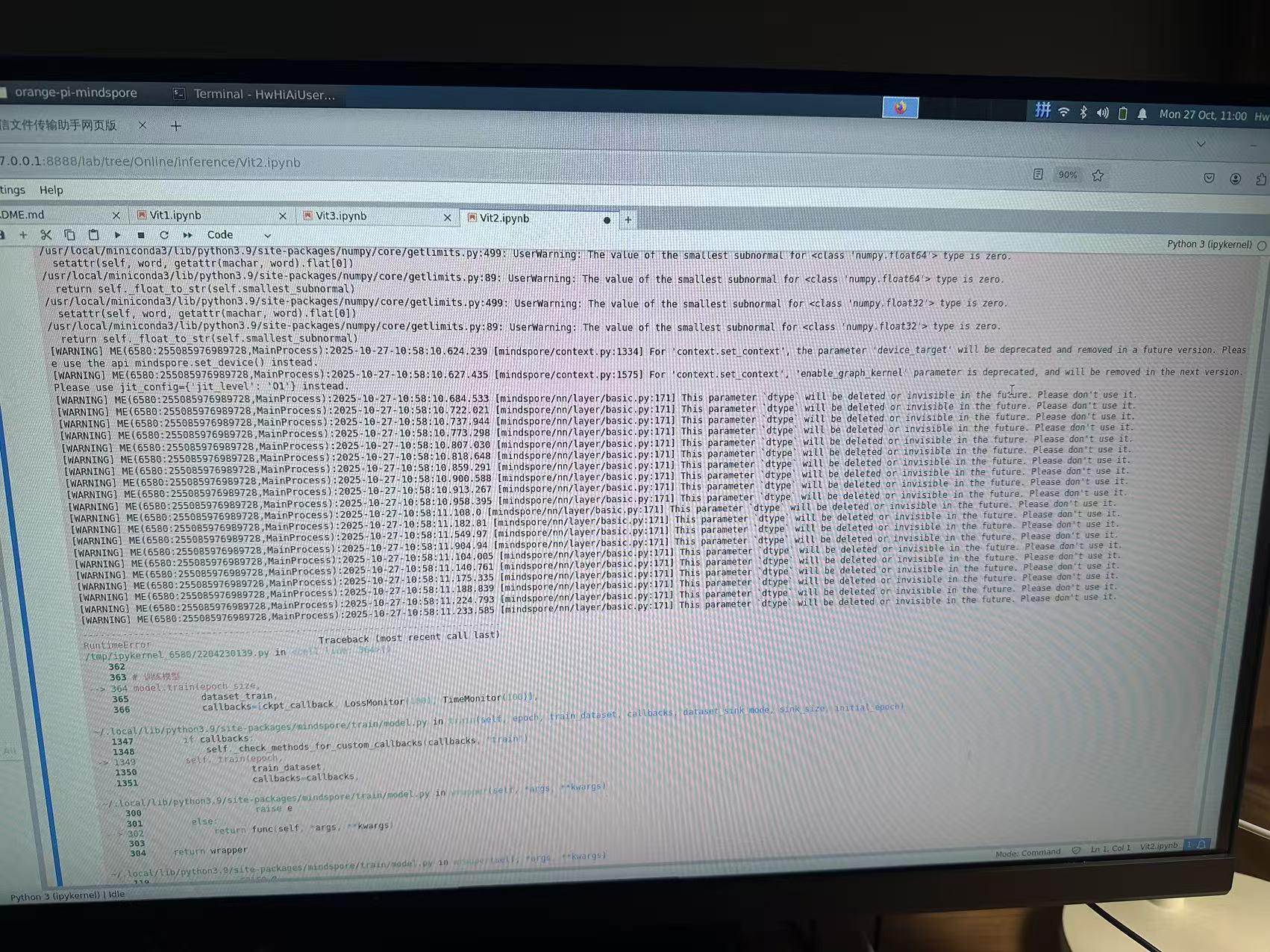
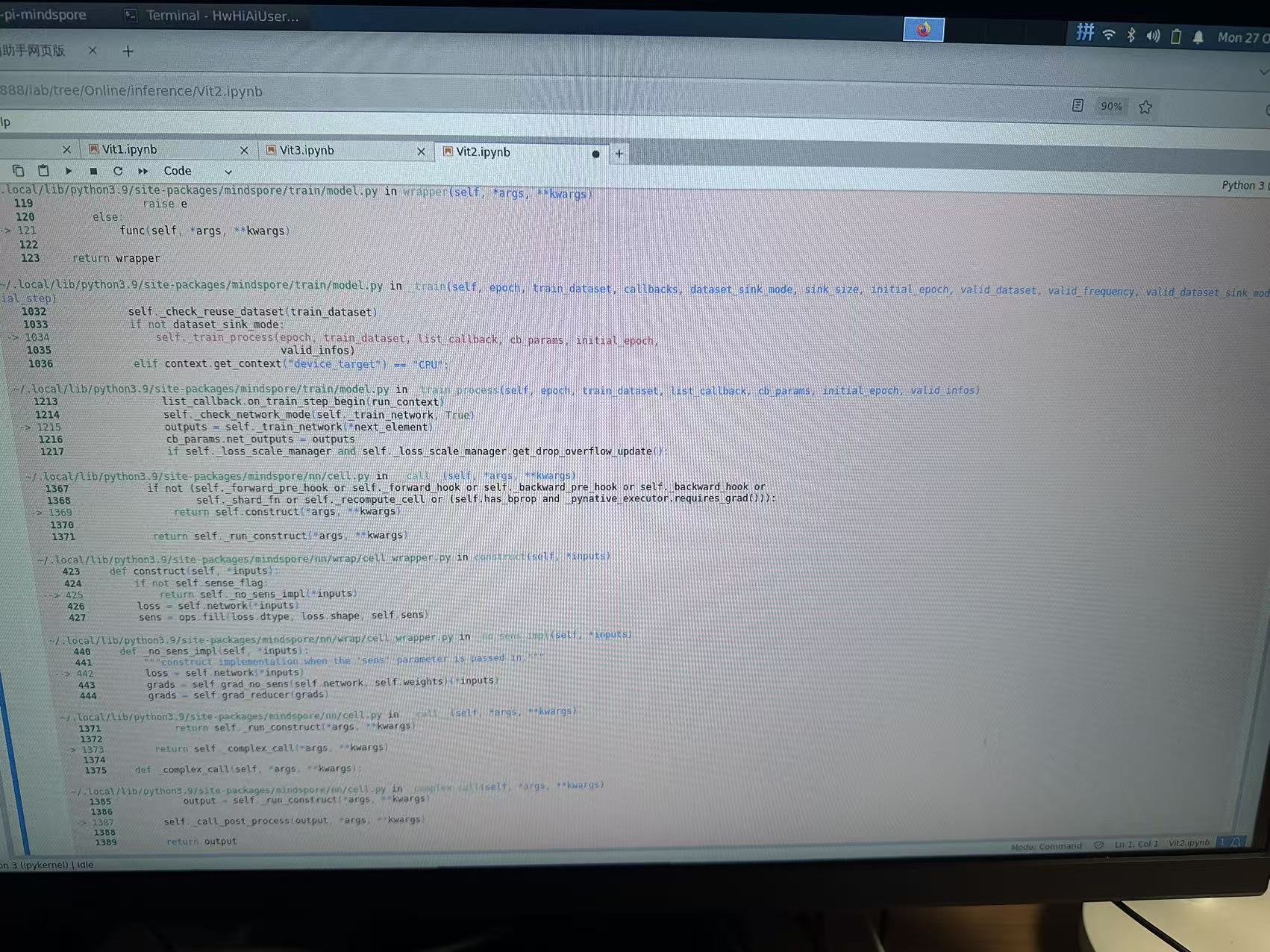
报错显示如下:
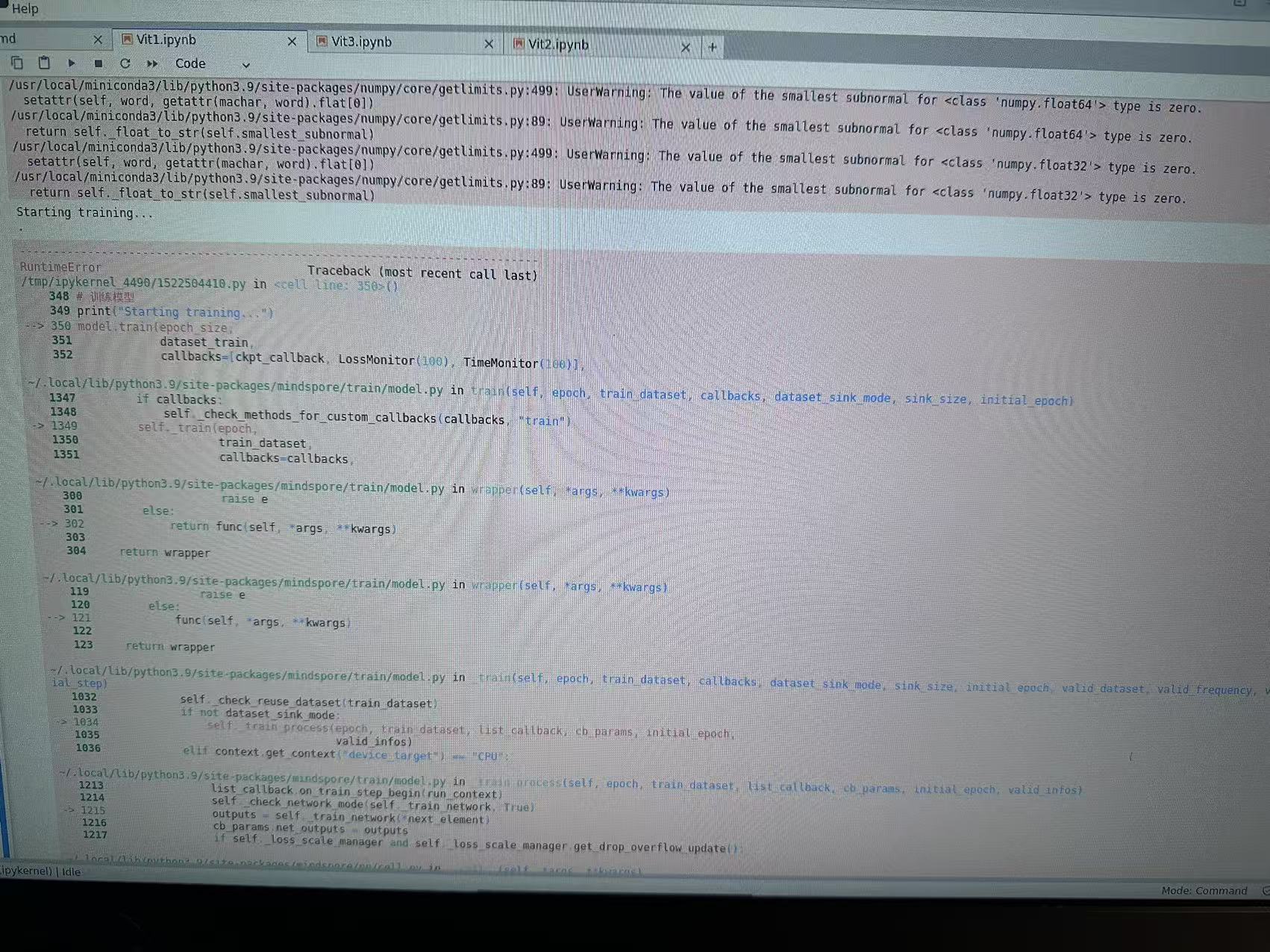
代码2如下
from download import download
import os
import mindspore as ms
from mindspore.dataset import ImageFolderDataset
import mindspore.dataset.vision as transforms
from mindspore import nn, ops
from typing import Optional, Dict
import numpy as np
from mindspore.train import LossMonitor, TimeMonitor, CheckpointConfig, ModelCheckpoint
from mindspore import train
from enum import Enum
from PIL import Image
import cv2
from mindspore.dataset.transforms import TypeCast
# ======================
# 1. 上下文设置
# ======================
ms.set_context(device_target=“Ascend”,
enable_graph_kernel=False)
# ======================
# 2. 数据集路径修改
# ======================
data_path = ‘./fer2013/’ # 修改为FER2013数据集路径
# ======================
# 3. 数据预处理修改
# ======================
image_size = 48
input_channels = 1 # 灰度图像只有1个通道
num_classes = 7 # FER2013有7种表情类别
mean = [0.5]
std = [0.5]
# 训练集预处理
dataset_train = ImageFolderDataset(os.path.join(data_path, “Training”), shuffle=True)
trans_train = [
transforms.Decode(),
transforms.ToPIL(),
transforms.Resize(image_size),
transforms.Grayscale(num_output_channels=1),
transforms.RandomHorizontalFlip(prob=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std),
TypeCast("float16") # 改为float16
]
dataset_train = dataset_train.map(operations=trans_train, input_columns=[“image”])
dataset_train = dataset_train.batch(batch_size=64, drop_remainder=True)
# 验证集预处理
dataset_val = ImageFolderDataset(os.path.join(data_path, “PrivateTest”), shuffle=False)
