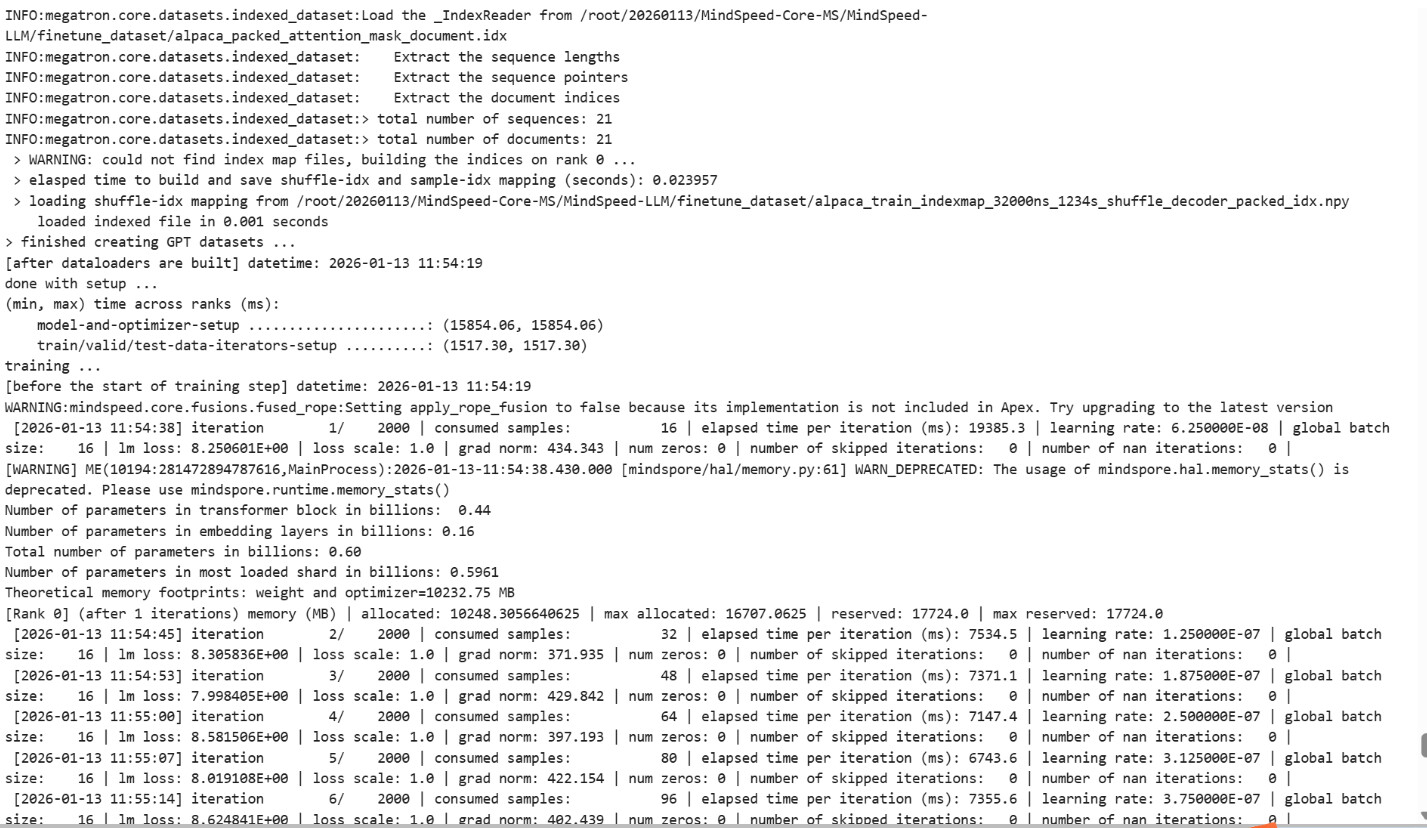
环境:CANN 8.3.RC1,910B4,8张32G卡,Mindspore2.7.1, AtomGit | GitCode - 全球开发者的开源社区,开源代码托管平台
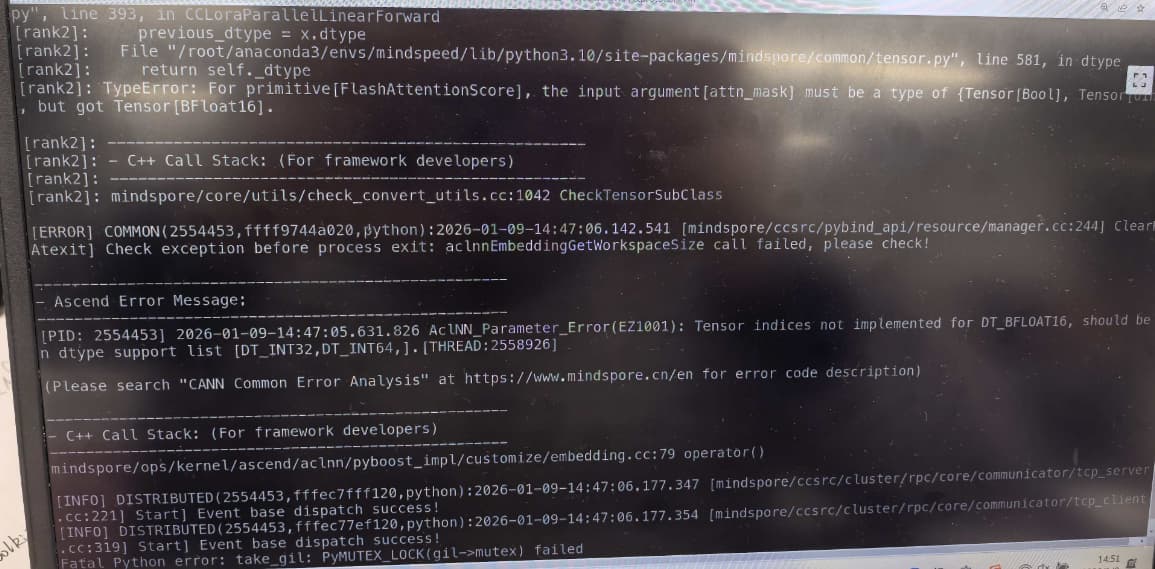
大概2个错误是:
-
FlashAttention 的 attn_mask 类型错误报错明确指出:
FlashAttentionScore的attn_mask需要是Tensor[Bool]或Tensor[uint8],但实际传入了Tensor[BFloat16]。 -
昇腾 CANN 不支持 BF16 作为张量索引类型昇腾错误
E21001说明:张量索引不支持DT_BFLOAT16,仅支持DT_INT32/DT_INT64。
模型权重转化脚本:
python convert_ckpt.py \
--use-mcore-models \
--model-type GPT \
--load-model-type hf \
--save-model-type mg \
--target-tensor-parallel-size 1 \
--target-pipeline-parallel-size 1 \
--load-dir /root/autodl-tmp/Qwen3-0.6/ \
--save-dir ./model_weights/Qwen3-0.6B-mcore \
--tokenizer-model /root/autodl-tmp/Qwen3-0.6/tokenizer.json \
--model-type-hf qwen3 \
--params-dtype bf16 \
--spec mindspeed_llm.tasks.models.spec.qwen3_spec layer_spec
微调脚本:
#!/bin/bash
export CUDA_DEVICE_MAX_CONNECTIONS=1
# Change for multinode config
NPUS_PER_NODE=1
MASTER_ADDR=localhost
MASTER_PORT=6015
