这次体验的是GAN图像生成
生成式对抗网络(Generative Adversarial Networks,GAN)是一种生成式机器学习模型。
其主要由两个不同的模型共同组成——生成器和判别器:
生成器的任务是生成看起来像训练图像的“假”图像;
判别器需要判断从生成器输出的图像是真实的训练图像还是虚假的图像。
GAN通过设计生成模型和判别模型这两个模块,使其互相博弈学习产生了相当好的输出。
数据集
数据集简介
[MNIST手写数字数据集]是MNIST数据集的子集,共有70000张手写数字图片,包含60000张训练样本和10000张测试样本。数字图片为二进制文件,图片大小为28*28,单通道。图片已经预先进行了尺寸归一化和中心化处理。
数据下载:

数据加载
使用MindSpore自己的MnistDataset接口,读取和解析MNIST数据集的源文件构建数据集。然后对数据进行一些预处理。
import numpy as np
import mindspore.dataset as ds
batch_size = 128
latent_size = 100 # 隐码的长度
train_dataset = ds.MnistDataset(dataset_dir='./MNIST_Data/train')
test_dataset = ds.MnistDataset(dataset_dir='./MNIST_Data/test')
def data_load(dataset):
dataset1 = ds.GeneratorDataset(dataset, ["image", "label"], shuffle=True, python_multiprocessing=False)
# 数据增强
mnist_ds = dataset1.map(
operations=lambda x: (x.astype("float32"), np.random.normal(size=latent_size).astype("float32")),
output_columns=["image", "latent_code"])
mnist_ds = mnist_ds.project(["image", "latent_code"])
# 批量操作
mnist_ds = mnist_ds.batch(batch_size, True)
return mnist_ds
mnist_ds = data_load(train_dataset)
iter_size = mnist_ds.get_dataset_size()
print('Iter size: %d' % iter_size)
数据集可视化
通过create_dict_iterator函数将数据转换成字典迭代器,然后使用matplotlib模块可视化部分训练数据。
import matplotlib.pyplot as plt
data_iter = next(mnist_ds.create_dict_iterator(output_numpy=True))
figure = plt.figure(figsize=(3, 3))
cols, rows = 5, 5
for idx in range(1, cols * rows + 1):
image = data_iter['image'][idx]
figure.add_subplot(rows, cols, idx)
plt.axis("off")
plt.imshow(image.squeeze(), cmap="gray")
plt.show()

模型构建
本案例实现中所搭建的 GAN 模型结构与原论文中提出的 GAN 结构大致相同,但由于所用数据集 MNIST 为单通道小尺寸图片,可识别参数少,便于训练,我们在判别器和生成器中采用全连接网络架构和 ReLU 激活函数即可达到令人满意的效果,且省略了原论文中用于减少参数的 Dropout 策略和可学习激活函数 Maxout。
模型训练
训练分为两个主要部分。
第一部分是训练判别器。训练判别器的目的是最大程度地提高判别图像真伪的概率。按照原论文的方法,通过提高其随机梯度来更新判别器,最大化
的值。
第二部分是训练生成器。如论文所述,最小化
