01 Host Bound:大模型时代的隐形性能杀手**
AI框架传统KBK(KernelByKernel)模式下,框架需逐个串行下发算子,运行时对动态shape网络每个算子的调度需经历三个关键阶段:
- InferShape:计算输出Shape、更新算子属性
- Resize:执行Tiling计算、动态内存大小重计算
- Launch:kernel下发、内存管理

整个过程存在几十微秒的框架开销。当遇到以下场景时,host调度时间远超device执行时间,导致device侧产生大量气泡,算力浪费严重:
-
小算子密集网络: 大量element-wise、reshape等轻量算子
-
**大模型推理:**小batch size、短序列长度场景
-
动态Shape执行**:**频繁的形状推导与内存重分配
通过对典型网络训练和推理进行profiling分析,昇思团队识别出三个关键瓶颈点:
-
框架逻辑串行:KernelRunner需完成输入数据准备、内存申请、算子下发、内存释放,全流程串行执行;CPU和NPU算子也是串行调度。
-
**动态shape开销:**额外增加InferShape、Resize等步骤,进一步拉大算子下发间隙。
-
下发瓶颈:host侧算子Launch时间大于Device算子执行时间。
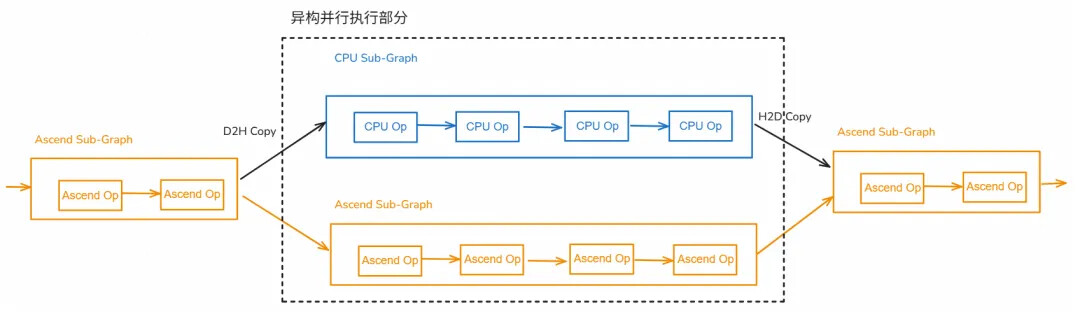
02 异构并行:CPU×NPU协同计算的"双引擎"**
异构并行 范式中,把计算图切分成CPU子图 和NPU子图 ,二者如果不存在数据依赖则可以昇思异构并行运行时支持同时下发、同时执行这些子图,实现host device并行计算。
2.1 子图切分
编译期基于用户配置的CPU算子标签,把计算图切分成CPU子图和NPU子图 ,CPU子图主要包含 动态shape小算子、NPU不支持的算子;NPU子图主要包含 保持高算力密集计算算子。
2.2 子图并发