trans_val = [
transforms.Decode(),
transforms.ToPIL(),
transforms.Resize(image_size),
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std),
TypeCast("float16") # 改为float16
]
dataset_val = dataset_val.map(operations=trans_val, input_columns=[“image”])
dataset_val = dataset_val.batch(batch_size=64, drop_remainder=True)
# 推理集预处理
dataset_infer = ImageFolderDataset(os.path.join(data_path, “PublicTest”), shuffle=True)
trans_infer = [
transforms.Decode(),
transforms.ToPIL(),
transforms.Resize(image_size),
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std),
TypeCast("float16") # 改为float16
]
dataset_infer = dataset_infer.map(operations=trans_infer,
input_columns=\["image"\],
num_parallel_workers=1)
dataset_infer = dataset_infer.batch(1)
# ======================
# 4. 模型结构修改
# ======================
class Attention(nn.Cell):
def \__init_\_(self,
dim: int,
num_heads: int = 8,
keep_prob: float = 1.0,
attention_keep_prob: float = 1.0):
super(Attention, self).\__init_\_()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = ms.Tensor(head_dim \*\* -0.5, dtype=ms.float16) # 改为float16
self.qkv = nn.Dense(dim, dim \* 3, has_bias=True, dtype=ms.float16) # 改为float16
self.attn_drop = nn.Dropout(p=1.0-attention_keep_prob, dtype=ms.float16) # 改为float16
self.out = nn.Dense(dim, dim, has_bias=True, dtype=ms.float16) # 改为float16
self.out_drop = nn.Dropout(p=1.0-keep_prob, dtype=ms.float16) # 改为float16
self.attn_matmul_v = ops.BatchMatMul()
self.q_matmul_k = ops.BatchMatMul(transpose_b=True)
self.softmax = nn.Softmax(axis=-1)
