如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
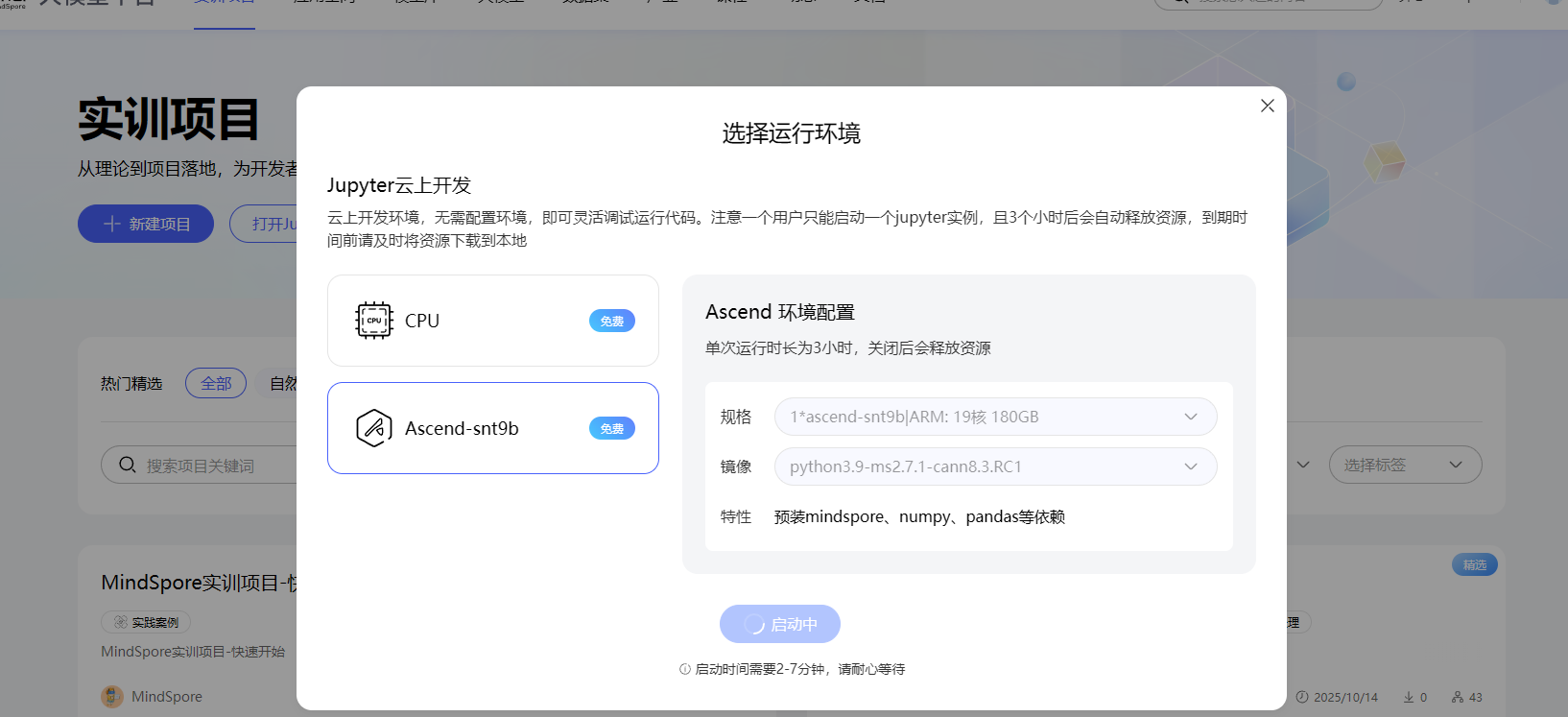
进入昇思大模型官网昇思大模型平台
选择实训项目中的新建项目,环境选Ascend
创建完成之后,在MindSpore官网中的案例下载:https://github.com/mindspore-lab/applications/blob/r2.7/cv/sam/inference_sam_segmentation.ipynb 并上传到环境中
因为用的是昇思大模型平台的Jupyter在线编程环境中运行本案例,需要取消如下代码的注释,进行依赖库安装
二、案例实现
import os
import requests
import numpy as np
import mindspore as ms
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
from pathlib import Path
from mindnlp.transformers import SamModel, SamProcessor
导入必要的库,包括MindSpore、MindNLP以及用于图像处理的PIL和Matplotlib。
def download_image(url: str, save_dir: str = ".") -> str:
"""
从 URL 下载图片到 save_dir,返回本地文件路径(字符串)。
"""
save_path = Path(save_dir)
save_path.mkdir(parents=True, exist_ok=True)
filename = (url.rsplit("/", 1)[-1] or "image.jpg")
dst = save_path / filename
try:
resp = requests.get(url, timeout=30)
resp.raise_for_status()
dst.write_bytes(resp.content)
print(f"示例图片已成功下载到: {dst}")
return str(dst)
except Exception as e:
print(f"下载示例图片时出错: {e}")
return ""
# 使用示例
image_url = "https://raw.githubusercontent.com/facebookresearch/segment-anything/main/notebooks/images/dog.jpg"
downloaded_image = download_image(image_url)
if downloaded_image:
print(f"示例图片已保存为: {downloaded_image}")
定义并执行下载图片的函数,获取示例图片dog.jpg。
img_path = "dog.jpg" # <-- change to your image path
assert os.path.exists(img_path), f"Image not found: {img_path}"
# Custom bbox in original image coordinates [x1,y1,x2,y2]
bbox = [0, 217, 450, 800] # <-- change if needed, ensure in-bounds