CPU子图和NPU子图会编排成SuperKernelActor, 利用Actor天然并发执行能力,从线程池中分配线程并发执行SuperKernelActor,实现host device并行计算。
03 异步下发:框架与算子的优雅解耦**
针对框架逻辑串行问题,昇思MindSpore提出异步下发机制,将框架逻辑与算子逻辑优雅解耦。
核心设计原理
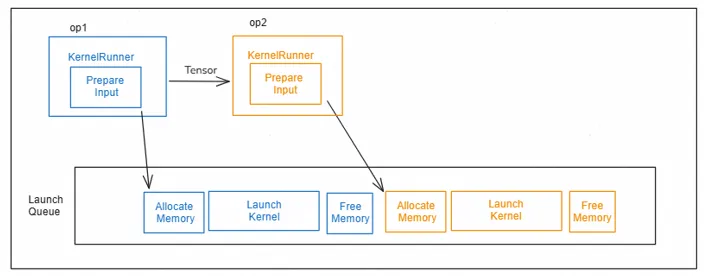
KernelRunner职责精简: 仅保留输入数据准备核心职责,确保框架开销最小化。
异步Task打包: KernelRunner完成算子输入数据准备后,将内存申请、算子下发、内存释放三大耗时操作打包成异步task,快速推入Launch Queue,由后台线程异步消费。这种设计将框架开销通过流水完美掩盖。
内存安全保证: 为不影响内存复用效果,内存申请和释放必须在同一线程内先后完成,否则可能导致内存释放延后,引起内存峰值上涨。
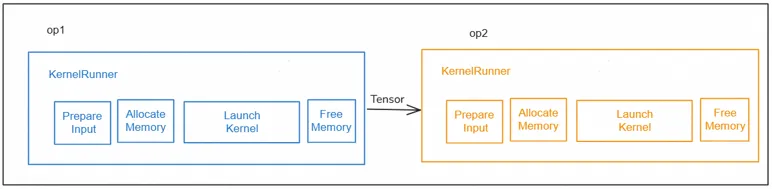
同步调度:
异步调度:
04 三级流水:让Host侧真正"流动"起来**
在异步下发基础上,昇思MindSpore进一步提出三级流水机制,将动态shape算子调度全流程并行化。
4.1 三队列并行架构
创建Infer Queue → Resize Queue → Launch Queue三级队列,分别对应:
- InferShape Task: Shape推导与属性更新
- Resize Task: Tiling计算与内存大小重计算
- Launch Task: kernel下发与执行触发