def construct(self, x):
x = x.astype(ms.float16) # 改为float16
b, n, c = x.shape
qkv = self.qkv(x)
qkv = ops.reshape(qkv, (b, n, 3, self.num_heads, c // self.num_heads))
qkv = ops.transpose(qkv, (2, 0, 3, 1, 4))
q, k, v = ops.unstack(qkv, axis=0)
attn = self.q_matmul_k(q, k)
attn = ops.mul(attn, self.scale)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
out = self.attn_matmul_v(attn, v)
out = ops.transpose(out, (0, 2, 1, 3))
out = ops.reshape(out, (b, n, c))
out = self.out(out)
out = self.out_drop(out)
return out
class FeedForward(nn.Cell):
def \__init_\_(self,
in_features: int,
hidden_features: Optional\[int\] = None,
out_features: Optional\[int\] = None,
activation: nn.Cell = nn.GELU,
keep_prob: float = 1.0):
super(FeedForward, self).\__init_\_()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.dense1 = nn.Dense(in_features, hidden_features, has_bias=True, dtype=ms.float16) # 改为float16
self.activation = activation()
self.dense2 = nn.Dense(hidden_features, out_features, has_bias=True, dtype=ms.float16) # 改为float16
self.dropout = nn.Dropout(p=1.0-keep_prob, dtype=ms.float16) # 改为float16
def construct(self, x):
x = x.astype(ms.float16) # 改为float16
x = self.dense1(x)
x = self.activation(x)
x = self.dropout(x)
x = self.dense2(x)
x = self.dropout(x)
return x
class ResidualCell(nn.Cell):
def \__init_\_(self, cell):
super(ResidualCell, self).\__init_\_()
self.cell = cell
def construct(self, x):
return self.cell(x) + x
class TransformerEncoder(nn.Cell):
def \__init_\_(self,
dim: int,
num_layers: int,
num_heads: int,
mlp_dim: int,
keep_prob: float = 1.,
