1 系统环境
硬件环境(Ascend/GPU/CPU): GPU
软件环境:MindSpore 版本: 1.9.0
执行模式: 动态图 PYNATIVE
Python 版本: 3.7.5
操作系统平台: Linux
2 报错信息
2.1 问题描述
两个网络中的层有相同名称时报错
2.2 报错信息

附件示例和图片示例感觉不太一样,以附件为准
2.3 脚本代码
从附件中获取
import mindspore.nn as nn
from mindspore.common.parameter import ParameterTuple, Parameter
class FullyConnectedNet(nn.Cell):
def __init__(self, input_size, hidden_size, output_size):
super(FullyConnectedNet, self).__init__(auto_prefix=False)
self.linear1 = nn.Dense( input_size, hidden_size, weight_init="XavierUniform")
self.linear2 = nn.Dense(hidden_size, output_size, weight_init="XavierUniform")
self.relu = nn.ReLU()
def construct(self, x):
x = self.relu(self.linear1(x))
x = self.linear2(x)
return x
class EmaUpdate(nn.Cell):
def __init__(self, policy_net, target_net):
super(EmaUpdate, self).__init__()
self.policy_param = ParameterTuple(policy_net.get_parameters())
self.target_param = ParameterTuple(target_net.get_parameters())
def construct(self, x):
return x
policy_net = FullyConnectedNet(4, 100, 2)
target_net = FullyConnectedNet(4, 100, 2)
ema_update = EmaUpdate(policy_net, target_net)
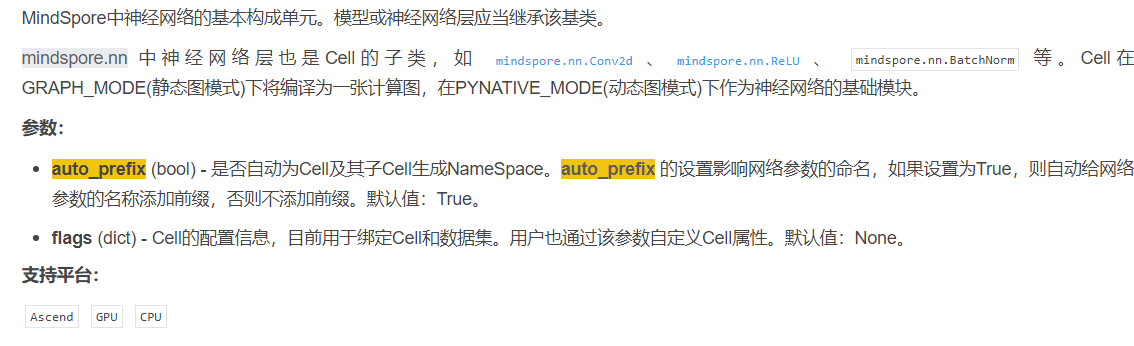
3 根因分析
1. FullyConnectedNet网络中auto_prefix=False, 因此没有给网络参数的名称添加前缀, 两个参数的name都叫做’weight’, 重名
2. 而当把参数给ParameterTuple的时候,ParameterTuple对名字的唯一性有要求,因此就会报错,说’weight’已经存在
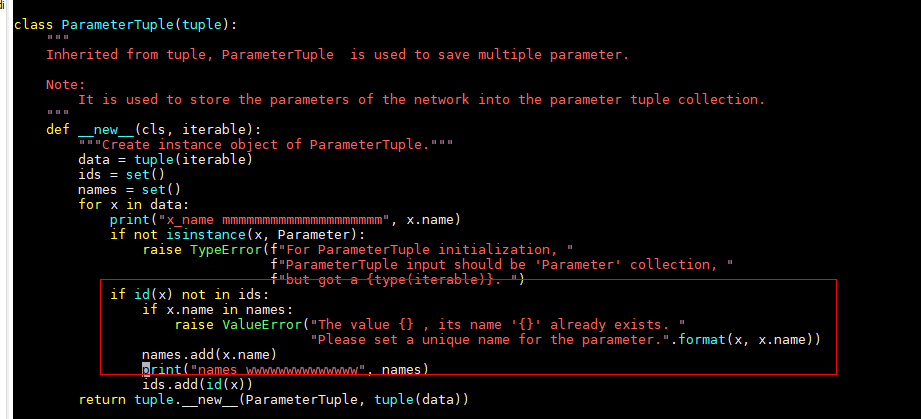
4 解决方案
解决方案说明:把FullyConnectedNet网络的auto_prefix=False改成auto_prefix=True, 或者不设置,因为默认就是True, 这样自动给网络参数的名称添加前缀,一个叫linear1.weight 一个叫linear2.weight, ParameterTuple就不会报错
修改后代码:
import mindspore.nn as nn
from mindspore.common.parameter import ParameterTuple, Parameter
from mindspore import context
context.set_context(mode=context.PYNATIVE_MODE)
class FullyConnectedNet(nn.Cell):
def __init__(self, input_size, hidden_size, output_size):
super(FullyConnectedNet, self).__init__(auto_prefix=True)
self.linear1 = nn.Dense(input_size, hidden_size, weight_init="XavierUniform")
self.linear2 = nn.Dense(hidden_size, output_size, weight_init="XavierUniform")
self.relu = nn.ReLU()
def construct(self, x):
x = self.relu(self.linear1(x))
x = self.linear2(x)
return x
