理论基础
LoRA微调基础概念与原理
- 核心机制:LoRA微调通过冻结原始网络的全部参数,仅在Attention层中的Q、K、V等模块添加旁支结构,该旁支包含两个低维度矩阵A和B,微调过程中仅对这两个矩阵的参数进行更新。
- 显著优势:这种方式能大幅降低训练参数的数量,经实际验证,参与训练的参数仅占模型总参数量的0.5%,从而显著减少了对硬件资源的消耗。

DeepSeek-R1-Distill-Qwen-1.5B模型LoRA微调实施步骤
- 实例化基础模型:指定模型ID为“THsiao/DeepSeek-R1-Disti1-Qwen-1.5B-FP16”,使用
AutoModelForCausalLM.from_pretrained方法加载模型,同时设置镜像源为“modelers”、数据类型为mindspore.float16;此外,还需从模型中加载生成配置,并将pad_token_id设置为与eos_token_id相同。 - 配置LoraConfig:明确任务类型为
TaskType.CAUSAL_LM,指定目标模块包括“q_pro”“k_pro”等,设置Lora秩(r)为8、Lora alpha为32、Lora dropout为0.1,且将inference_mode设为False以启用训练模式。 - 实例化LoRA模型:调用
get_peft_model方法,将基础模型与上述配置结合,得到可进行LoRA微调的模型。 - 查看训练参数:通过
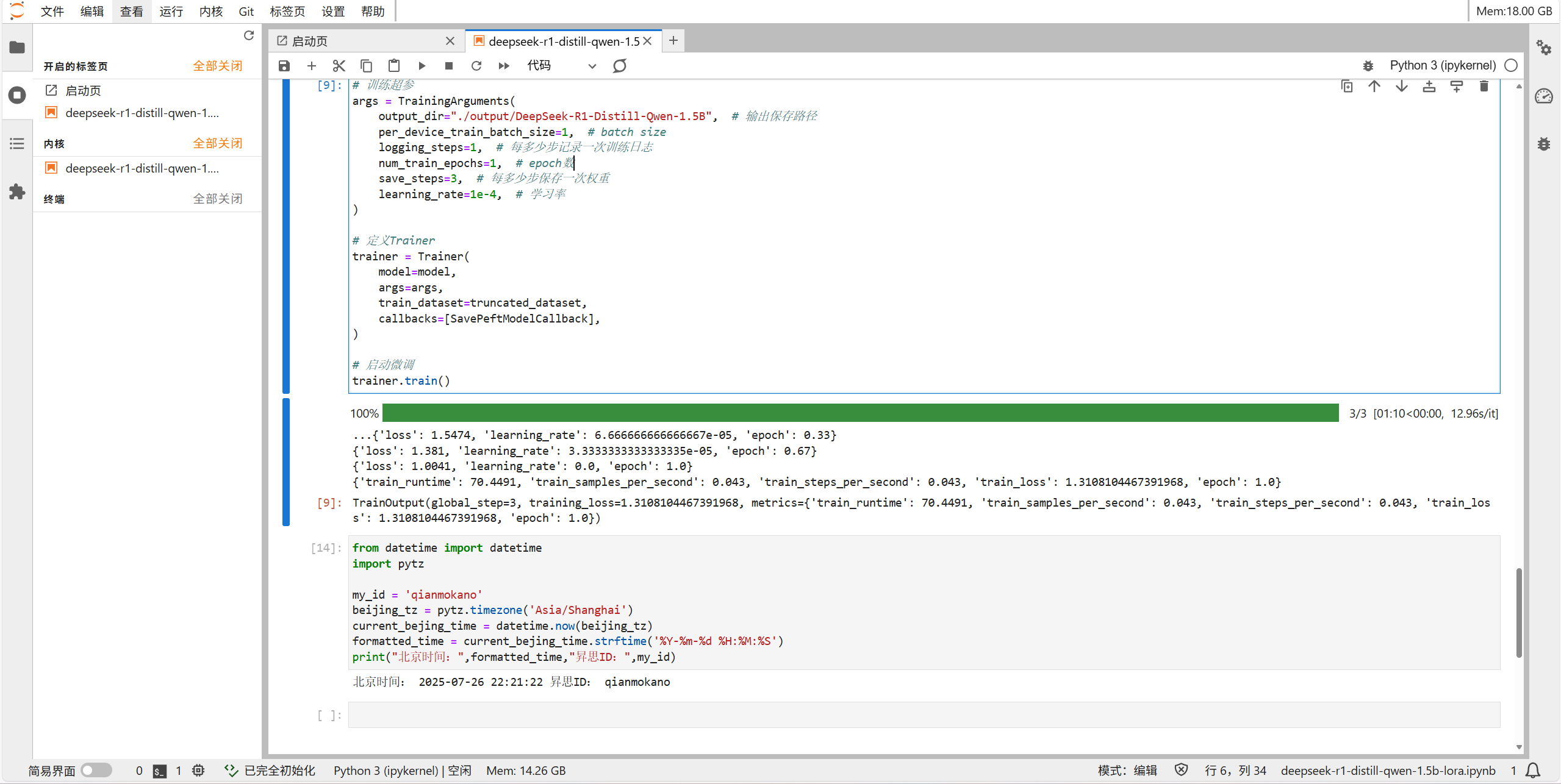
model.trainable_params()可查看参与微调的参数,确认其仅占总参数量的0.5%。

昇思+开发板微调实战全流程要点
- 前期准备:环境准备与检查、代码下载、权重下载等操作与开发与适配章节一致,其中权重下载耗时较长,本次分享已提前完成;为便于问题快速定位,建议通过
mindspore.set_context(pynative_synchronize=True)开启同步。 - 数据预处理实现:MindSpore采用数据处理Pipeline进行数据预处理,所有数据变换通过
