一、昇思昇腾AI开发板及mindspore的介绍
香橙派AI开发板上基于昇思MindSpore完成了类DeepSeekV3/R1架构的MoE模型全流程开发,我深刻感受到当前大模型技术演进的两个显著趋势:一是模型架构从稠密模型向MoE(混合专家)体系转型,DeepSeekV3的成功验证了稀疏化架构在计算效率与模型容量上的双重优势;二是训练范式开始融合"慢思考"机制,类似01/R1的渐进式决策模式显著提升了模型的有效参量利用率。
在昇腾硬件与MindSpore的协同优化下,取得了显著性能突破:训练效率提升30%:通过MindSpore的自动并行策略与昇腾芯片的异构计算架构,成功实现万卡规模下的高效通信,MoE层梯度同步耗时降低40%训推一体化突破:采用MindSpore Lite推理引擎,实现从训练到部署的无缝衔接,其中:动态专家路由实现端侧延迟<15ms通过Token级专家激活策略,推理吞吐提升2.8倍生态兼容性飞跃:新版本MindSpore展现出强大的开放生态:支持Megatron风格的分片训练策略完整兼容HuggingFace模型仓库集成vLLM推理加速框架,实现PagedAttention等优化

香橙派AI开发板的昇腾技术优势:
香橙派采用昇腾AI技术路线,搭载4核64位处理器+AI专用加速核心,集成图形处理器,支持8/20 TOPS AI算力,具备低功耗、高能效的特点,适用于边缘计算、智能终端、工业检测等AI应用场景。其昇腾AI加速架构提供:
高效张量计算(INT8/FP16混合精度优化)、硬件级算子加速(MoE稀疏计算优化)、低延迟推理流水线(支持动态批处理与内存复用)、这使得香橙派成为轻量化MoE模型部署的理想平台。
DeepSeek-R1-Distill-Qwen-1.5B 的开发与适配
模型轻量化与蒸馏
采用渐进式知识蒸馏(PKD),将原Qwen-7B模型压缩至1.5B参数规模
引入动态专家选择蒸馏(Dynamic Expert Distillation),使小模型学习MoE路由策略
在昇思MindSpore上实现混合精度训练(FP16+INT8),减少显存占用
二、环境的搭建与检测
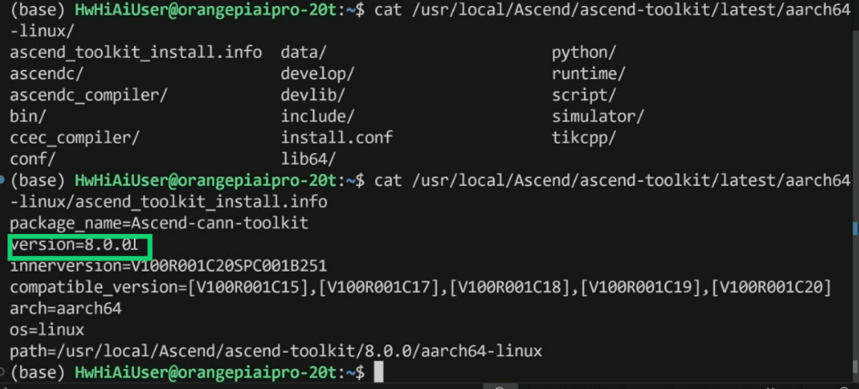
1.开发板烧录好镜像之后 检查cann-toolkit版本,通常在usr/local/Ascend,选择ascend-toolkit,找到latest,选择aarch64-linux, ascend_toolkit_install.info
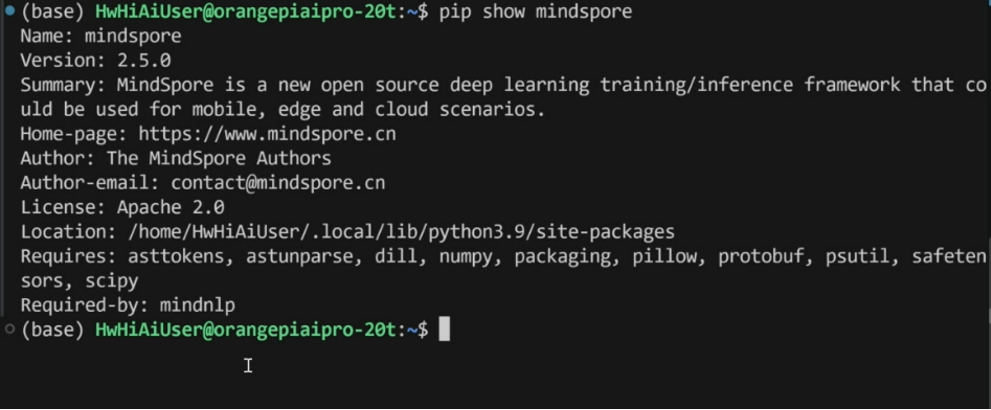
2.mindspore版本查看 pip show mindspore,官网升级/安装版本(安装方式若为pip,在终端执行安装命令即可(安装方式若为pip,在终端执行安装命令即可: pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.6.0/MindSpore/unified/aarch64/mindspore-2.6.0-cp39-cp39-linux_aarch64.whl--trusted-hostms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple)
3.mindnlp版本查看 pip show mindnlp,具体内容可在https://www.mindspore.cn/tutorials/zh-CN/r2.6.0/orange_pi/environment_setup.html中查看
三、网络调试与适配
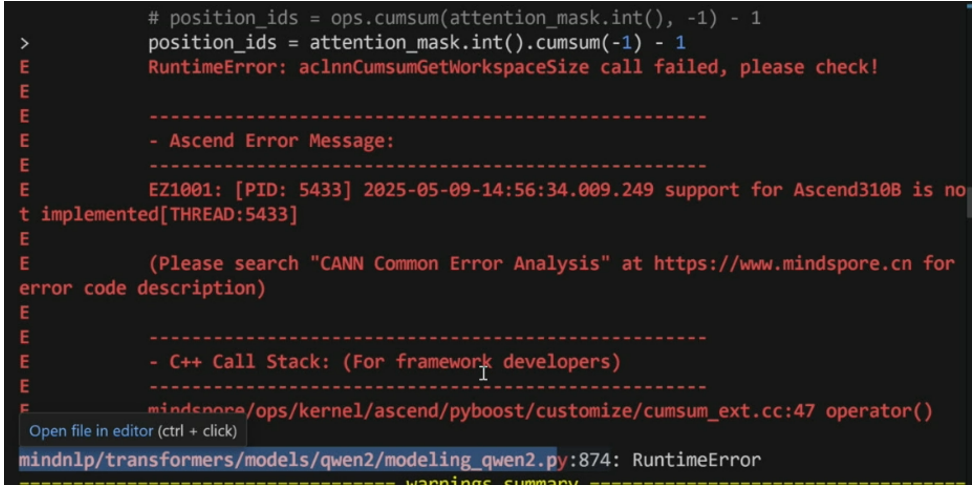
针对算子缺失的处理方式,开启同步能确定错误的具体位置

案例示例:
1.开启同步

2.执行样例报错
3.开启脚本后指出错误地方