1 系统环境
硬件环境(Ascend/GPU/CPU): Ascend/GPU/CPU
MindSpore版本: mindspore=2.1.1
执行模式(PyNative/ Graph):不限
Python版本: Python=3.9.18
操作系统平台: Ubuntu22.04
2 报错信息
2.1问题描述
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
print(model)
milestone = [1,3,10,100]
learning_rates = [0.1,0.05,0.01,0.001]
lr = nn.piecewise_constant_lr(milestone,learning_rates)
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(),learning_rate=lr)
# optimizer = nn.SGD(model.trainable_params(),learning_rate=0.1)
2.2报错信息
使用官网入门实例https://gitee.com/mindspore/docs/blob/r2.1/tutorials/source_zh_cn/beginner/quick_start.ipynb。然后对学习率进行了修改,使用了动态学习率出现梯度异常问题。最后一行注释的代码是官方原始代码,学习率为固定常量 lr=0.1。
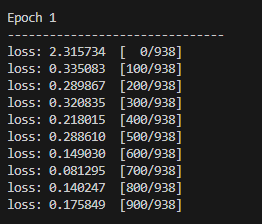
原官方代码运行结果
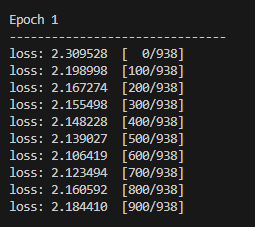
新增动态学习率后的运行结果
3 根因分析
piecewise_constant_lr
milestone = [1,3,10,100]
learning_rates = [0.1,0.05,0.01,0.001]
- step 1-3 学习率 0.1
- step 3-10 学习率 0.05
- step 10 -100 学习率0.01
- step 100之后学习率0.001
看loss变化情况, 这个lr的太小了,会导致无法收敛,可以修改milestone或learning_rates的值。
milestone = [1,100,500,700]
或
learning_rates = [1.0,0.5,0.2,0.1]
4 解决方案
loss_fn = nn.CrossEntropyLoss()
milestone = [1,100,500,700]
learning_rates = [0.1,0.05,0.01,0.001]
lr = nn.piecewise_constant_lr(milestone,learning_rates)
optimizer = nn.SGD(model.trainable_params(), lr)
或
loss_fn = nn.CrossEntropyLoss()
milestone = [1,3,10,100]
learning_rates = [1.0,0.5,0.2,0.1]
lr = nn.piecewise_constant_lr(milestone,learning_rates)
optimizer = nn.SGD(model.trainable_params(), lr)
修改之后
Epoch 1
-------------------------------
loss: 2.302190 [ 0/938]
loss: 0.583772 [100/938]
loss: 0.418784 [200/938]
loss: 0.479442 [300/938]
loss: 0.348099 [400/938]
loss: 0.638964 [500/938]
loss: 0.544504 [600/938]
loss: 0.524729 [700/938]
loss: 0.600319 [800/938]
loss: 0.439851 [900/938]
Test:
Accuracy: 82.9%, Avg loss: 0.506337