工作流程: 多级流水工作流程由高层队列将需要异步执行的task,push到低层队列中,高层队列继续执行同类业务,和低层队列的业务并发起来。按照算子调度的业务类型划分,需要InferQueue,ResizeQueue,LaunchQueue三级队列。KernelRunner完成输入数据准备后,只需将InferShape task推入Infer队列即可。InferShape完成后自动触发Resize task到Resize队列,Resize完成后自动触发LaunchKernel task到Launch队列。多级流水完全工作在C++侧,由运行时调度,不和Python侧交互,另外不用单独处理自动微分流程,反向算子已经入图,这两点是和动态图多级流水的主要差异点。
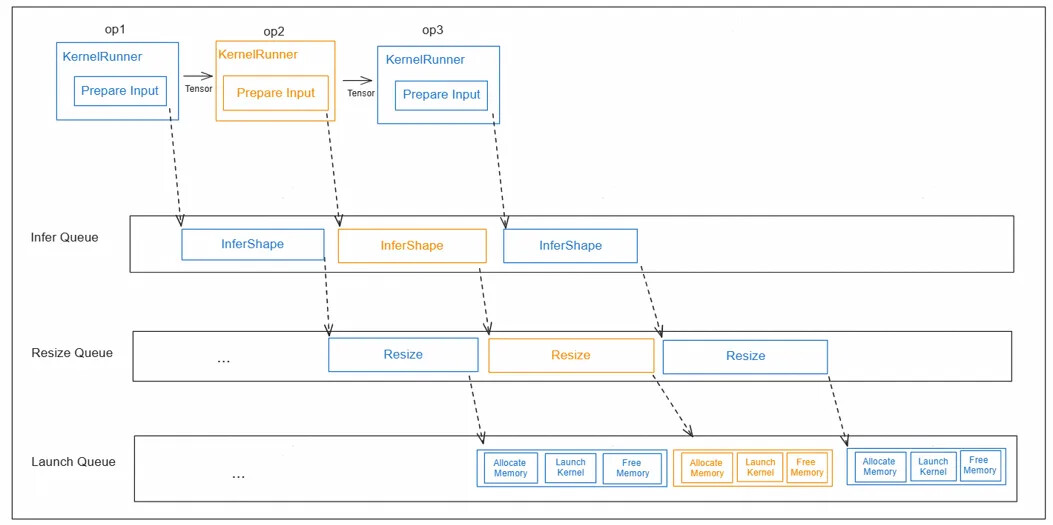
4.2 特殊场景同步机制
针对值依赖算子 (如Reshape、ReduceSum在InferShape时需从被依赖算子输出取值),在InferShape取值时需要同步三个队列,等待前面算子完成下发后,才能将前面算子输出结果同步到host使用。
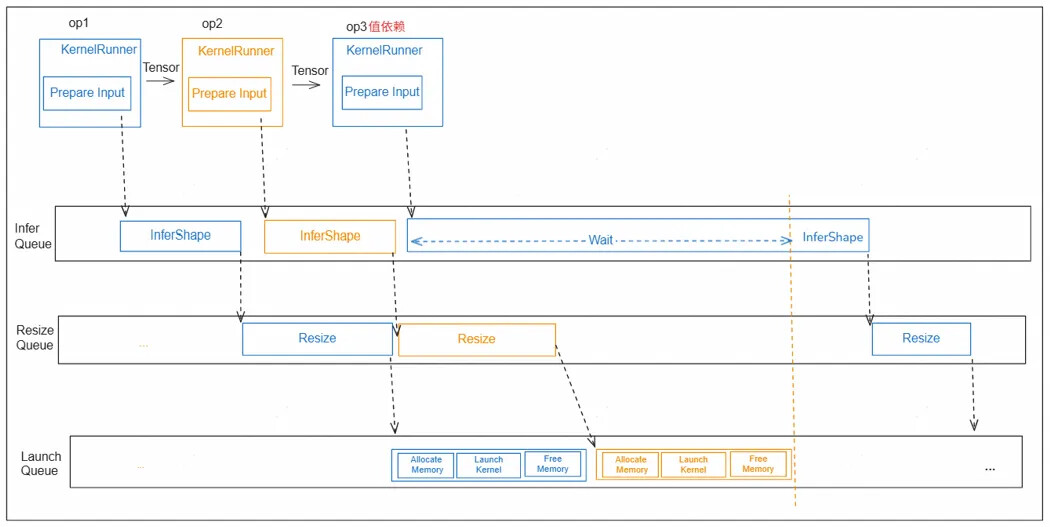
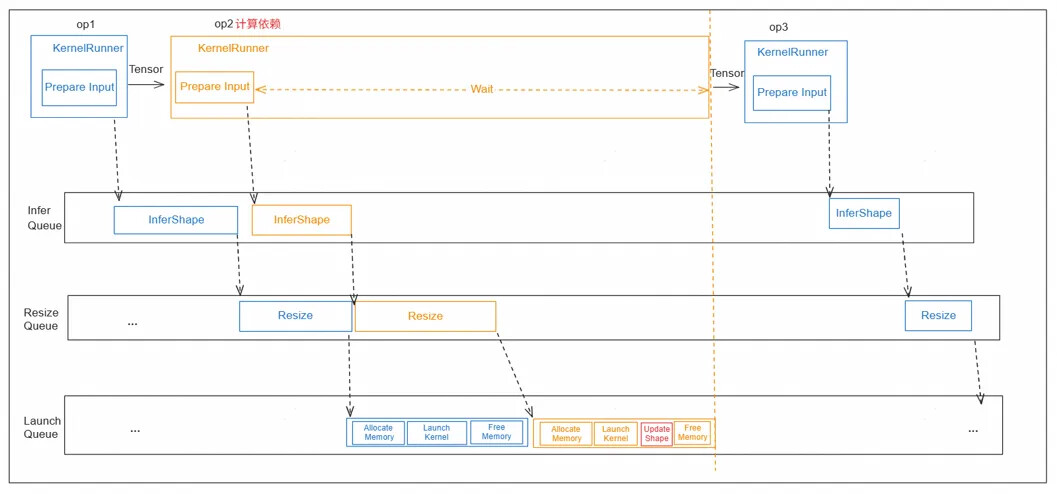
针对计算依赖算子 (如Unique需完成计算才能知道输出shape),KernelRunner下发完InferShape task后,需要wait三个队列完成,在Unique这类算子的launch完成后,更新输出shape和size,再调度后续算子。
05 三大技术协同:构建极致性能下发引擎**
昇思MindSpore将异构并行、异步下发、三级流水并发深度融合,构建统一的异步并行运行时引擎:
- 异构化: CPU×NPU双子图并行
- 异步化: 所有队列操作非阻塞,任务提交即返回
- 流水化: Infer→Resize→Launch三级流水无缝衔接,特殊场景精准同步
三者协同下,host侧从"顺序执行"转变为"任务工厂"模式,device侧从"等待驱动"转变为"持续消费"模式,host bound场景整体训推性能提升30%。