attention_keep_prob: float = 1.0,
drop_path_keep_prob: float = 1.0,
activation: nn.Cell = nn.GELU,
norm: nn.Cell = nn.LayerNorm):
super(TransformerEncoder, self).\__init_\_()
layers = \[\]
for \_ in range(num_layers):
normalization1 = norm((dim,))
normalization2 = norm((dim,))
attention = Attention(dim=dim,
num_heads=num_heads,
keep_prob=keep_prob,
attention_keep_prob=attention_keep_prob)
feedforward = FeedForward(in_features=dim,
hidden_features=mlp_dim,
activation=activation,
keep_prob=keep_prob)
layers.append(
nn.SequentialCell(\[
ResidualCell(nn.SequentialCell(\[normalization1, attention\])),
ResidualCell(nn.SequentialCell(\[normalization2, feedforward\]))
\])
)
self.layers = nn.SequentialCell(layers)
def construct(self, x):
return self.layers(x)
class PatchEmbedding(nn.Cell):
MIN_NUM_PATCHES = 4
def \__init_\_(self,
image_size: int = 48,
patch_size: int = 8,
embed_dim: int = 256,
input_channels: int = 1):
super(PatchEmbedding, self).\__init_\_()
self.image_size = image_size
self.patch_size = patch_size
self.num_patches = (image_size // patch_size) \*\* 2
self.conv = nn.Conv2d(input_channels, embed_dim, kernel_size=patch_size,
stride=patch_size, has_bias=True, pad_mode="pad", dtype=ms.float16) # 改为float16
def construct(self, x):
x = x.astype(ms.float16) # 改为float16
x = self.conv(x)
b, c, h, w = x.shape
x = ops.reshape(x, (b, c, h \* w))
x = ops.transpose(x, (0, 2, 1))
return x
from mindspore.common.initializer import Normal
from mindspore.common.initializer import initializer
from mindspore import Parameter
def init(init_type, shape, dtype, name, requires_grad):