class EmaUpdate(nn.Cell):
def __init__(self, policy_net, target_net):
super(EmaUpdate, self).__init__()
self.policy_param = ParameterTuple(policy_net.get_parameters())
self.target_param = ParameterTuple(target_net.get_parameters())
def construct(self, x):
return x
policy_net = FullyConnectedNet(4, 100, 2)
target_net = FullyConnectedNet(4, 100, 2)
print("mmmmmmmmmmmmm", policy_net.trainable_params())
print("wwwwwwwww", target_net.trainable_params())
ema_update = EmaUpdate(policy_net, target_net)
执行后的结果
用例pass且打印想要的参数
mmmmmmmmmmmmm [Parameter (name=linear1.weight, shape=(100, 4), dtype=Float32, requires_grad=True), Parameter (name=linear1.bias, shape=(100,), dtype=Float32, requires_grad=True), Parameter (name=linear2.weight, shape=(2, 100), dtype=Float32, requires_grad=True), Parameter (name=linear2.bias, shape=(2,), dtype=Float32, requires_grad=True)]
wwwwwwwww [Parameter (name=linear1.weight, shape=(100, 4), dtype=Float32, requires_grad=True), Parameter (name=linear1.bias, shape=(100,), dtype=Float32, requires_grad=True), Parameter (name=linear2.weight, shape=(2, 100), dtype=Float32, requires_grad=True), Parameter (name=linear2.bias, shape=(2,), dtype=Float32, requires_grad=True)]
x_name mmmmmmmmmmmmmmmmmmmm linear1.weight
names wwwwwwwwwwwwww {'linear1.weight'}
x_name mmmmmmmmmmmmmmmmmmmm linear1.bias
names wwwwwwwwwwwwww {'linear1.bias', 'linear1.weight'}
x_name mmmmmmmmmmmmmmmmmmmm linear2.weight
names wwwwwwwwwwwwww {'linear1.bias', 'linear1.weight', 'linear2.weight'}
x_name mmmmmmmmmmmmmmmmmmmm linear2.bias
names wwwwwwwwwwwwww {'linear1.bias', 'linear1.weight', 'linear2.bias', 'linear2.weight'} ---ParameterTuple1
x_name mmmmmmmmmmmmmmmmmmmm linear1.weight
names wwwwwwwwwwwwww {'linear1.weight'}
x_name mmmmmmmmmmmmmmmmmmmm linear1.bias
names wwwwwwwwwwwwww {'linear1.bias', 'linear1.weight'}
x_name mmmmmmmmmmmmmmmmmmmm linear2.weight
names wwwwwwwwwwwwww {'linear1.bias', 'linear1.weight', 'linear2.weight'}
x_name mmmmmmmmmmmmmmmmmmmm linear2.bias
names wwwwwwwwwwwwww {'linear1.bias', 'linear1.weight', 'linear2.bias', 'linear2.weight'} ---ParameterTuple2