1 系统环境
硬件环境(Ascend/GPU/CPU): Ascend
MindSpore版本: mindspore=2.4.0
执行模式(PyNative/ Graph): Graph
Python版本: Python=3.9.10
操作系统平台: linux
2 报错信息
2.1 问题描述
使用mint.masked_select在图模式下报错Parse Lambda Function Fail. Node type must be Lambda, but got Call.
2.2 报错信息
================================================================================== FAILURES ==================================================================================
_____________________________________________________________________ test_masked_select_forward_back[0] _____________________________________________________________________
mode = 0
@pytest.mark.parametrize('mode', [ms.GRAPH_MODE, ms.PYNATIVE_MODE])
def test_masked_select_forward_back(mode):
"""测试前向和反向传播,对比梯度"""
ms.set_context(mode=mode)
def forward_ms(x, mask):
return mint.masked_select(x, mask).sum()
def forward_torch(x, mask):
return torch.masked_select(x, mask).sum()
try:
input_data = [[1.0, 6.0, 2.0, 4.0], [7.0, 3.0, 8.0, 2.0], [2.0, 9.0, 11.0, 5.0]]
mask = [
[True, False, True, False],
[False, True, False, True],
[True, False, True, False]
]
ms_tensor, torch_tensor, ms_mask, torch_mask = create_tensors(input_data, ms.float32, torch.float32, mask=mask, requires_grad=True)
grad_fn_ms = value_and_grad(lambda x: forward_ms(x, ms_mask))
output_ms, gradient_ms = grad_fn_ms(ms_tensor)
output_torch = forward_torch(torch_tensor, torch_mask)
output_torch.backward()
compare_results(output_ms, output_torch.detach())
compare_results(gradient_ms, torch_tensor.grad)
except Exception as e:
> raise e
test_masked_select.py:228:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
test_masked_select.py:220: in test_masked_select_forward_back
output_ms, gradient_ms = grad_fn_ms(ms_tensor)
../anaconda3/envs/MindSpore/lib/python3.9/site-packages/mindspore/common/api.py:960: in staging_specialize
out = _MindsporeFunctionExecutor(func, hash_obj, dyn_args, process_obj, jit_config)(*args, **kwargs)
../anaconda3/envs/MindSpore/lib/python3.9/site-packages/mindspore/common/api.py:188: in wrapper
results = fn(*arg, **kwargs)
../anaconda3/envs/MindSpore/lib/python3.9/site-packages/mindspore/common/api.py:582: in __call__
raise err
../anaconda3/envs/MindSpore/lib/python3.9/site-packages/mindspore/common/api.py:579: in __call__
phase = self.compile(self.fn.__name__, *args_list, **kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <mindspore.common.api._MindsporeFunctionExecutor object at 0xffff74011f10>, method_name = 'after_grad'
args = (Tensor(shape=[3, 4], dtype=Float32, value=
[[ 1.00000000e+00, 6.00000000e+00, 2.00000000e+00, 4.00000000e+00],
[ ...00000e+00, 8.00000000e+00, 2.00000000e+00],
[ 2.00000000e+00, 9.00000000e+00, 1.10000000e+01, 5.00000000e+00]]),)
kwargs = {}
compile_args = (Tensor(shape=[3, 4], dtype=Float32, value=
[[ 1.00000000e+00, 6.00000000e+00, 2.00000000e+00, 4.00000000e+00],
[ ...00000e+00, 8.00000000e+00, 2.00000000e+00],
[ 2.00000000e+00, 9.00000000e+00, 1.10000000e+01, 5.00000000e+00]]),)
key_id = '1876509713526961735371593348192768'
generate_name = 'mindspore.ops.composite.base.after_grad./home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages/mindspore/ops/composite/base.py.599.1735371593348192768'
echo_function_name = 'function "after_grad" at the file "/home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages/mindspore/ops/composite/base.py", line 599'
full_function_name = 'mindspore.ops.composite.base.after_grad./home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages/mindspore/ops/composite/base.py.599'
create_time = '1735371593348192768', key = 0, parameter_ids = ''
phase = 'mindspore.ops.composite.base.after_grad./home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages/mindspore/ops/composite/base.py.599.1735371593348192768.0'
jit_config_dict = {'debug_level': 'RELEASE', 'exc_mode': 'auto', 'infer_boost': 'off', 'jit_level': '', ...}
def compile(self, method_name, *args, **kwargs):
"""Returns pipeline for the given args."""
# Check whether hook function registered on Cell object.
if self.obj and hasattr(self.obj, "_hook_fn_registered"):
if self.obj._hook_fn_registered():
logger.warning(f"For 'Cell', it's not support hook function when using 'jit' decorator. "
f"If you want to use hook function, please use context.set_context to set "
f"pynative mode and remove 'jit' decorator.")