bbox = [int(x) for x in bbox] # keep as Python ints for clarity
image = Image.open(img_path).convert("RGB")
W, H = image.size
print("图片尺寸:", (W, H), "| BBox:", bbox)
plt.figure(figsize=(6,4))
plt.imshow(image)
ax = plt.gca()
rect = patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0], bbox[3]-bbox[1],
linewidth=2, edgecolor='yellow', facecolor='none')
ax.add_patch(rect)
plt.title("Original image with input box")
plt.axis("off")
plt.show()
读取图片并设置提示框(BBox)。bbox采用原图坐标系[x1, y1, x2, y2]。
可视化原图及输入的提示框,确保框选位置正确。
MODEL_ID = "facebook/sam-vit-base"
CACHE_DIR = os.path.expanduser("~/.cache/mindnlp") # or "/tmp/mindnlp"
os.makedirs(CACHE_DIR, exist_ok=True)
# (可选)将其他库的缓存目录对齐到同一路径
os.environ["HF_HOME"] = CACHE_DIR
os.environ["MINDNLP_HOME"] = CACHE_DIR
print("正在加载 SAM ...")
processor = SamProcessor.from_pretrained(MODEL_ID, cache_dir=CACHE_DIR)
model = SamModel.from_pretrained(MODEL_ID, cache_dir=CACHE_DIR)
model.set_train(False)
print("加载完成!")
加载预训练模型facebook/sam-vit-base和对应的处理器SamProcessor。SamProcessor负责图像预处理,SamModel负责推理。
inputs = processor(images=image, input_boxes=[[bbox]], return_tensors="pt")
outputs = model(**inputs)
将图像和提示框传入处理器,获取模型输入张量,然后执行模型推理。
pred_masks = outputs.pred_masks # (B, boxes, M, 256, 256)
iou_scores = outputs.iou_scores # (B, boxes, M)
print("pred_masks 形状:", tuple(pred_masks.shape))
print("iou_scores 形状:", tuple(iou_scores.shape))
# preview low-res candidate masks (M masks at 256x256)
pm = pred_masks[0, 0].asnumpy() # (M, 256, 256)
scores_np = iou_scores[0, 0].asnumpy()
M = pm.shape[0]
fig, axes = plt.subplots(1, M, figsize=(4*M, 4))
