YOLO模型一直想实践下,手上刚好有块闲置的树莓派,型号是3B+。
准备把整个过程记录下。
YOLO 是 “You only look once” 缩写 , 是将图像划分为网格系统的对象检测算法,网格中的每个单元负责检测自身内的对象。
由于其速度和准确性,YOLO是最著名的目标检测算法之一。
yolov5作为YOLO系列第五个迭代版本,它的一个特点就是权重文件非常之小,可以搭载在配置更低的移动设备上,而且容易学习上手。
树莓派3B+的硬件具体参数如下:
处理器:博通(broadcom2837B0)基于ARMv8内核(cortex-A53)64位@1.4GHz;
内存:1GB LPDDR2 SDRAM
这个性能处理实时的视频采集压缩同时还要做对象的识别,已经预感到性能不足。最终能达到什么效果现在我也没法说。
首先一点,YOLOv5完整版肯定是不行的,估计最后要采用tiny版本的模型。
首先,是给树莓派安装系统。
本身性能就不够,就不安装桌面系统了。毕竟桌面系统没啥用,远程ssh登录就可以了。
用树莓派镜像烧录器选择PI OS LITE 64位。LITE仅仅是没有桌面环境,还有必须选择64位系统。因为mindspore只支持arm64。


经过漫长的系统烧录以及第一次开机后就能ssh登录了。
然后看下环境。默认python3.9, 就不用更换了。

接下来的环境的一些配置。
修改python国内源,修改apt国内源,然后安装vim。默认的源速度实在太慢。
修改后执行apt-get update报错,缺少签名。需要更新签名。