initial = initializer(init_type, shape, dtype).init_data()
return Parameter(initial, name=name, requires_grad=requires_grad)
class ViT(nn.Cell):
def \__init_\_(self,
image_size: int = 48,
input_channels: int = 1,
patch_size: int = 8,
embed_dim: int = 256,
num_layers: int = 6,
num_heads: int = 8,
mlp_dim: int = 512,
keep_prob: float = 0.8,
attention_keep_prob: float = 0.9,
drop_path_keep_prob: float = 0.9,
activation: nn.Cell = nn.GELU,
norm: Optional\[nn.Cell\] = nn.LayerNorm,
pool: str = 'cls') -> None:
super(ViT, self).\__init_\_()
self.patch_embedding = PatchEmbedding(image_size=image_size,
patch_size=patch_size,
embed_dim=embed_dim,
input_channels=input_channels)
num_patches = self.patch_embedding.num_patches
self.cls_token = init(init_type=Normal(sigma=1.0),
shape=(1, 1, embed_dim),
dtype=ms.float16, # 改为float16
name='cls',
requires_grad=True)
self.pos_embedding = init(init_type=Normal(sigma=1.0),
shape=(1, num_patches + 1, embed_dim),
dtype=ms.float16, # 改为float16
name='pos_embedding',
requires_grad=True)
self.pool = pool
self.pos_dropout = nn.Dropout(p=1.0-keep_prob, dtype=ms.float16) # 改为float16
self.norm = norm((embed_dim,))
self.transformer = TransformerEncoder(dim=embed_dim,
num_layers=num_layers,
num_heads=num_heads,
mlp_dim=mlp_dim,
keep_prob=keep_prob,
attention_keep_prob=attention_keep_prob,
drop_path_keep_prob=drop_path_keep_prob,
activation=activation,
norm=norm)
self.dropout = nn.Dropout(p=1.0-keep_prob, dtype=ms.float16) # 改为float16
self.dense = nn.Dense(embed_dim, num_classes, has_bias=True, dtype=ms.float16) # 改为float16
