今天学习了课程的第4章, 基于昇思大模型平台,对 DeepSeek-R1-Distill-Qwen-1.5B 模型进行 LoRA 微调,使得模型可以模仿《甄嬛传》中甄嬛的语气风格进行对话。
通过代码内注释找到数据集来源,开源为魔乐社区。
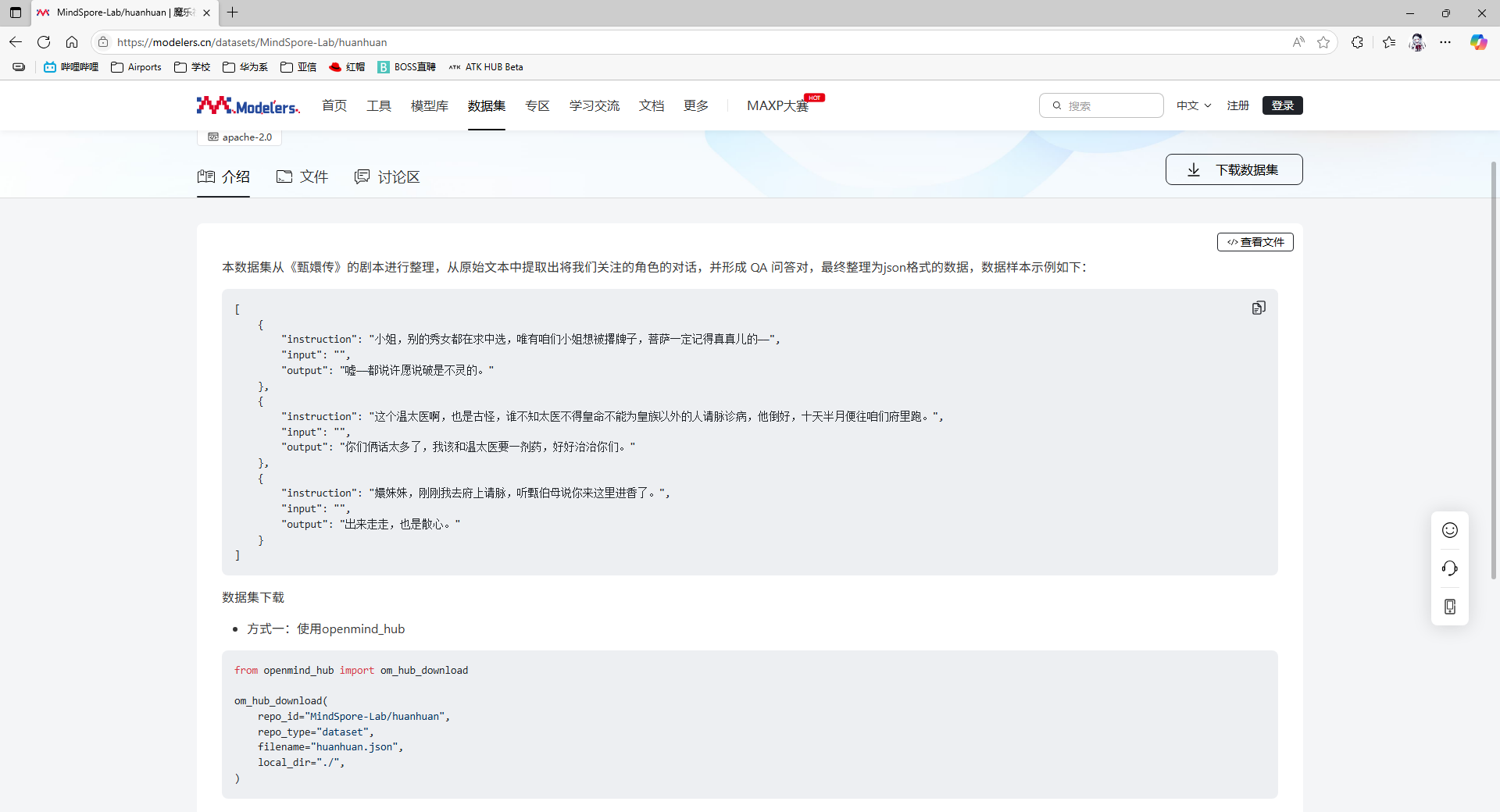
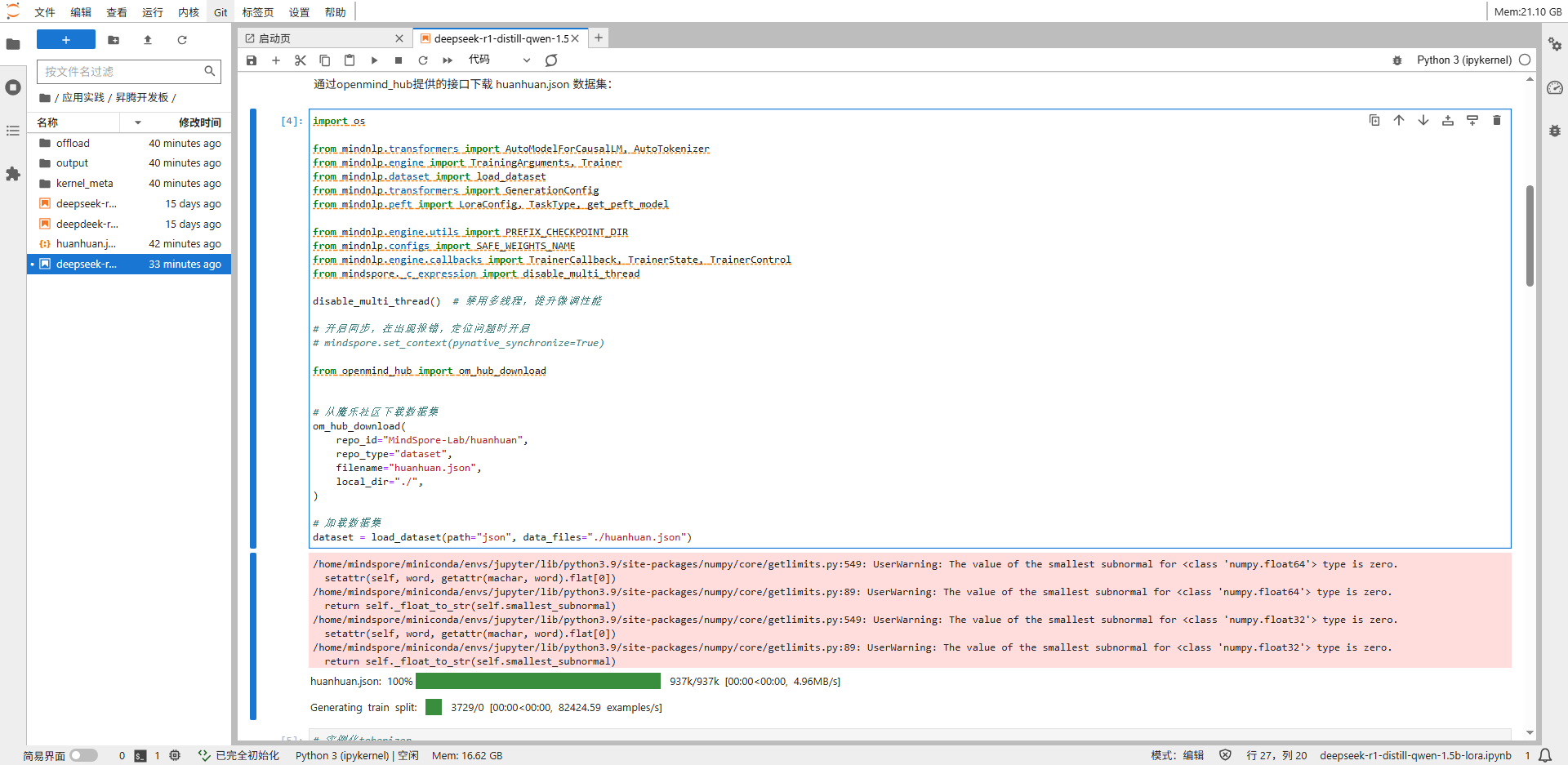
