本文将分享我们在将DETR目标检测模型从PyTorch迁移至MindSpore框架过程中的实践经验,涵盖核心架构映射、兼容性补丁设计、算子迁移细节以及动态形状处理等关键技术点,希望能为正在经历类似迁移工作的开发者提供参考。
一、迁移背景与挑战
DETR(Detection Transformer)是近年来目标检测领域的重要创新,它基于Transformer架构,简化了传统目标检测的复杂流程。将这样一个复杂的模型迁移到MindSpore框架,我们面临以下几个核心挑战:
1.API兼容性:PyTorch与MindSpore的API设计存在差异
2.动态形状支持:DETR中的网格生成等操作涉及动态形状
3.图模式限制:MindSpore的Graph模式对Python语法的限制
4.算子对齐:部分算子在行为上存在细微差别
二、核心映射
MindSpore提供了mint模块作为PyTorch的兼容层,但在实际使用中发现该模块仍不够完整,特别是mint.nn缺少许多容器类和模块。为此,我们设计了两个关键补丁文件来填补功能缺口。
2.1 nn_compat.py:容器类补丁
# 示例:补丁实现的核心思路
class Module:
"""与PyTorch的nn.Module保持API一致"""
def __init__(self):
self._parameters = {}
self._modules = {}
# 确保register_buffer等关键方法可用
这个补丁主要解决:
1.nn.ModuleList、nn.ModuleDict等容器类的缺失;
2.register_buffer方法的实现(MindSpore中需要使用Parameter(requires_grad=False)替代);
3.模块初始化流程的对齐。
2.2 mint_patch.py:运行时动态注入
在程序入口处动态注入缺失的方法和属性:
# 注入上下文管理器
import contextlib
if not hasattr(mint, 'no_grad'):
mint.no_grad = contextlib.nullcontext
这种动态注入的方式确保了第三方脚本调用时不会因为API缺失而报错,是一种轻量级的兼容性解决方案。
三、算子迁移
3.1 权重初始化
在__init__方法中进行权重初始化时,必须使用NumPy生成数据再转为Tensor,因为此时NPU算子尚未就绪:
def __init__(self):
# 正确做法
weight_np = np.random.randn(out_channels, in_channels, kernel_size)
self.weight = Parameter(Tensor(weight_np, mindspore.float32))
# 错误做法:直接在NPU上创建随机张量可能失败
# self.weight = Parameter(ops.randn(out_channels, in_channels, kernel_size))
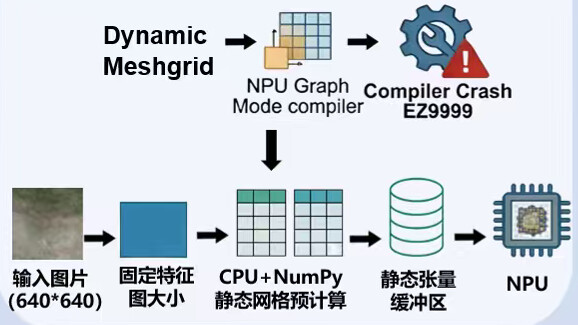
3.2 Anchor生成与动态形状处理
DETR中的Anchor生成涉及网格创建操作。原生ops.Meshgrid在动态形状场景下不够稳定,我们采用以下方案:
# 使用NumPy预计算静态网格
def generate_anchors(feature_map_size):
# 在CPU上使用NumPy生成网格
x = np.arange(feature_map_size[1])
y = np.arange(feature_map_size[0])
xx, yy = np.meshgrid(x, y)
# 转换为Tensor并存入静态缓冲区
return Tensor(xx), Tensor(yy)
3.3 关键算子差异处理
| PyTorch算子 | MindSpore对应 | 注意事项 |
|---|---|---|
| tensor.detach() | ops.stop_gradient() | 功能等价,但API不同 |
| torch.arange(device=xxx) | ops.arange() | MindSpore不支持device参数 |
| tensor.expand(*size) | tensor.expand(tuple(size)) | 只接受单一tuple参数 |
| nn.LayerNorm(hidden_size) | nn.LayerNorm((hidden_size,)) | 需传入tuple,补丁版支持int |
| nn.Dropout(p=0.5) | nn.Dropout(keep_prob=0.5) | 补丁版已转换p参数语义 |