def construct(self, x):
x = x.astype(ms.float16) # 改为float16
x = self.patch_embedding(x)
cls_tokens = ops.tile(self.cls_token.astype(ms.float16), (x.shape\[0\], 1, 1)) # 改为float16
x = ops.concat((cls_tokens, x), axis=1)
x += self.pos_embedding.astype(ms.float16) # 改为float16
x = self.pos_dropout(x)
x = self.transformer(x)
x = self.norm(x)
x = x\[:, 0\]
if self.training:
x = self.dropout(x)
x = self.dense(x)
return x
# ======================
# 5. 训练参数修改
# ======================
epoch_size = 5
momentum = 0.9
resize = image_size
step_size = dataset_train.get_dataset_size()
# 构建模型
network = ViT()
# 手动将模型参数转换为float16
for param in network.get_parameters():
param.set_data(param.data.astype(ms.float16)) # 改为float16
# 定义学习率
lr = nn.cosine_decay_lr(min_lr=float(0),
max_lr=0.0001,
total_step=epoch_size \* step_size,
step_per_epoch=step_size,
decay_epoch=epoch_size)
# 定义优化器
network_opt = nn.Adam(network.trainable_params(), lr, momentum)
# 定义损失函数
class CustomCrossEntropy(nn.LossBase):
def \__init_\_(self, sparse=True, reduction='mean', smooth_factor=0.1, num_classes=7):
super(CustomCrossEntropy, self).\__init_\_(reduction)
self.sparse = sparse
self.smooth_factor = smooth_factor
self.num_classes = num_classes
self.reduction = reduction
self.log_softmax = nn.LogSoftmax(axis=1)
self.nll_loss = nn.NLLLoss(reduction=reduction)
def construct(self, logits, labels):
logits = logits.astype(ms.float16) # 改为float16
if self.sparse:
on_value = ms.Tensor(1.0 - self.smooth_factor, ms.float16) # 改为float16
off_value = ms.Tensor(self.smooth_factor / (self.num_classes - 1), ms.float16) # 改为float16
