01 关键技术一:动态图多级流水 —— 细粒度调度,释放单算子下发性能**
由于动态图执行流程较长,需要通过python调用到C++,做类型推导,申请内存资源,自动微分处理等,导致算子下发较慢,MindSpore框架动态图模式,根据算子下发的特点设计基于异步流水的下发及自动微分的机制。
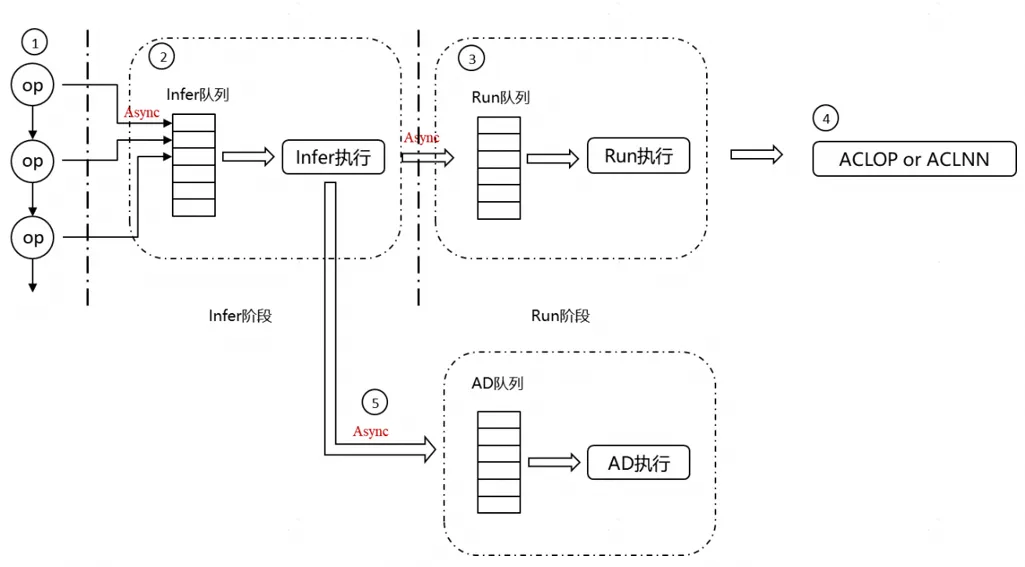
1、 Python阶段:对API的输入进行Python到C++类型的转换,该部分由于MindSpore动静态图使用相同数据结构,因此对这部分的优化主要是针对数据结构的创建以及转换效率行进行优化。
2、Infer阶段:该部分用于推导算子的输出shape和dtype,用于后续的显存申请,针对该部分,尽可能减少数据结构类型的转换,减少实现逻辑中的冗余判断等操作。
3、 执行阶段:该部分主要包含显存申请(输入输出显存,workspace显存),优化显存申请接口的性能以及显存表达的数据结构创建性能。
4、 硬件交互阶段:该部分主要调用底层提供硬件接口,通过队列保序,达到流水并发的效果。
5、 自动微分阶段: 该阶段主要发生在前向执行过程中,当执行过程中,得到API的输入输出后,就可以根据具体的算子得到相应的反向,因此如上图所示,在前向过程中,我们采用了一个AD线程来进行自动微分的构建,使得前向过程和自动微分过程能够并发执行,从而消减动态图每次重新构建计算图的开销。
该技术在某多模态大模型的应用中,端到端提升10%性能。
02 关键技术二:多流并发执行 —— 打破通信墙,实现计算与通信并发**
多模态训练不仅计算密集,更面临复杂的通信需求:文本梯度同步、图像特征广播、专家路由交换等多类通信操作常交织并存。若采用单流串行执行,NPU将长时间处于等待状态,集群利用率骤降。为此,昇思MindSpore在动态图中通过支持 多流并发执行,实现两类关键并发:
- 通信与计算并发: 支持通信流和计算流的并发执行,计算流和通信流公用一个内存池,实现计算和通信的内存复用;
- 通信与通信并发: 针对不同通信域单独申请通信流,自动分配不同通信流,充分利用网络带宽,消除通信串扰,例如在不同Pipeline阶段的send/recv使用不同的通信流。
该技术在某多模态大模型的应用中,端到端提升5%性能。
未来,昇思MindSpore将持续深耕动态图高性能计算,推动自主创新的AI基础软件从“可用”走向“领先”,为多模态智能时代的产业变革注入强劲动力。