1 系统环境
硬件环境(Ascend/GPU/CPU): Ascend/GPU/CPU
MindSpore版本: 不限版本
执行模式(PyNative/ Graph): 不限模式
Python版本: Python=3.7/3.8/3.9
操作系统平台: 不限
2 报错信息
2.1 问题描述
在使用 Mindspore 训练网络时,发现网络推理的时间过长。
2.2 报错信息
profiler 后发现大部分的时间都花在了 全连接层的 Matmul 矩阵乘法上,应该如何优化?
2.3 脚本代码
可根据描述自行构造
3 根因分析
根据报错信息可知,训练速度慢的主要原因是Matmul 矩阵乘法上。对于计算量比较密集的算子,使用float32精度计算会比float16精度计算耗时更多。为了提升速度,节省时间,可以在执行前先转化成float16精度类型,计算结束后再转换回float32精度类型,这样可以加快计算速度。
- 自定义代码测试,数值相乘,看运行时间差距
import numpy as np
import mindspore.nn as nn
from mindspore.ops import operations as ops
import mindspore as ms
import time
ms.set_context(mode=ms.GRAPH_MODE, device_target="GPU")
class Net(nn.Cell):
def __init__(self):
super(Net, self).__init__()
self.matmul = ops.MatMul(transpose_b=True)
def construct(self, x, y):
return self.matmul(x, y)
x = ms.Tensor(np.arange(10240*10240).reshape(10240, 10240).astype(np.float32))
y = ms.Tensor(np.arange(10240*10240).reshape(10240, 10240).astype(np.float32))
net = Net()
# print(net(x, y))
# 计时
a = time.time()
output = net(x, y)
time32 = time.time() - a
# print(output)
print(output.shape)
print (time32)
net2 = Net()
# 类型转换
x2 = ms.Tensor(x, dtype=ms.float16)
# 计时
b = time.time()
output = net(x, y)
time16 = time.time() - b
# print(output)
print(output.shape)
print (time16)
- 输出结果:可以看出float16要比float32快数倍
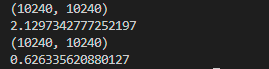
4 解决方案
- 执行前先转化成float16精度类型,计算结束后再转换回float32精度类型,这样可以加快计算速度。
- 根据报错信息可知作者使用全连接层时遇到的问题,因此我们通过全连接层运算,发现数据类型转换后速度提升约50倍。
import numpy as np
import mindspore.nn as nn
from mindspore.ops import operations as ops
import mindspore as ms
import time
ms.set_context(mode=ms.GRAPH_MODE, device_target="GPU")
x = ms.Tensor(np.arange(10240*10240).reshape(10240, 10240).astype(np.float32))
net = nn.Dense(10240, 60)
# 计时
a = time.time()
output = net(x)
time32 = time.time() - a
# print(output)
print(output.shape)
print (time32)
net2 = nn.Dense(10240, 60)
# 类型转换
x2 = ms.Tensor(x, dtype=ms.float16)
# 计时
b = time.time()
output = net(x)
time16 = time.time() - b
# print(output)
print(output.shape)
print (time16)
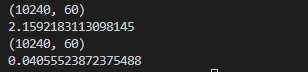
- 提速将近2.15/0.04 = 50 倍