1 系统环境
硬件环境(Ascend/GPU/CPU): Ascend/GPU/CPU
MindSpore版本: mindspore=2.2.0
执行模式(PyNative/ Graph):不限
Python版本: Python=3.7
操作系统平台: 不限
2 报错信息
2.1问题描述
使用MindSpore读取数据报错RuntimeError:Exception thrown from dataset pipeline. Refer to ‘Dataset Pipline Error Message’.
2.2 脚本代码
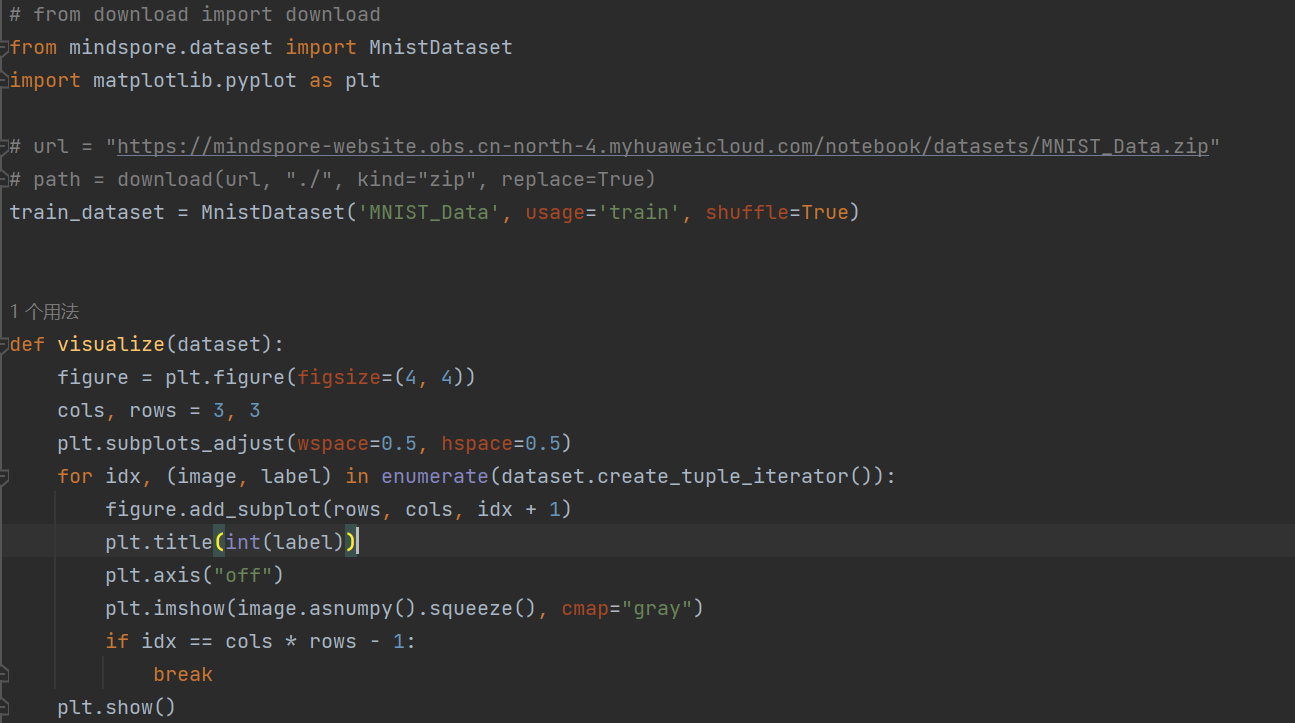
3 根因分析
step1:开启pdb,单步执行,确认报错位置:
python -m pdb test.py
报错位置为dataset.create_tuple_iterator()
step2:在mindspore.cn搜索接口文档
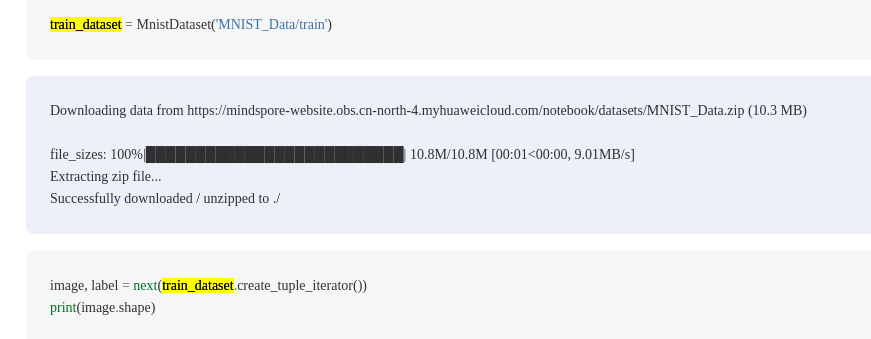
从示例上可以看到:创建数据集时,首要指定train或者test子目录; 当前脚本只指定MNIST_Data目录,接口调用报错
4 解决方案
将MnistDataset入参从’MNIST_Data’改为’MNIST_Data/train’
train_dataset = MnistDataset('MNIST_Data/train', usage='train', shuffle=True)
修改后的脚本如下:
from mindspore.dataset import MnistDataset
import matplotlib.pyplot as plt
# train_dataset = MnistDataset('MNIST_Data', usage='train', shuffle=True)
train_dataset = MnistDataset('MNIST_Data/train', usage='train', shuffle=True)
def visualize(dataset):
figure = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):
figure.add_subplot(rows, cols, idx + 1)
plt.title(int(label))
plt.axis("off")
plt.imshow(image.asnumpy().squeeze(), cmap="gray")
if idx == cols + rows - 1:
break
plt.show()
visualize(train_dataset)