labels = ops.one_hot(labels, self.num_classes, on_value, off_value)
labels = ops.argmax(labels, dim=1).astype(ms.int32)
log_probs = self.log_softmax(logits)
loss = self.nll_loss(log_probs, labels)
return loss
network_loss = CustomCrossEntropy(sparse=True,
reduction="mean",
smooth_factor=0.1,
num_classes=num_classes)
# 设置检查点
ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size, keep_checkpoint_max=10)
ckpt_callback = ModelCheckpoint(prefix=‘vit_fer2013’, directory=‘./fer2013_ViT’, config=ckpt_config)
# 初始化模型
ascend_target = (ms.get_context(“device_target”) == “Ascend”)
model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={“acc”}, amp_level=“O0”)
# 训练模型
model.train(epoch_size,
dataset_train,
callbacks=\[ckpt_callback, LossMonitor(100), TimeMonitor(100)\],
dataset_sink_mode=False)
# ======================
# 6. 评估模型
# ======================
network = ViT()
network_loss = CustomCrossEntropy(sparse=True,
reduction="mean",
smooth_factor=0.1,
num_classes=num_classes)
eval_metrics = {‘Top_1_Accuracy’: train.Top1CategoricalAccuracy(),
'Top_5_Accuracy': train.Top5CategoricalAccuracy()}
model = train.Model(network, loss_fn=network_loss, metrics=eval_metrics, amp_level=“O0”)
# 加载最佳模型
import glob
ckpt_files = glob.glob(‘./fer2013_ViT/vit_fer2013-*.ckpt’)
if ckpt_files:
best_ckpt = max(ckpt_files, key=os.path.getctime)
print(f"Loading best checkpoint: {best_ckpt}")
param_dict = ms.load_checkpoint(best_ckpt)
ms.load_param_into_net(network, param_dict)
else:
print("No checkpoint found, using randomly initialized model")