| nn.Conv2d(…, padding=1) | 需显式设置pad_mode=‘pad’ | 否则padding行为不一致 |
3.4 Focal Loss扩展算子实现
在目标检测任务中,Focal Loss对于类别不平衡问题至关重要。我们在CUDA/NPU上实现了高性能的扩展算子:
def focal_loss(logits, targets, alpha=0.25, gamma=2.0):
# 计算BCE with logits
bce_loss = ops.binary_cross_entropy_with_logits(logits, targets)
# 计算pt = exp(-bce_loss)
pt = ops.exp(-bce_loss)
# 计算focal weight = (1 - pt) ** gamma
focal_weight = (1 - pt) ** gamma
# 逐元素相乘并应用alpha
loss = alpha * focal_weight * bce_loss
return loss
四、图模式(Graph Mode)下的限制与技巧
MindSpore的Graph模式通过静态图编译实现高性能,但带来了一些编程限制。
4.1 禁止在construct中修改self属性
def construct(self, x):
# 错误:不能在Graph模式下修改self属性
# self.temp = x
# ✓ 正确:使用局部变量
temp = x
return self.process(temp)
4.2 动态类型判断的限制
def construct(self, x):
# 错误:不能使用Python动态类型判断
# if isinstance(x, tuple):
# return self.process_tuple(x)
# ✓ 正确:使用shape信息或类型标记
if len(x.shape) == 4:
return self.process_image(x)
4.3 PyNative模式下的技巧
在需要临时修改模型状态(如encoder的auxiliary loss控制)的场景下,可以使用PyNative模式:
def forward_with_aux(self, x, enable_aux=True):
# 切换到PyNative模式
self.set_train(mode=False)
self._enable_aux = enable_aux
result = self.construct(x)
# 恢复原始状态
self._enable_aux = False
self.set_train(mode=True)
return result
五、权重加载兼容性
迁移过程中需要同时支持多种权重格式:
| 格式 | 说明 |
|---|---|
| .ckpt | MindSpore原生格式 |
| .npz | NumPy标准格式 |
| .npyz | 大权重压缩格式(支持分块存储) |

我们实现了统一的权重加载接口,能够自动识别格式并进行转换:
def load_weights(model, weight_path):
if weight_path.endswith('.ckpt'):
load_mindspore_weights(model, weight_path)
elif weight_path.endswith('.npz'):
load_numpy_weights(model, weight_path)
elif weight_path.endswith('.npyz'):
load_compressed_weights(model, weight_path)
六、结果展示
我们使用迁移至MindSpore框架下的DETR模型进行无人机电力线缺陷巡检实验,下面为我们的实测效果:


整体来看,迁移后的 DETR 模型在真实巡检场景下保持了与原始 PyTorch 版本相当甚至更优的检测效果,充分验证了从 PyTorch 到 MindSpore 框架迁移的技术可行性与实际应用价值。
七、经验总结
1.补丁先行:在开始迁移前,先建立完整的API兼容补丁,可以大幅减少后续的修改量。
2.分阶段验证:建议按照"单个算子验证 → 模块验证 → 端到端验证"的流程推进,及时发现问题。
3.充分利用MindSpore特性:迁移不是简单的API替换,可以结合MindSpore的自动并行、图优化等特性,提升模型性能。
4.动态形状场景优先使用NumPy:对于网格生成等涉及动态形状的操作,在CPU上使用NumPy预计算再转为静态Tensor是更稳妥的方案。
5.保持与原始实现的对齐:在补丁层做好协议转换,使得原始PyTorch代码只需少量修改即可运行。
希望本文的分享能够帮助到正在或将要进行MindSpore迁移的开发者们。欢迎在评论区交流讨论!