然后就是安装

python源的话就是增加~/.pip/pip.conf文件,然后写入国内源地址就可以。
然后就是安装mindspore并验证安装是否成功。

到此,环境安装配置就已经完成了。
接下来就是YOLOv5模型了。
MindSpore ModelZoo已经有相关模型了。
链接如下:
首先是数据集,可以使用COCO2017或与MS COCO标注格式相同的数据集运行脚本。但建议使用MS COCO数据集。
MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集。
COCO数据集是一个可用于图像检测(image detection),语义分割(semantic segmentation)和图像标题生成(image captioning)的大规模数据集。
它有超过330K张图像(其中220K张是有标注的图像),包含150万个目标,80个目标类别(object categories:行人、汽车、大象等),91种材料类别(stuff categoris:草、墙、天空等),每张图像包含五句图像的语句描述,且有250,000个带关键点标注的行人。
下载如下数据集:
2017 Train/Val annotations [241MB]
YOLOv5中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果是不错的。
数据处理的代码如下:
准备好这些之后来看下网络结构。
官方yolov5提供了s、m、l、x四种,通过yaml进行配置。
depth_multiple:控制模型的深度。
width_multiple:控制卷积核的个数。
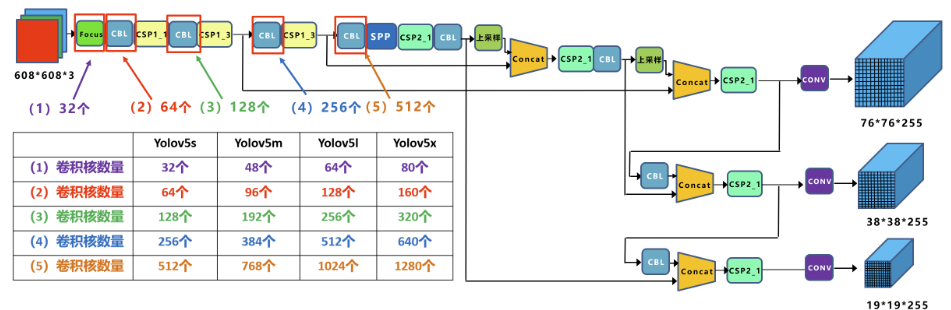
(该图出处:CSDN 江大白 深入浅出Yolo系列之Yolov5核心基础知识完整讲解)
mindspore迁移的代码通过入参来控制。
dict_version = {'yolov5s': 0, 'yolov5m': 1, 'yolov5l': 2, 'yolov5x': 3}
network = YOLOV5(is_training=False, version=dict_version[config.yolov5_version])
复制
class YOLOV5(nn.Cell):
"""
YOLOV5 network.
Args:
is_training: Bool. Whether train or not.
Returns:
Cell, cell instance of YOLOV5 neural network.
Examples:
YOLOV5s(True)
"""
def __init__(self, is_training, version=0):
super(YOLOV5, self).__init__()
self.config = default_config
# YOLOv5 network
self.shape = self.config.input_shape[version]
self.feature_map = YOLO(backbone=YOLOv5Backbone(shape=self.shape), shape=self.shape)
复制
class YOLO(nn.Cell):
def __init__(self, backbone, shape):
super(YOLO, self).__init__()
self.backbone = backbone
self.config = default_config
self.config.out_channel = (self.config.num_classes + 5) * 3
self.conv1 = Conv(shape[5], shape[4], k=1, s=1)
self.CSP5 = BottleneckCSP(shape[5], shape[4], n=1*shape[6], shortcut=False)
self.conv2 = Conv(shape[4], shape[3], k=1, s=1)
self.CSP6 = BottleneckCSP(shape[4], shape[3], n=1*shape[6], shortcut=False)
self.conv3 = Conv(shape[3], shape[3], k=3, s=2)
self.CSP7 = BottleneckCSP(shape[4], shape[4], n=1*shape[6], shortcut=False)
self.conv4 = Conv(shape[4], shape[4], k=3, s=2)
self.CSP8 = BottleneckCSP(shape[5], shape[5], n=1*shape[6], shortcut=False)
self.back_block1 = YoloBlock(shape[3], self.config.out_channel)
self.back_block2 = YoloBlock(shape[4], self.config.out_channel)
self.back_block3 = YoloBlock(shape[5], self.config.out_channel)
self.concat = ops.Concat(axis=1)
def construct(self, x):
"""
input_shape of x is (batch_size, 3, h, w)
feature_map1 is (batch_size, backbone_shape[2], h/8, w/8)
feature_map2 is (batch_size, backbone_shape[3], h/16, w/16)
feature_map3 is (batch_size, backbone_shape[4], h/32, w/32)
"""
img_height = x.shape[2] * 2
img_width = x.shape[3] * 2
feature_map1, feature_map2, feature_map3 = self.backbone(x)
c1 = self.conv1(feature_map3)
ups1 = ops.ResizeNearestNeighbor((img_height // 16, img_width // 16))(c1)
c2 = self.concat((ups1, feature_map2))
c3 = self.CSP5(c2)
c4 = self.conv2(c3)
ups2 = ops.ResizeNearestNeighbor((img_height // 8, img_width // 8))(c4)
c5 = self.concat((ups2, feature_map1))
# out
c6 = self.CSP6(c5)
c7 = self.conv3(c6)
c8 = self.concat((c7, c4))
# out
c9 = self.CSP7(c8)
c10 = self.conv4(c9)
c11 = self.concat((c10, c1))
# out
c12 = self.CSP8(c11)
small_object_output = self.back_block1(c6)
medium_object_output = self.back_block2(c9)
big_object_output = self.back_block3(c12)
return small_object_output, medium_object_output, big_object_output
复制
YOLOv5Backbone在如下文件中定义:
class YOLOv5Backbone(nn.Cell):
def __init__(self, shape):
super(YOLOv5Backbone, self).__init__()
self.focus = Focus(shape[0], shape[1], k=3, s=1)
self.conv1 = Conv(shape[1], shape[2], k=3, s=2)
self.CSP1 = BottleneckCSP(shape[2], shape[2], n=1 * shape[6])
self.conv2 = Conv(shape[2], shape[3], k=3, s=2)
self.CSP2 = BottleneckCSP(shape[3], shape[3], n=3 * shape[6])
self.conv3 = Conv(shape[3], shape[4], k=3, s=2)
self.CSP3 = BottleneckCSP(shape[4], shape[4], n=3 * shape[6])
self.conv4 = Conv(shape[4], shape[5], k=3, s=2)
self.spp = SPP(shape[5], shape[5], k=[5, 9, 13])
self.CSP4 = BottleneckCSP(shape[5], shape[5], n=1 * shape[6], shortcut=False)
def construct(self, x):
"""construct method"""
c1 = self.focus(x)
c2 = self.conv1(c1)
c3 = self.CSP1(c2)
c4 = self.conv2(c3)
# out
c5 = self.CSP2(c4)
c6 = self.conv3(c5)
# out
c7 = self.CSP3(c6)
c8 = self.conv4(c7)