来训练生成器,以产生更好的虚假图像。
在这两个部分中,分别获取训练过程中的损失,并在每轮迭代结束时进行测试,将隐码批量推送到生成器中,以直观地跟踪生成器 Generator 的训练效果。
import os
import time
import matplotlib.pyplot as plt
import mindspore as ms
from mindspore import Tensor, save_checkpoint
total_epoch = 200 # 训练周期数
batch_size = 128 # 用于训练的训练集批量大小
# 加载预训练模型的参数
pred_trained = False
pred_trained_g = './result/checkpoints/Generator99.ckpt'
pred_trained_d = './result/checkpoints/Discriminator99.ckpt'
checkpoints_path = "./result/checkpoints" # 结果保存路径
image_path = "./result/images" # 测试结果保存路径
# 生成器计算损失过程
def generator_forward(test_noises):
fake_data = net_g(test_noises)
fake_out = net_d(fake_data)
loss_g = adversarial_loss(fake_out, ops.ones_like(fake_out))
return loss_g
# 判别器计算损失过程
def discriminator_forward(real_data, test_noises):
fake_data = net_g(test_noises)
fake_out = net_d(fake_data)
real_out = net_d(real_data)
real_loss = adversarial_loss(real_out, ops.ones_like(real_out))
fake_loss = adversarial_loss(fake_out, ops.zeros_like(fake_out))
loss_d = real_loss + fake_loss
return loss_d
# 梯度方法
grad_g = ms.value_and_grad(generator_forward, None, net_g.trainable_params())
grad_d = ms.value_and_grad(discriminator_forward, None, net_d.trainable_params())
def train_step(real_data, latent_code):
# 计算判别器损失和梯度
loss_d, grads_d = grad_d(real_data, latent_code)
optimizer_d(grads_d)
loss_g, grads_g = grad_g(latent_code)
optimizer_g(grads_g)
return loss_d, loss_g
# 保存生成的test图像
def save_imgs(gen_imgs1, idx):
for i3 in range(gen_imgs1.shape[0]):
plt.subplot(5, 5, i3 + 1)
plt.imshow(gen_imgs1[i3, 0, :, :] / 2 + 0.5, cmap="gray")
plt.axis("off")
plt.savefig(image_path + "/test_{}.png".format(idx))
# 设置参数保存路径
os.makedirs(checkpoints_path, exist_ok=True)
# 设置中间过程生成图片保存路径
os.makedirs(image_path, exist_ok=True)
net_g.set_train()
net_d.set_train()
# 储存生成器和判别器loss
losses_g, losses_d = [], []
