【问题描述】
训练日志报错,plog 报错GatherV2_xxx_high_precision_xx
【产品及版本】
MindSpore2.4.0
【问题原因】
GatherV2算子报错在plog中,一般都是数据集的词表和模型词表大小不一样,导致的越界
【处理过程】
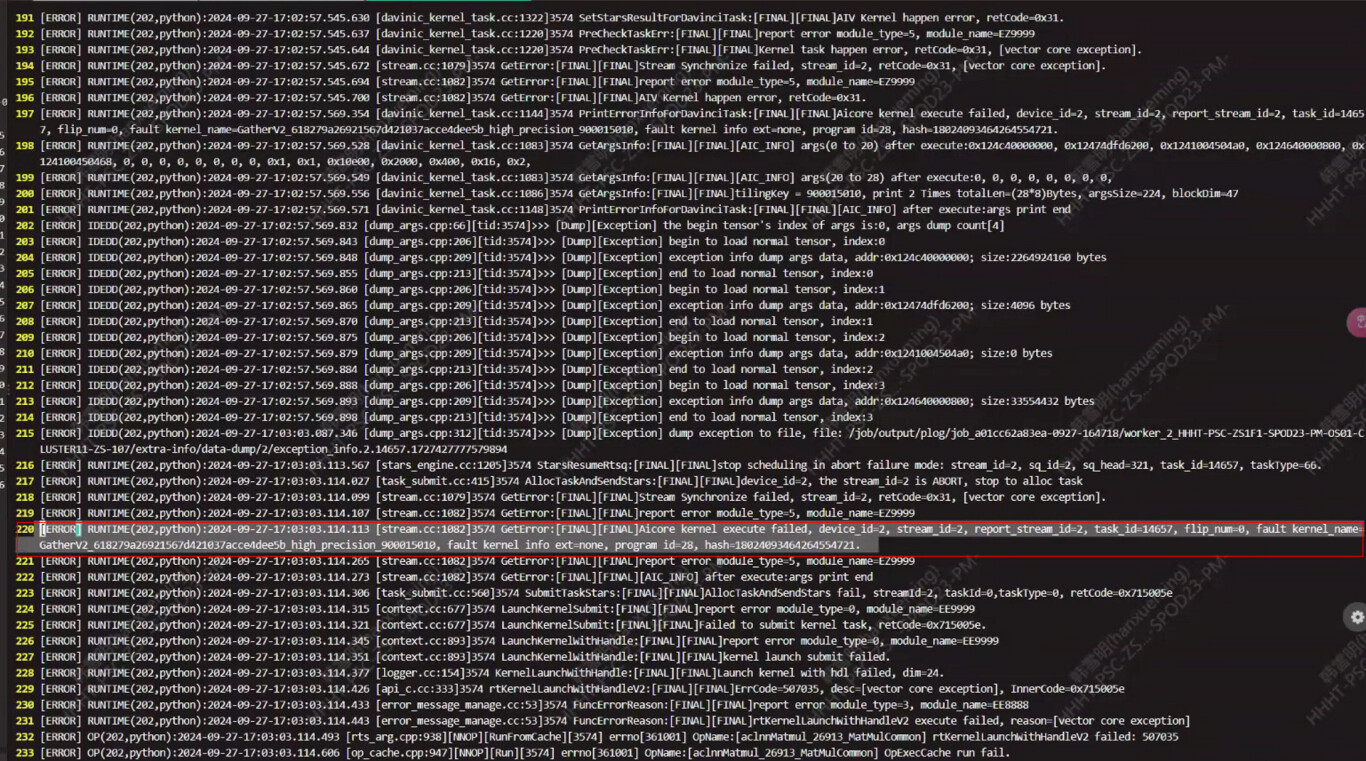
- 训练日志报错但看不出具体的报错原因。 查看plog日志,发现算子GatherV2_xxx_high_precision_xx报错
【解决方案】
查看yaml中vocab_size和数据集使用的词表大小是否匹配。
查看词表大小的方法:
如果使用 sentencepiece 库:
import sentencepiece as sp
sp_model = sp.SentencePieceProcessor()
sp_model.load("tokenizer.model")
vocab_size = sp_model.get_piece_size()
print(f"词表大小 (vocab_size): {vocab_size}")
如果使用 transformers 库中的相关类(如果适用的话):
from transformers import LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained("tokenizer.model")
vocab_size = tokenizer.vocab_size
print(f"词表大小 (vocab_size): {vocab_size}")
对于使用MIndFormer
from mindformers import LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained("tokenizer.model")
vocab_size = tokenizer.vocab_size
print(f"词表大小 (vocab_size): {vocab_size}")
不同的库和方法可能会有一些细微的差异,具体使用哪种方法取决于你项目中已安装和使用的库以及具体的需求。如果在读取过程中遇到权限问题,确保你有足够的权限访问该文件