# 评估模型
result = model.eval(dataset_val)
print(“Evaluation results:”, result)
# ======================
# 7. 推理和可视化
# ======================
os.makedirs(“./fer2013_results”, exist_ok=True)
for i, image_data in enumerate(dataset_infer.create_dict_iterator(output_numpy=True)):
if i >= 5:
break
image = image_data\["image"\]
image_tensor = ms.Tensor(image)
prob = model.predict(image_tensor)
probabilities = prob.asnumpy()\[0\]
label = np.argmax(probabilities)
confidence = probabilities\[label\]
mapping = {
0: "angry",
1: "disgust",
2: "fear",
3: "happy",
4: "sad",
5: "surprise",
6: "neutral"
}
class_name = mapping\[label\]
output = {class_name: f"{confidence:.2f}"}
print(f"Image {i+1}: Predicted class: {class_name}, Confidence: {confidence:.2f}")
try:
img_path = image_data\["image_path"\]\[0\].decode('utf-8')
except (KeyError, IndexError):
img_path = f"fer2013_infer\_{i}.jpg"
out_path = f"./fer2013_results/predicted\_{os.path.basename(img_path)}"
img = cv2.imread(img_path)
if img is None:
continue
if len(img.shape) == 2:
img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
elif img.shape\[2\] == 1:
img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
elif img.shape\[2\] == 3:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
cv2.putText(img, f"{class_name}: {confidence:.2f}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
cv2.imwrite(out_path, cv2.cvtColor(img, cv2.COLOR_RGB2BGR))
print(f"Saved result to {out_path}")
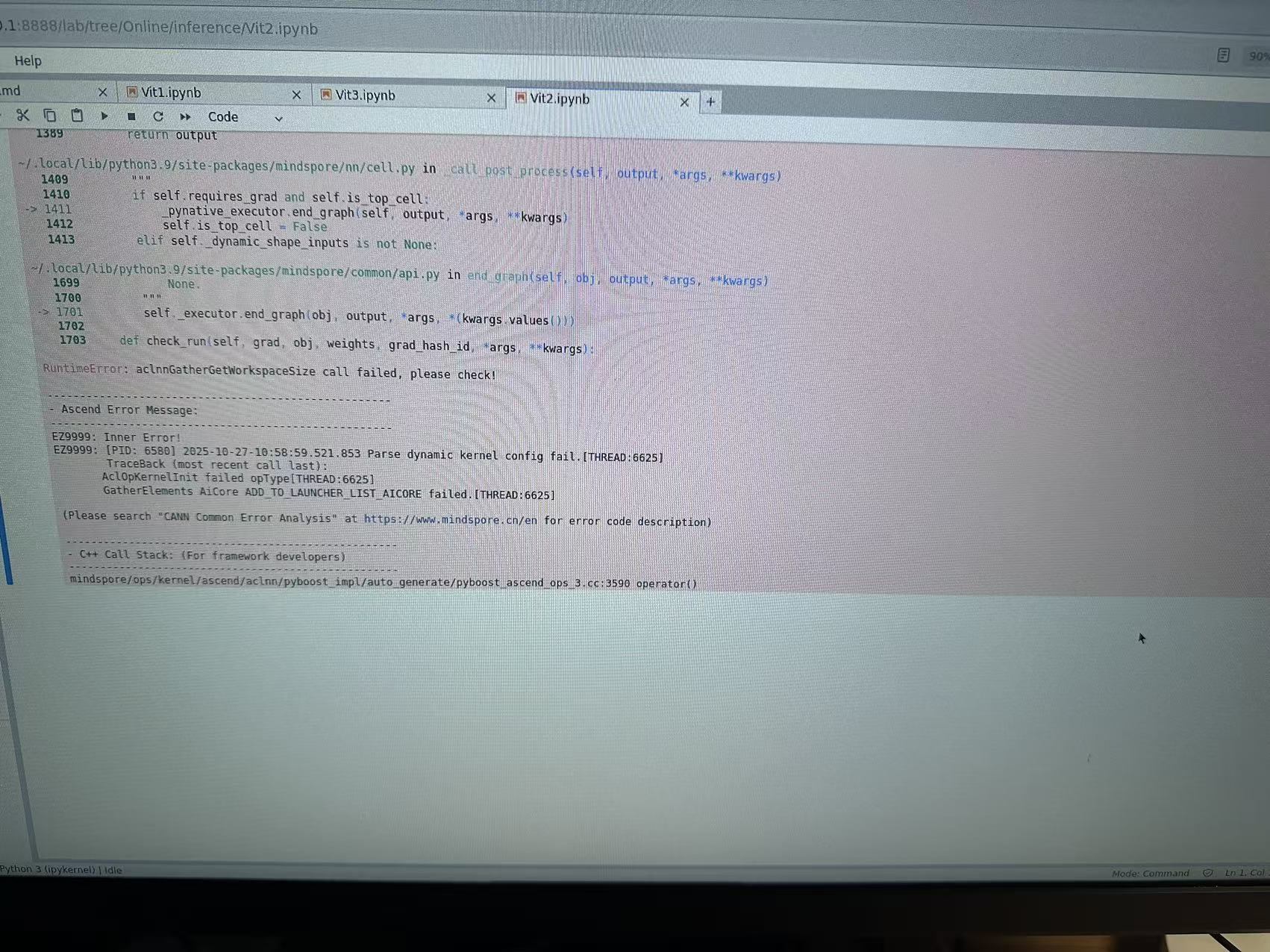
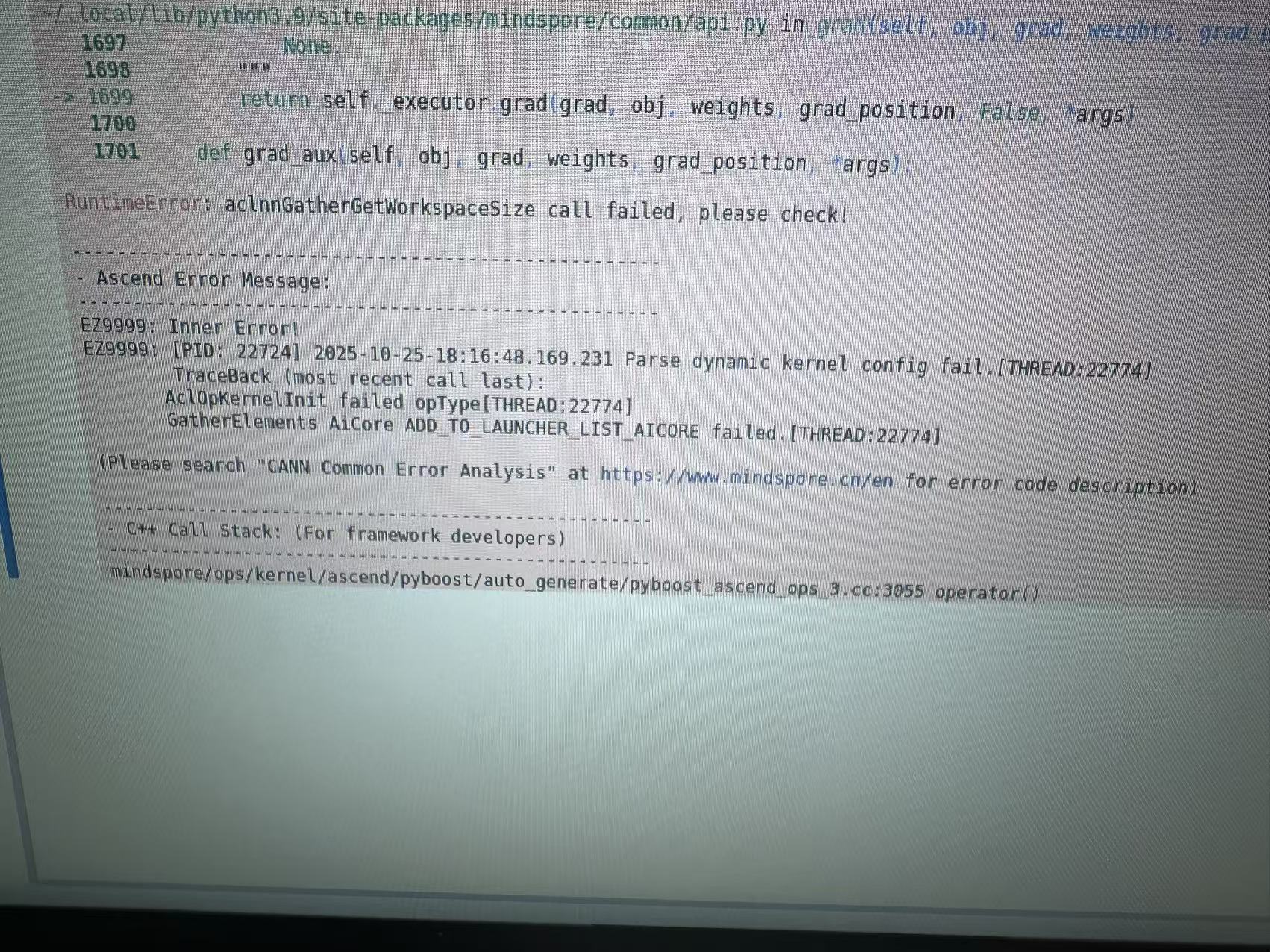
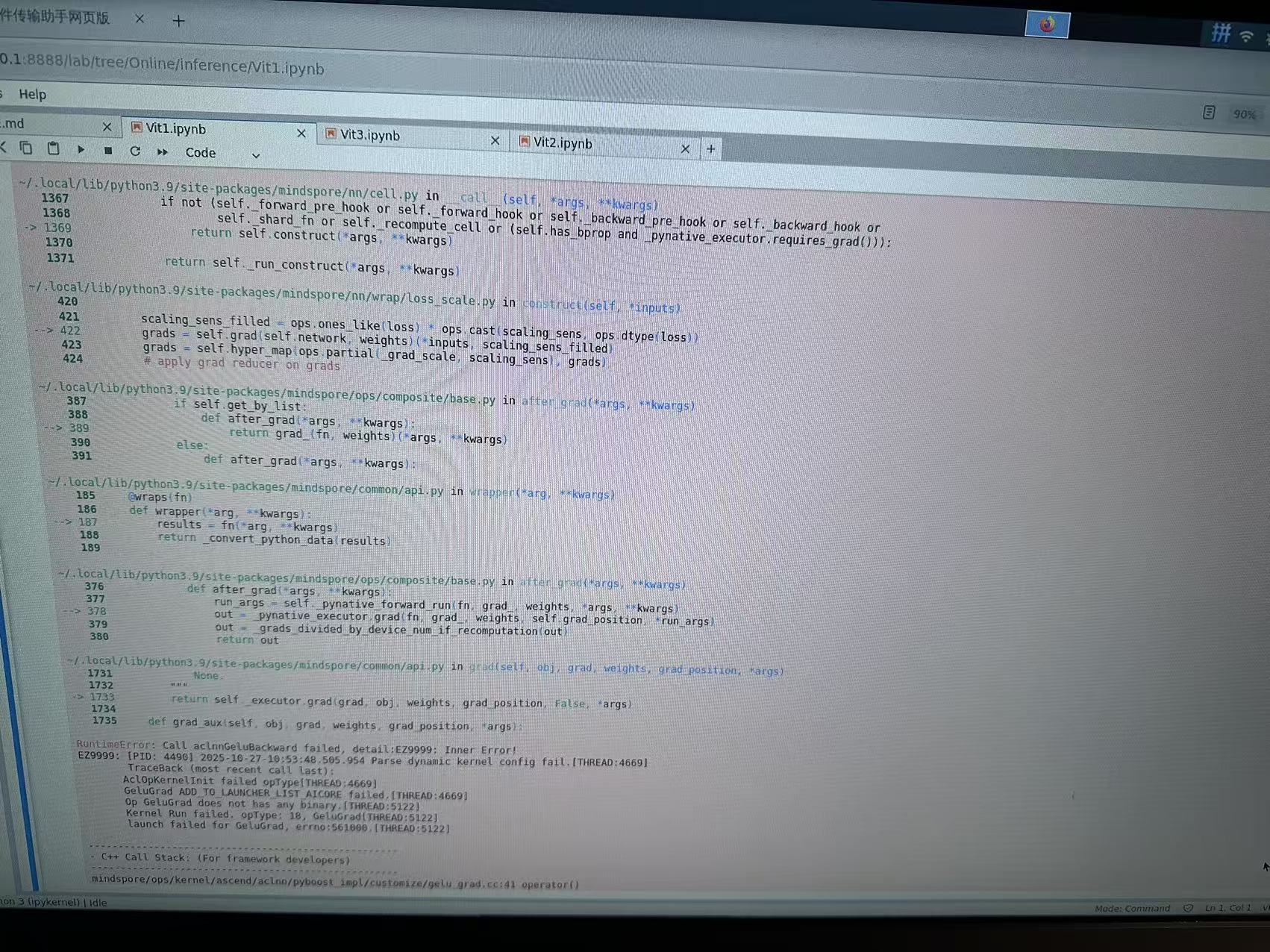
报错如下