c9 = self.spp(c8)
# out
c10 = self.CSP4(c9)
return c5, c7, c10
复制
基本结构和官方一致,可以参考上面的图。
接下来就是Loss的计算了。
目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
Yolov5中采用其中的CIOU_Loss做Bounding box的损失函数。
loss定义如下:
class YoloWithLossCell(nn.Cell):
"""YOLOV5 loss."""
def __init__(self, network):
super(YoloWithLossCell, self).__init__()
self.yolo_network = network
self.config = default_config
self.loss_big = YoloLossBlock('l', self.config)
self.loss_me = YoloLossBlock('m', self.config)
self.loss_small = YoloLossBlock('s', self.config)
self.tenser_to_array = ops.TupleToArray()
def construct(self, x, y_true_0, y_true_1, y_true_2, gt_0, gt_1, gt_2, input_shape):
yolo_out = self.yolo_network(x, input_shape)
loss_l = self.loss_big(*yolo_out[0], y_true_0, gt_0, input_shape)
loss_m = self.loss_me(*yolo_out[1], y_true_1, gt_1, input_shape)
loss_s = self.loss_small(*yolo_out[2], y_true_2, gt_2, input_shape)
return loss_l + loss_m + loss_s * 0.2
class YoloLossBlock(nn.Cell):
"""
Loss block cell of YOLOV5 network.
"""
def __init__(self, scale, config=default_config):
super(YoloLossBlock, self).__init__()
self.config = config
if scale == 's':
# anchor mask
idx = (0, 1, 2)
elif scale == 'm':
idx = (3, 4, 5)
elif scale == 'l':
idx = (6, 7, 8)
else:
raise KeyError("Invalid scale value for DetectionBlock")
self.anchors = ms.Tensor([self.config.anchor_scales[i] for i in idx], ms.float32)
self.ignore_threshold = ms.Tensor(self.config.ignore_threshold, ms.float32)
self.concat = ops.Concat(axis=-1)
self.iou = Iou()
self.reduce_max = ops.ReduceMax(keep_dims=False)
self.confidence_loss = ConfidenceLoss()
self.class_loss = ClassLoss()
self.reduce_sum = ops.ReduceSum()
self.select = ops.Select()
self.equal = ops.Equal()
self.reshape = ops.Reshape()
self.expand_dims = ops.ExpandDims()
self.ones_like = ops.OnesLike()
self.log = ops.Log()
self.tuple_to_array = ops.TupleToArray()
self.g_iou = GIou()
def construct(self, prediction, pred_xy, pred_wh, y_true, gt_box, input_shape):
"""
prediction : origin output from yolo
pred_xy: (sigmoid(xy)+grid)/grid_size
pred_wh: (exp(wh)*anchors)/input_shape
y_true : after normalize
gt_box: [batch, maxboxes, xyhw] after normalize
"""
object_mask = y_true[:, :, :, :, 4:5]
class_probs = y_true[:, :, :, :, 5:]
true_boxes = y_true[:, :, :, :, :4]
grid_shape = prediction.shape[1:3]
grid_shape = ops.cast(self.tuple_to_array(grid_shape[::-1]), ms.float32)
pred_boxes = self.concat((pred_xy, pred_wh))
true_wh = y_true[:, :, :, :, 2:4]
true_wh = self.select(self.equal(true_wh, 0.0),
self.ones_like(true_wh),
true_wh)
true_wh = self.log(true_wh / self.anchors * input_shape)
# 2-w*h for large picture, use small scale, since small obj need more precise
box_loss_scale = 2 - y_true[:, :, :, :, 2:3] * y_true[:, :, :, :, 3:4]
gt_shape = gt_box.shape
gt_box = self.reshape(gt_box, (gt_shape[0], 1, 1, 1, gt_shape[1], gt_shape[2]))
# add one more dimension for broadcast
iou = self.iou(self.expand_dims(pred_boxes, -2), gt_box)
# gt_box is x,y,h,w after normalize
# [batch, grid[0], grid[1], num_anchor, num_gt]
best_iou = self.reduce_max(iou, -1)
# [batch, grid[0], grid[1], num_anchor]
# ignore_mask IOU too small
ignore_mask = best_iou < self.ignore_threshold
ignore_mask = ops.cast(ignore_mask, ms.float32)
ignore_mask = self.expand_dims(ignore_mask, -1)
# ignore_mask backpro will cause a lot maximunGrad and minimumGrad time consume.
# so we turn off its gradient
ignore_mask = ops.stop_gradient(ignore_mask)
confidence_loss = self.confidence_loss(object_mask, prediction[:, :, :, :, 4:5], ignore_mask)
class_loss = self.class_loss(object_mask, prediction[:, :, :, :, 5:], class_probs)
object_mask_me = self.reshape(object_mask, (-1, 1)) # [8, 72, 72, 3, 1]
box_loss_scale_me = self.reshape(box_loss_scale, (-1, 1))
pred_boxes_me = xywh2x1y1x2y2(pred_boxes)
pred_boxes_me = self.reshape(pred_boxes_me, (-1, 4))
true_boxes_me = xywh2x1y1x2y2(true_boxes)
true_boxes_me = self.reshape(true_boxes_me, (-1, 4))
c_iou = self.g_iou(pred_boxes_me, true_boxes_me)
c_iou_loss = object_mask_me * box_loss_scale_me * (1 - c_iou)
c_iou_loss_me = self.reduce_sum(c_iou_loss, ())
loss = c_iou_loss_me * 4 + confidence_loss + class_loss
batch_size = prediction.shape[0]
return loss / batch_size
复制
以上就是数据读取到网络定义以及loss定义。
实际运行效果待续。