# Chose dynamic shape tensors or actual input tensors as compile args.
compile_args = self._generate_compile_args(args)
key_id = self._get_key_id()
compile_args = get_auto_dynamic_shape_args_with_check_input_signature(compile_args, key_id,
self.input_signature)
# Restore the mutable attr for every arg.
compile_args = _restore_mutable_attr(args, compile_args)
self._compile_args = compile_args
generate_name, echo_function_name = self._get_generate_name()
# The full Function name
full_function_name = generate_name
create_time = ''
# Add key with obj
if self.obj is not None:
if self.obj.__module__ != self.fn.__module__:
logger.info(
f'The module of `self.obj`: `{self.obj.__module__}` is not same with the module of `self.fn`: '
f'`{self.fn.__module__}`')
self.obj.__parse_method__ = method_name
if isinstance(self.obj, ms.nn.Cell):
generate_name = generate_name + '.' + str(self.obj.create_time)
create_time = str(self.obj.create_time)
else:
generate_name = generate_name + '.' + str(self._create_time)
create_time = str(self._create_time)
generate_name = generate_name + '.' + str(id(self.obj))
full_function_name = generate_name
else:
# Different instance of same class may use same memory(means same obj_id) at diff times.
# To avoid unexpected phase matched, add create_time to generate_name.
generate_name = generate_name + '.' + str(self._create_time)
create_time = str(self._create_time)
self.enable_tuple_broaden = False
if hasattr(self.obj, "enable_tuple_broaden"):
self.enable_tuple_broaden = self.obj.enable_tuple_broaden
self._graph_executor.set_enable_tuple_broaden(self.enable_tuple_broaden)
key = self._graph_executor.generate_arguments_key(self.fn, compile_args, kwargs, self.enable_tuple_broaden)
parameter_ids = _get_parameter_ids(args, kwargs)
if parameter_ids != "":
key = str(key) + '.' + parameter_ids
phase = generate_name + '.' + str(key)
update_auto_dynamic_shape_phase_with_check_input_signature(compile_args, key_id, phase, self.input_signature)
if phase in ms_compile_cache:
# Release resource should be released when CompileInner won't be executed, such as cur_convert_input_
# generated in generate_arguments_key.
self._graph_executor.clear_compile_arguments_resource()
return phase
_check_recompile(self.obj, compile_args, kwargs, full_function_name, create_time, echo_function_name)
# If enable compile cache, get the dependency files list and set to graph executor.
self._set_compile_cache_dep_files()
if self.jit_config_dict:
self._graph_executor.set_jit_config(self.jit_config_dict)
else:
jit_config_dict = JitConfig().jit_config_dict
self._graph_executor.set_jit_config(jit_config_dict)
if self.obj is None:
# Set an attribute to fn as an identifier.
if isinstance(self.fn, types.MethodType):
setattr(self.fn.__func__, "__jit_function__", True)
else:
setattr(self.fn, "__jit_function__", True)
> is_compile = self._graph_executor.compile(self.fn, compile_args, kwargs, phase, True)
E TypeError: Parse Lambda Function Fail. Node type must be Lambda, but got Call. Please check lambda expression to make sure it is defined on a separate line.
E For example, the code 'func = nn.ReLU() if y < 1 else lambda x: x + 1' rewritten as
E 'if y < 1:
E func = nn.ReLU()
E else:
E func = lambda x: x + 1
E 'will solve the problem.
E
E ----------------------------------------------------
E - Framework Unexpected Exception Raised:
E ----------------------------------------------------
E This exception is caused by framework's unexpected error. Please create an issue at https://gitee.com/mindspore/mindspore/issues to get help.