通过mindnlp的load_dataset函数导入下载的数据。
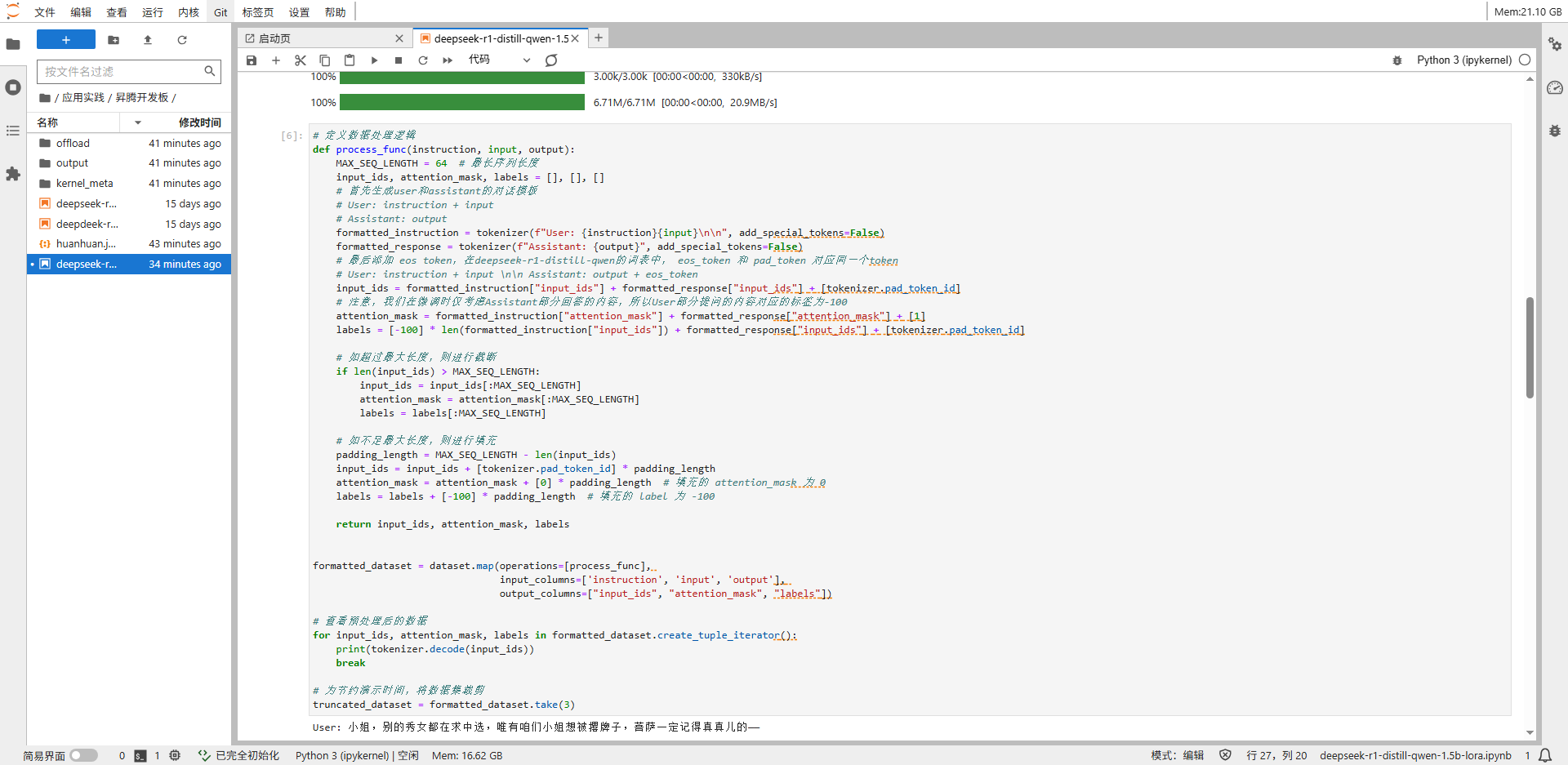
定义数据处理逻辑并查看部分数据。
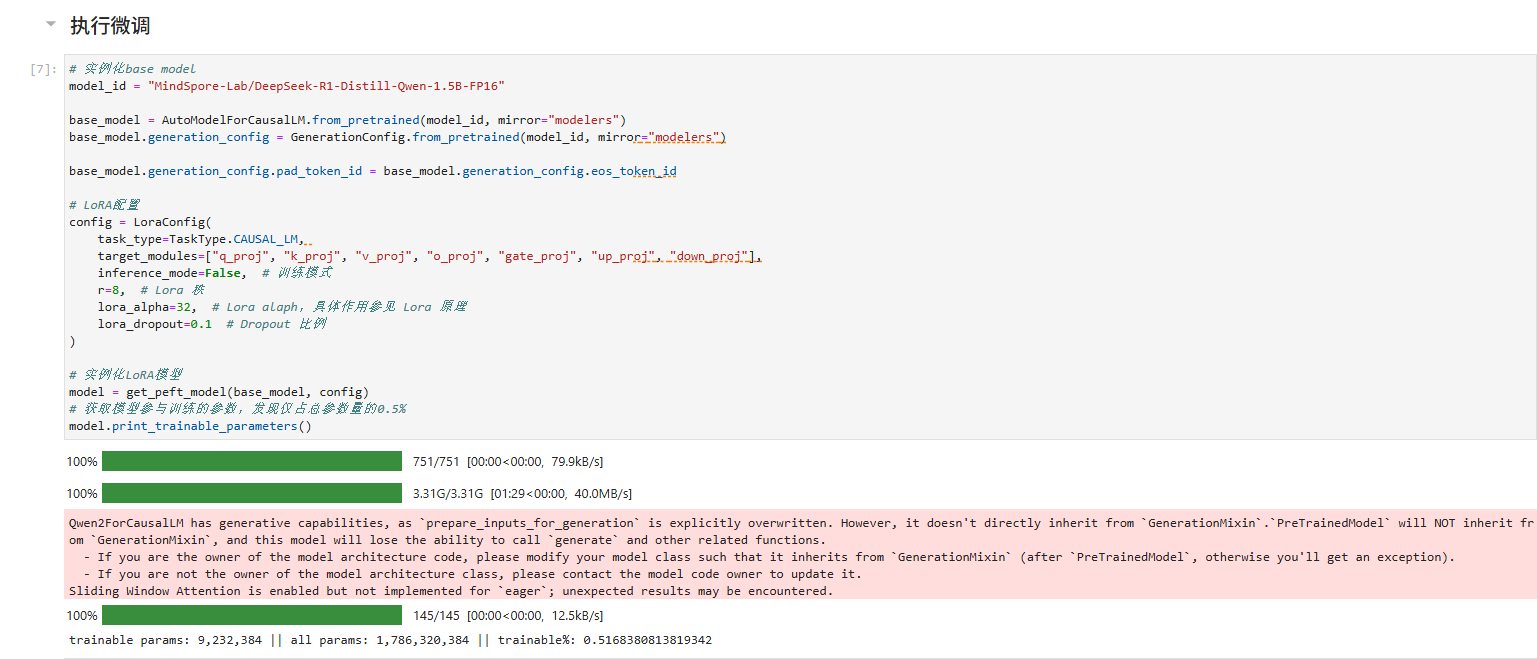