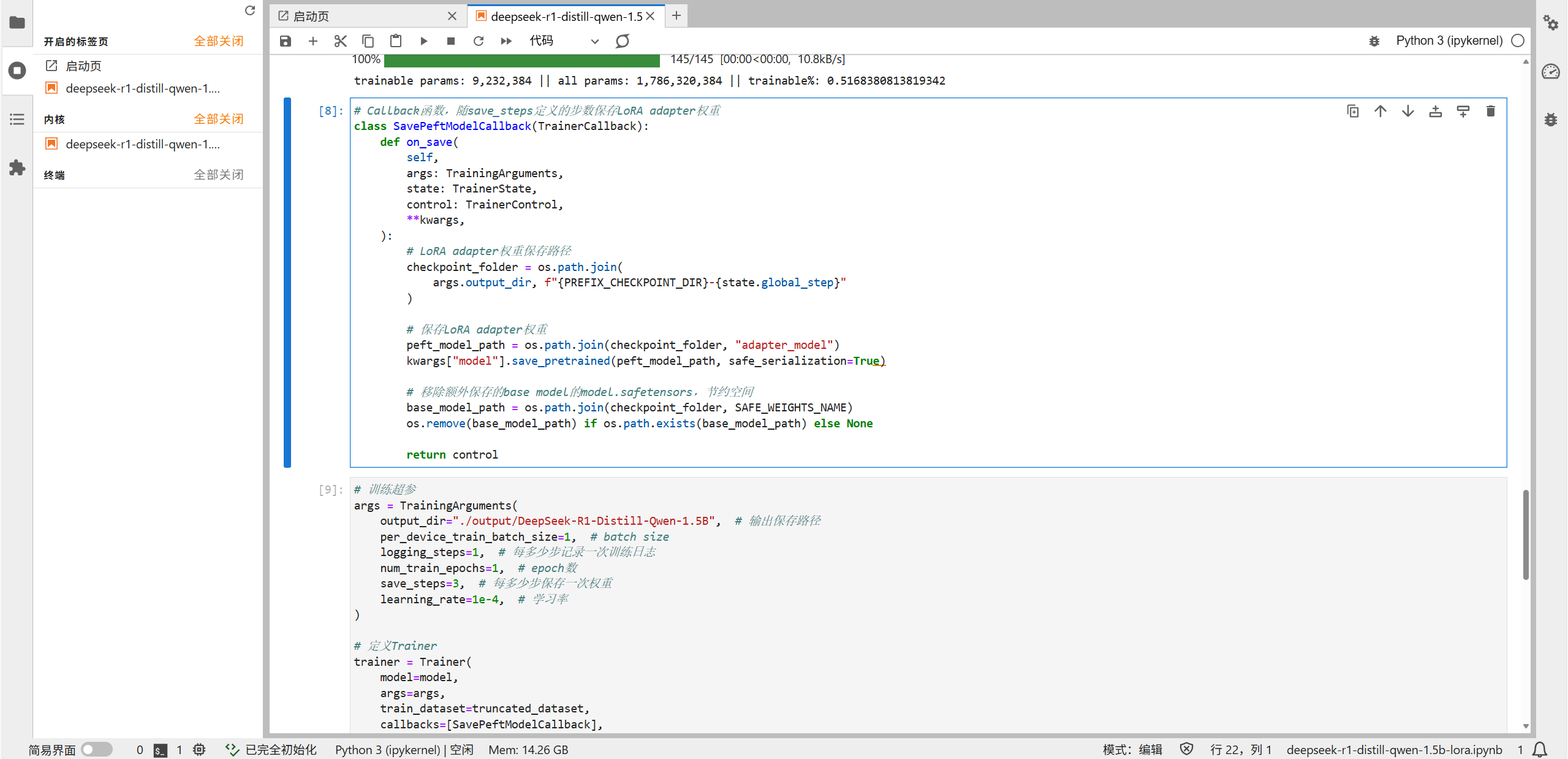
.map(...)方法传入,该方法可针对数据集的指定列添加数据变换,既支持执行Dataset模块提供的内置变换操作,也支持执行用户自定义的变换操作,变换会应用于该列数据的每个元素,并返回包含变换后元素的新数据集。 - 模型权重保存:脚本中自定义了
SavePeftModelCallback,其作用是在每经过save_steps个步数后,将模型当前的LoRA adapter权重保存下来,保存路径为“./output/DeepSeek-R1-Distill-Qwen1.5B/adapter_model”,保存的内容包括adapter_config.json、adapter_model.safetensors等文件。
内存与显存优化方案
- 问题背景:香橙派AIpro的host侧和device侧共享内存,因此host侧的内存占用(如Python多进程、模型加载等)会对显存产生影响。
- 具体优化措施:
-
直接加载fp16格式的权重,而非先加载fp32权重再转换为fp16,例如使用模型ID“THsiao/DeepSeek-R1-Disti1-Qwen-1.5B-FP16”进行加载,可有效减少内存占用。
-
通过设置环境变量控制Python进程数量,具体为
export MAX_COMPILE_CORE_NUMBER=1和export TE_PARALLEL_COMPILER=1,将进程数控制在4-6个,从而减少额外内存占用对显存的影响。
-
在开启新终端时,手动限制进程的最大内存占用,可通过创建cgroup(如
python_limit)并设置内存限制(如4G),再将当前进程归入该组实现;该操作已编写为mem_limit.sh脚本,存放在案例代码同路径下,每次新开终端需运行bash mem_limit.sh。
-



实操
环境准备
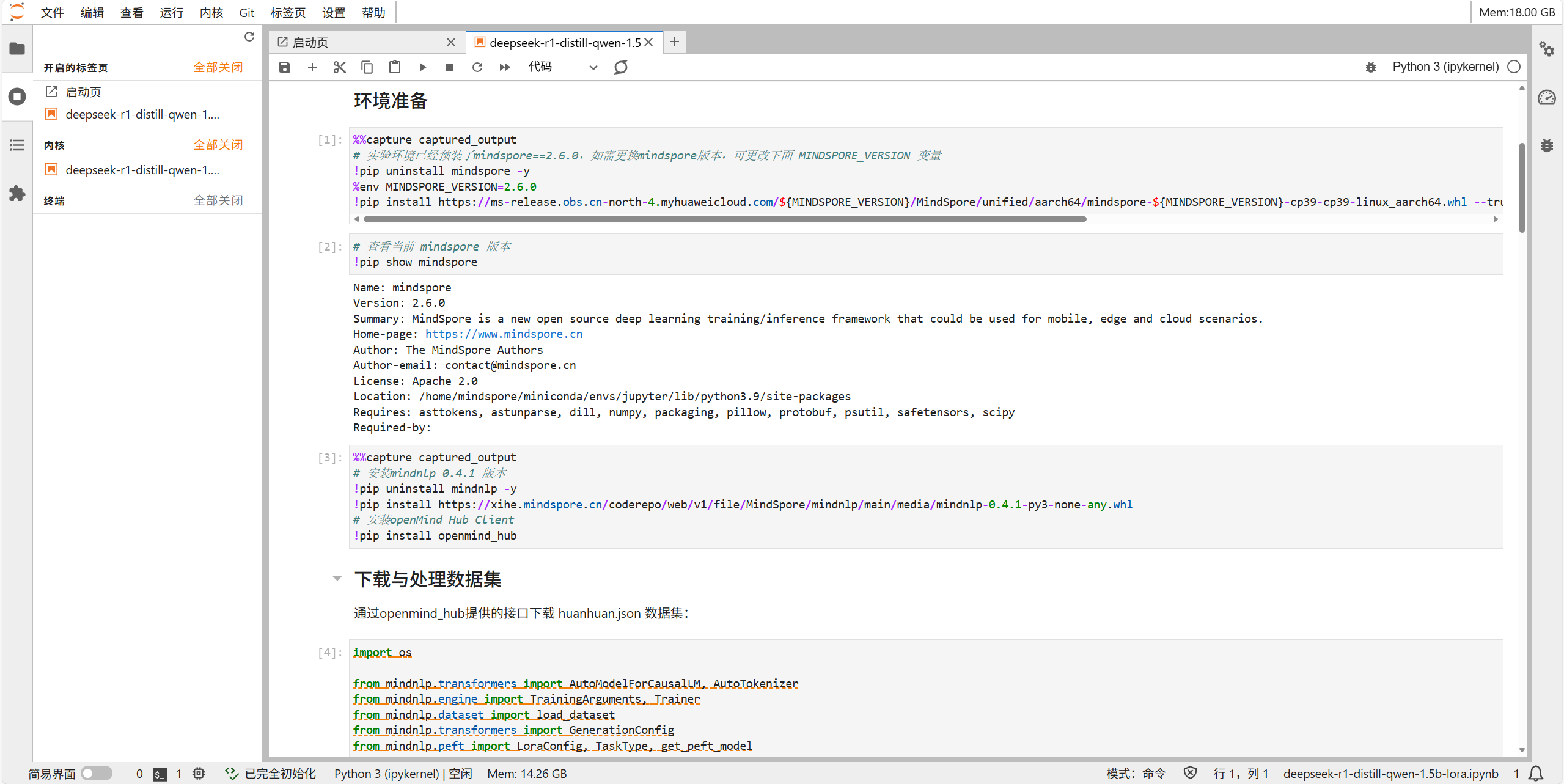