E
E ----------------------------------------------------
E - C++ Call Stack: (For framework developers)
E ----------------------------------------------------
E mindspore/ccsrc/pipeline/jit/ps/parse/parse.cc:570 ParseFuncGraph
E
E ----------------------------------------------------
E - The Traceback of Net Construct Code:
E ----------------------------------------------------
E # 0 In file /home/ma-user/anaconda3/envs/MindSpore/lib/python3.9/site-packages/mindspore/ops/composite/base.py:601, 33~35
E return grad_(fn, weights, grad_position)(*args)
E ^~
E (See file '/home/ma-user/work/rank_0/om/analyze_fail.ir' for more details. Get instructions about `analyze_fail.ir` at https://www.mindspore.cn/search?inputValue=analyze_fail.ir)
../anaconda3/envs/MindSpore/lib/python3.9/site-packages/mindspore/common/api.py:674: TypeError复制
2.3 脚本信息
import pytest
import numpy as np
import mindspore as ms
from mindspore import Tensor, value_and_grad, mint
import torch
def create_tensors(input_data, ms_dtype, torch_dtype, mask=None, requires_grad=False):
ms_tensor = Tensor(input_data, ms_dtype)
torch_tensor = torch.tensor(input_data, dtype=torch_dtype, requires_grad=requires_grad)
if mask is not None:
mask = np.array(mask, dtype=bool)
ms_mask = Tensor(mask, ms.bool_)
torch_mask = torch.tensor(mask, dtype=torch.bool)
else:
ms_mask = None
torch_mask = None
return ms_tensor, torch_tensor, ms_mask, torch_mask
def perform_masked_select(ms_tensor, torch_tensor, ms_mask, torch_mask):
ms_result = mint.masked_select(ms_tensor, ms_mask)
torch_result = torch.masked_select(torch_tensor, torch_mask)
return ms_result, torch_result
def compare_results(ms_result, torch_result, atol=1e-3):
assert np.allclose(ms_result.asnumpy(), torch_result.numpy(), atol=atol)
@pytest.mark.parametrize('mode', [ms.GRAPH_MODE, ms.PYNATIVE_MODE])
def test_masked_select_forward_back(mode):
"""测试前向和反向传播,对比梯度"""
ms.set_context(mode=mode)
def forward_ms(x, mask):
return mint.masked_select(x, mask).sum()
def forward_torch(x, mask):
return torch.masked_select(x, mask).sum()
try:
input_data = [[1.0, 6.0, 2.0, 4.0], [7.0, 3.0, 8.0, 2.0], [2.0, 9.0, 11.0, 5.0]]
mask = [
[True, False, True, False],
[False, True, False, True],
[True, False, True, False]
]
ms_tensor, torch_tensor, ms_mask, torch_mask = create_tensors(input_data, ms.float32, torch.float32, mask=mask, requires_grad=True)
grad_fn_ms = value_and_grad(lambda x: forward_ms(x, ms_mask))
output_ms, gradient_ms = grad_fn_ms(ms_tensor)
output_torch = forward_torch(torch_tensor, torch_mask)
output_torch.backward()
compare_results(output_ms, output_torch.detach())
compare_results(gradient_ms, torch_tensor.grad)
except Exception as e:
raise e
3 根因分析
mindspore.value_and_grad(_fn_ , _grad_position=0_ , _weights=None_ , _has_aux=False_ , _return_ids=False_)
- fn (Union[Cell, Function]) - 待求导的函数或网络。
grad_fn_ms = value_and_grad(lambda x: forward_ms(x, ms_mask))匿名函数一般用于临时函数,用在这里并不合适。
lambda x: forward_ms(x, ms_mask)
相当于定义了一个新函数,参数x 。可以直接把forward_ms 作为fn函数,只是输入要带上ms_mask
4 解决方案
grad_fn_ms = value_and_grad(lambda x: forward_ms(x, ms_mask))
output_ms, gradient_ms = grad_fn_ms(ms_tensor)
修改为
grad_fn_ms = value_and_grad(forward_ms(x, ms_mask))
output_ms, gradient_ms = grad_fn_ms(ms_tensor, ms_mask)
因为给的代码还有其他依赖。
用如下代码可以直接验证。
import mindspore as ms
import numpy as np
from mindspore import ops, mint, value_and_grad, Tensor
import torch
ms.set_context(mode=ms.GRAPH_MODE)
def forward_ms(x, mask):
return mint.masked_select(x, mask).sum()
def forward_torch(x, mask):
return torch.masked_select(x, mask).sum()
try:
input_data = [[1.0, 6.0, 2.0, 4.0], [7.0, 3.0, 8.0, 2.0], [2.0, 9.0, 11.0, 5.0]]
mask = [
[True, False, True, False],
[False, True, False, True],
[True, False, True, False]
]
ms_tensor = Tensor(input_data,dtype=ms.float32)
ms_mask= Tensor(mask,dtype=ms.bool_)
grad_fn_ms = value_and_grad(forward_ms)
output_ms, gradient_ms = grad_fn_ms(ms_tensor,ms_mask)
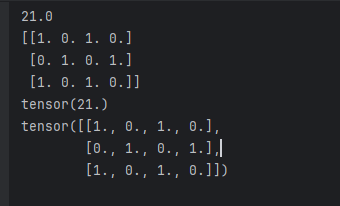
print(output_ms)
print(gradient_ms)
torch_tensor=torch.from_numpy(np.array(input_data,dtype=np.float32))
torch_tensor.requires_grad=True
torch_mask=torch.from_numpy(np.array(mask,dtype=np.bool_))
output_torch = forward_torch(torch_tensor, torch_mask)
output_torch.backward()
print(output_torch.detach())
print(torch_tensor.grad)
except Exception as e:
raise e
结果输出