if M == 1:
axes = [axes]
for i in range(M):
axes[i].imshow(pm[i] > 0, cmap="gray")
axes[i].set_title(f"Mask {i}\nIoU≈{float(scores_np[i]):.3f}")
axes[i].axis("off")
plt.suptitle("Low-res candidate masks (256×256)")
plt.tight_layout()
plt.show()
提取模型输出的预测掩码pred_masks和IoU分数iou_scores。SAM通常会输出3个不同层级的候选掩码。

可视化低分辨率的候选掩码及其对应的IoU分数。
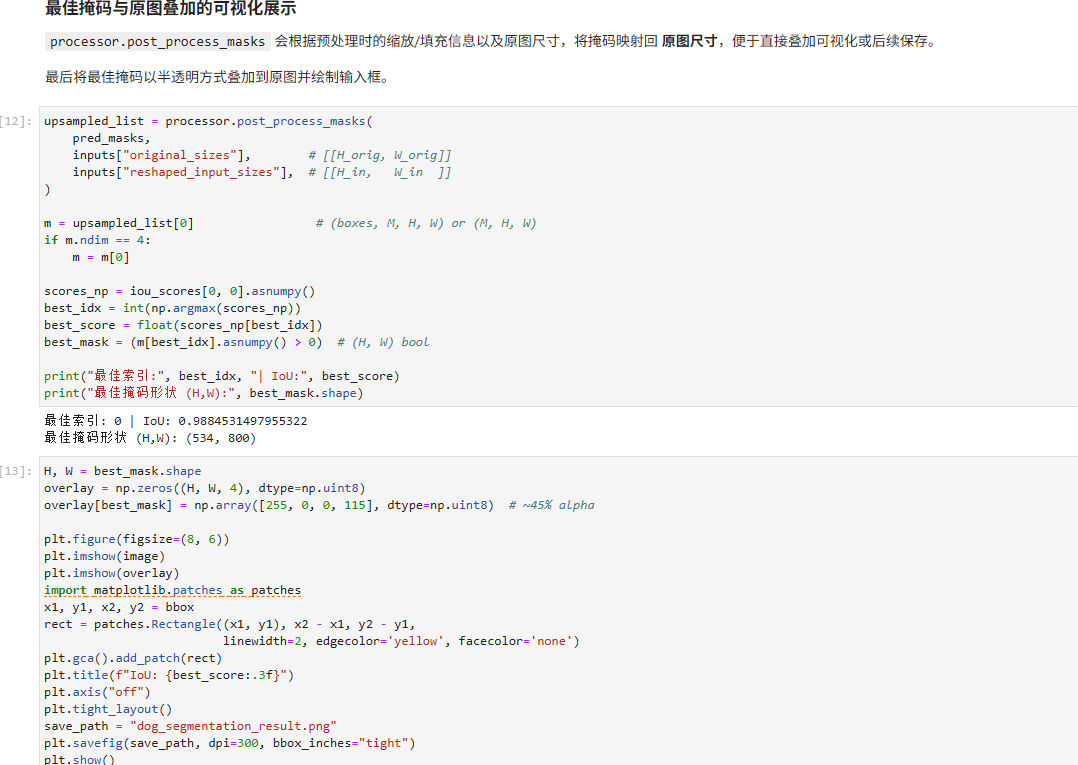
upsampled_list = processor.post_process_masks(
pred_masks,
inputs["original_sizes"], # [[H_orig, W_orig]]
inputs["reshaped_input_sizes"], # [[H_in, W_in ]]
)
m = upsampled_list[0] # (boxes, M, H, W) or (M, H, W)
if m.ndim == 4:
m = m[0]
scores_np = iou_scores[0, 0].asnumpy()
best_idx = int(np.argmax(scores_np))
best_score = float(scores_np[best_idx])
best_mask = (m[best_idx].asnumpy() > 0) # (H, W) bool
print("最佳索引:", best_idx, "| IoU:", best_score)
print("最佳掩码形状 (H,W):", best_mask.shape)
使用post_process_masks将掩码还原回原图尺寸,并根据IoU分数选取最佳掩码。
H, W = best_mask.shape
overlay = np.zeros((H, W, 4), dtype=np.uint8)
overlay[best_mask] = np.array([255, 0, 0, 115], dtype=np.uint8) # ~45% alpha
plt.figure(figsize=(8, 6))
plt.imshow(image)
plt.imshow(overlay)
import matplotlib.patches as patches
x1, y1, x2, y2 = bbox
rect = patches.Rectangle((x1, y1), x2 - x1, y2 - y1,
linewidth=2, edgecolor='yellow', facecolor='none')
plt.gca().add_patch(rect)
plt.title(f"IoU: {best_score:.3f}")
plt.axis("off")
plt.tight_layout()
save_path = "dog_segmentation_result.png"
plt.savefig(save_path, dpi=300, bbox_inches="tight")
plt.show()
print("已保存:", save_path)
将最佳掩码叠加在原图上显示,并绘制输入框,展示最终的分割效果。