对LoRA模型模型进行配置并实例化。
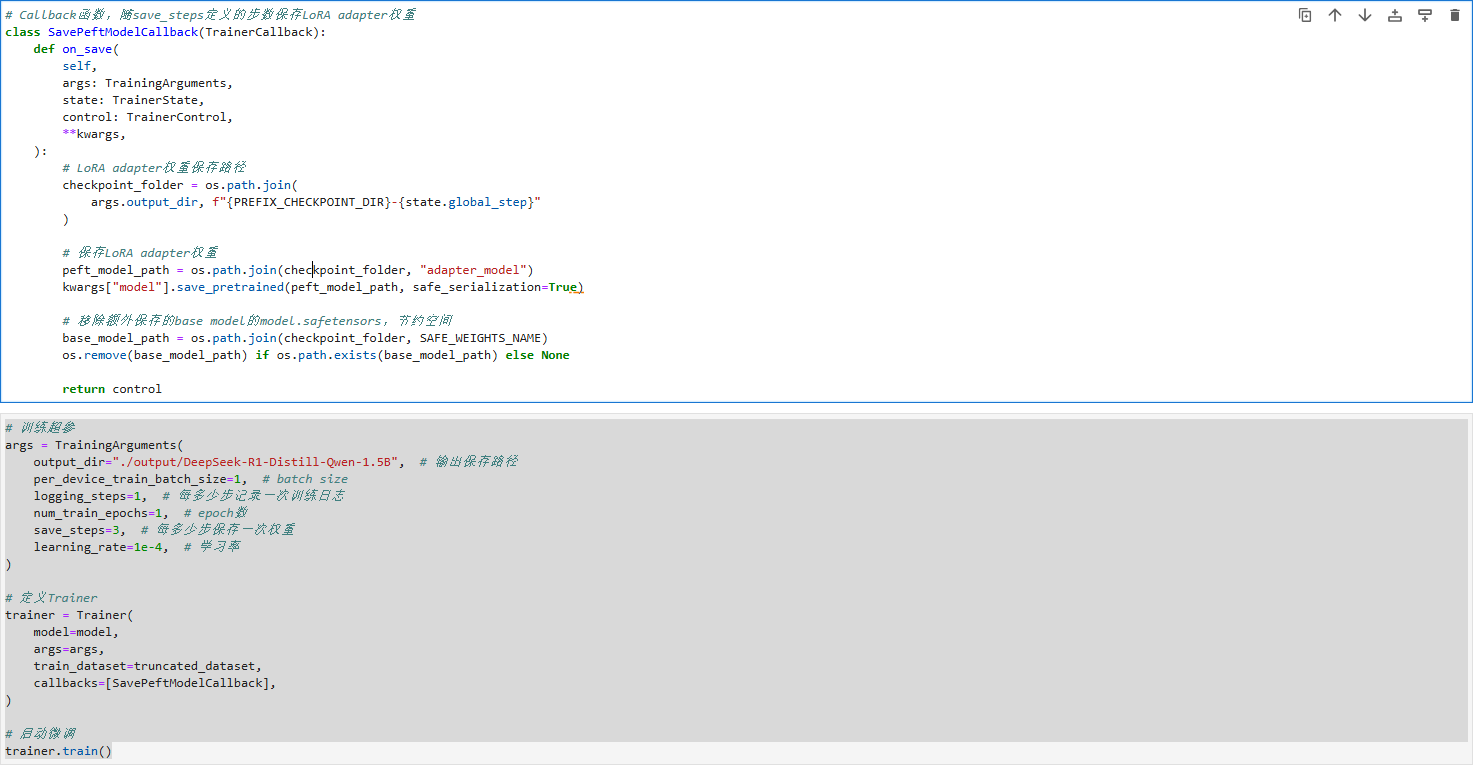
自定义回调函数在每3步训练时仅保存LoRA适配器权重并自动删除冗余基础模型文件,配置批次大小、学习率1e-4和输出路径等训练参数,最终启动Trainer利用LoRA技术对模型进行微调。

整个实验在昇腾单卡环境下完成轻量化训练,并展示了如何高效定制大语言模型的对话风格。