下载与处理数据集
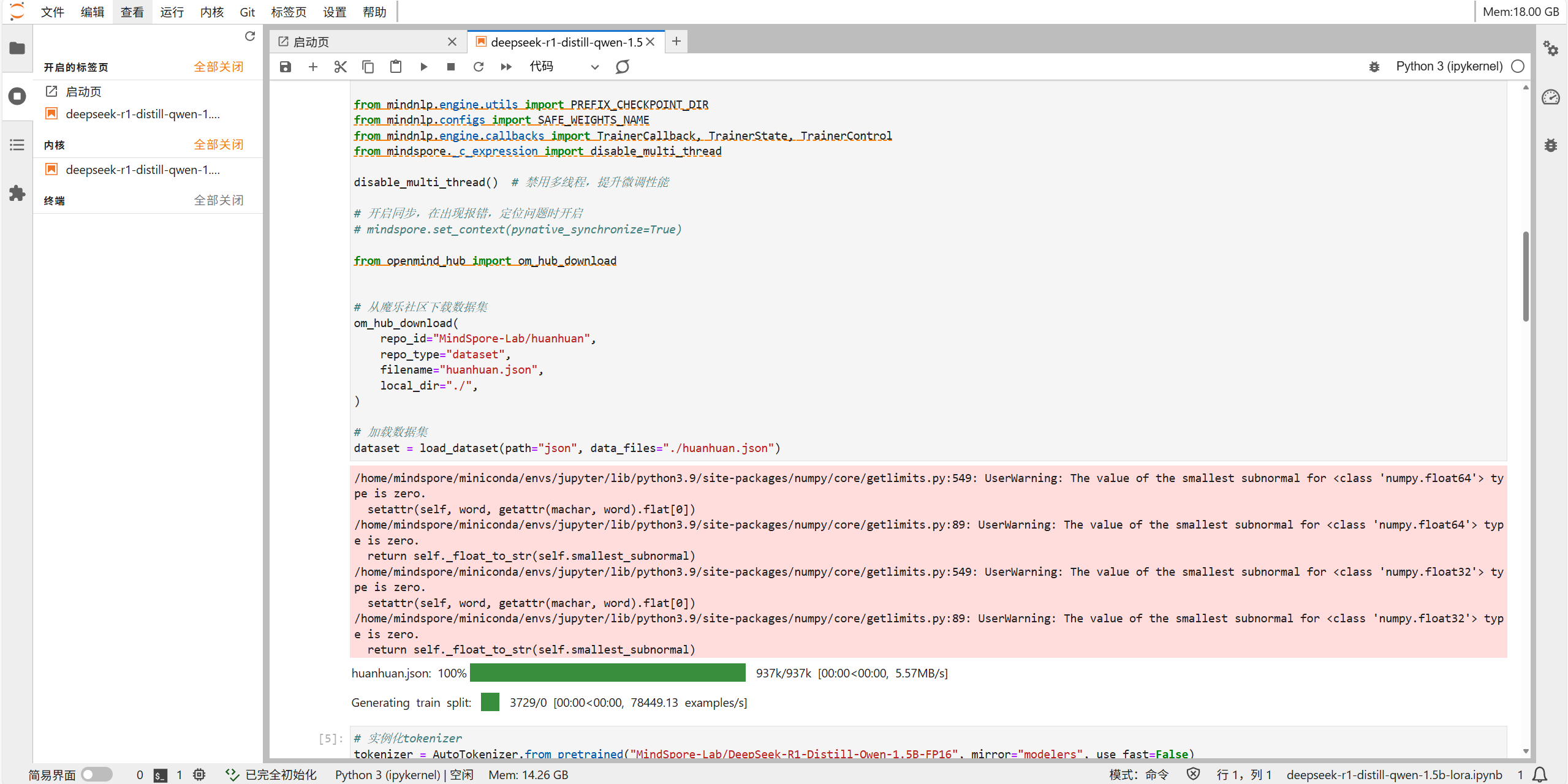
出现的NumPy警告为关于浮点数的子正规值(subnormal numbers)的警告,是常见的数值计算提示,可以忽略,不影响程序运行。
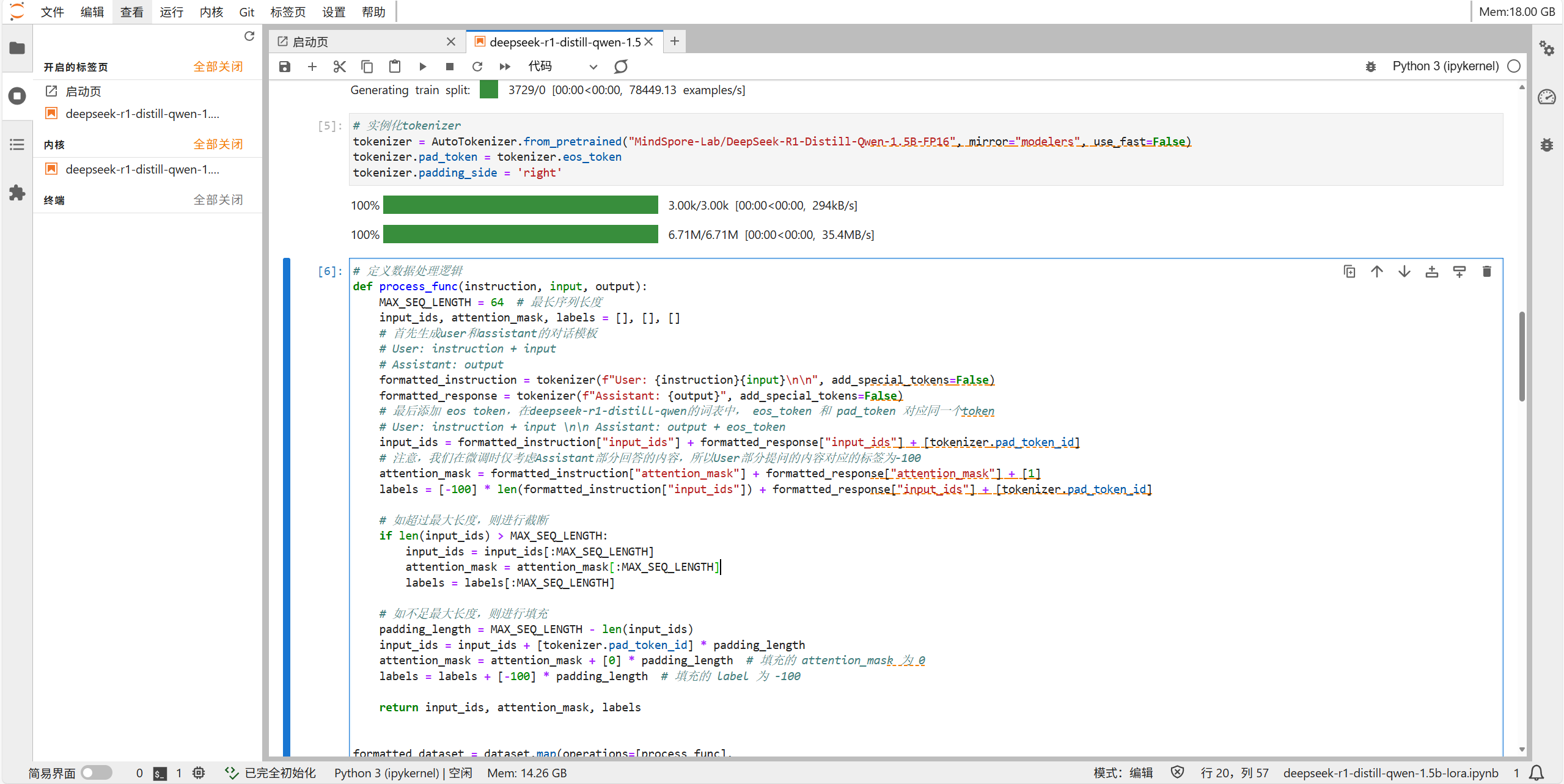
执行微调
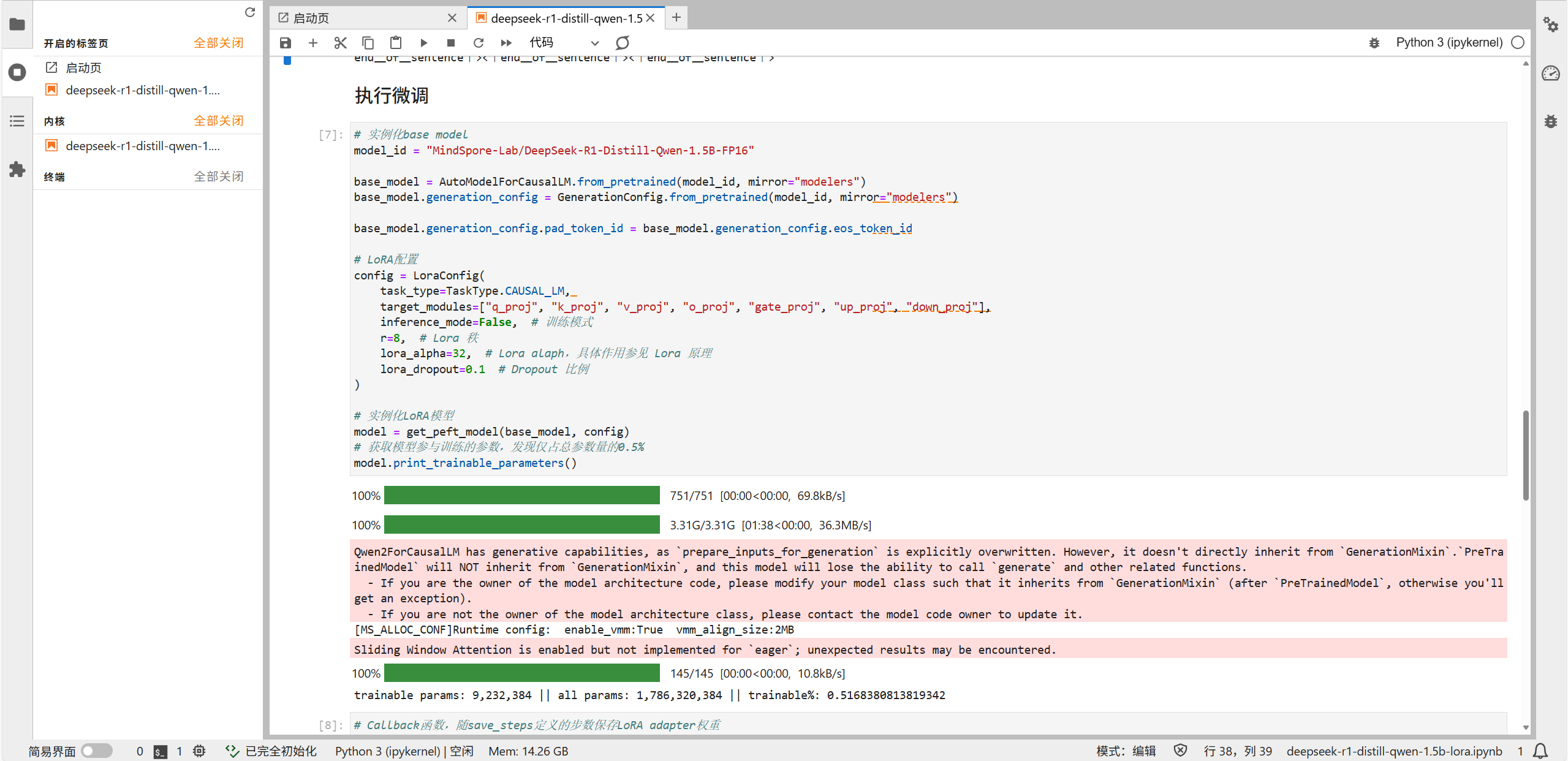
红色为关于
Qwen2ForCausalLM的生成能力警告,指出虽然模型有生成功能,但没有直接继承GenerationMixin,可能会影响generate等函数的使用,不影响代码执行