for epoch in range(total_epoch):
start = time.time()
for (iter, data) in enumerate(mnist_ds):
start1 = time.time()
image, latent_code = data
image = (image - 127.5) / 127.5 # [0, 255] -> [-1, 1]
image = image.reshape(image.shape[0], 1, image.shape[1], image.shape[2])
d_loss, g_loss = train_step(image, latent_code)
end1 = time.time()
if iter % 10 == 0:
print(f"Epoch:[{int(epoch):>3d}/{int(total_epoch):>3d}], "
f"step:[{int(iter):>4d}/{int(iter_size):>4d}], "
f"loss_d:{d_loss.asnumpy():>4f} , "
f"loss_g:{g_loss.asnumpy():>4f} , "
f"time:{(end1 - start1):>3f}s, "
f"lr:{lr:>6f}")
end = time.time()
print("time of epoch {} is {:.2f}s".format(epoch + 1, end - start))
losses_d.append(d_loss.asnumpy())
losses_g.append(g_loss.asnumpy())
# 每个epoch结束后,使用生成器生成一组图片
gen_imgs = net_g(test_noise)
save_imgs(gen_imgs.asnumpy(), epoch)
# 根据epoch保存模型权重文件
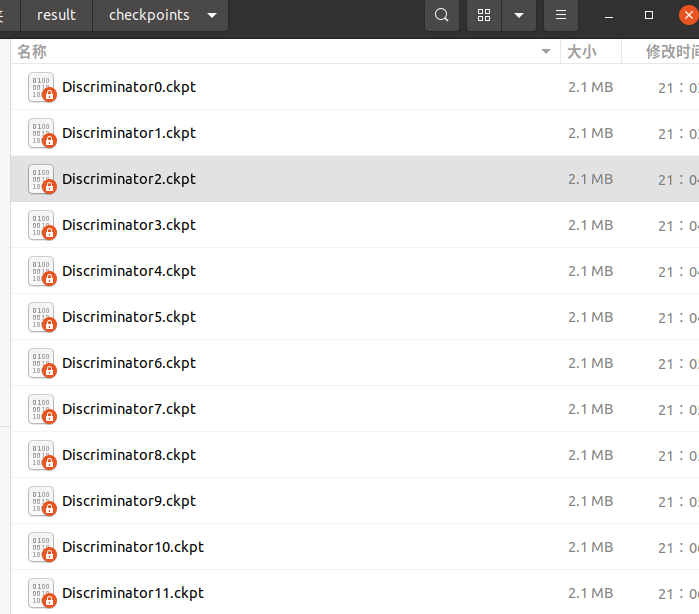
if epoch % 1 == 0:
save_checkpoint(net_g, checkpoints_path + "/Generator%d.ckpt" % (epoch))
save_checkpoint(net_d, checkpoints_path + "/Discriminator%d.ckpt" % (epoch))
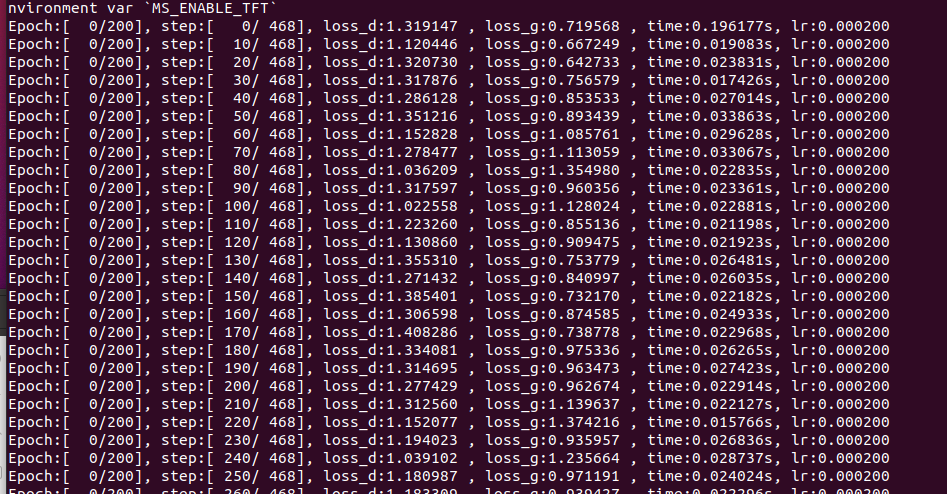
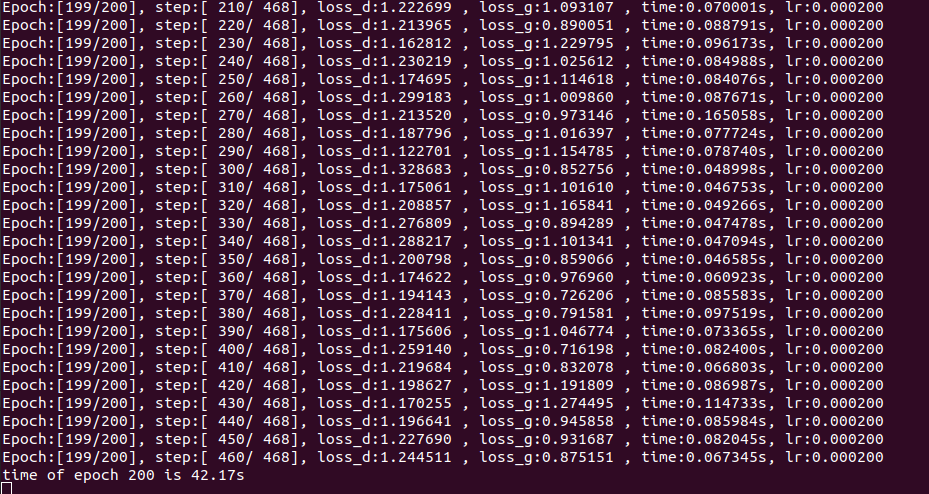
每一步都会保存ckpt,以及生成的图像。

打开test_0.png
test_58.png
test_188.png
从上面的图像就可以看出趋势。
随着训练次数的增多,图像质量也越来越好。如果增大训练周期数,当 epoch 达到100以上时,生成的手写数字图片与数据集中的较为相似。下面我们通过加载生成器网络模型参数文件来生成图像,代码如下:
模型推理
下面我们通过加载生成器网络模型参数文件来生成图像,代码如下:
import mindspore as ms
test_ckpt = './result/checkpoints/Generator199.ckpt'
parameter = ms.load_checkpoint(test_ckpt)
ms.load_param_into_net(net_g, parameter)
# 模型生成结果
test_data = Tensor(np.random.normal(0, 1, (25, 100)).astype(np.float32))
images = net_g(test_data).transpose(0, 2, 3, 1).asnumpy()
# 结果展示
fig = plt.figure(figsize=(3, 3), dpi=120)
for i in range(25):
fig.add_subplot(5, 5, i + 1)
plt.axis("off")
plt.imshow(images[i].squeeze(), cmap="gray")
plt.show()