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($NPUS_PER_NODE*$NNODES))
# please fill these path configurations
CKPT_LOAD_DIR="/root/autodl-tmp/MindSpeed-LLM/model_weights/Qwen3-0.6B-mcore"
CKPT_SAVE_DIR="/root/autodl-tmp/MindSpeed-LLM/model_weights/Qwen3-0.6B-finetuned"
# DATA_PATH="/root/autodl-tmp/dataset/success_province_train.jsonl"
DATA_PATH="/root/autodl-tmp/MindSpeed-LLM/finetune_dataset/alpaca_packed_input_ids_document"
TOKENIZER_PATH="/root/autodl-tmp/Qwen3-0.6/"
TP=1
PP=1
MBS=1
GBS=16
SEQ_LENGTH=8192
TRAIN_ITERS=2000
DISTRIBUTED_ARGS="
--nproc_per_node $NPUS_PER_NODE \
--nnodes $NNODES \
--node_rank $NODE_RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT
"
GPT_ARGS="
--use-mcore-models \
--tensor-model-parallel-size ${TP} \
--pipeline-model-parallel-size ${PP} \
--sequence-parallel \
--spec mindspeed_llm.tasks.models.spec.qwen3_spec layer_spec \
--kv-channels 128 \
--use-flash-attn \
--qk-layernorm \
--num-layers 28 \
--hidden-size 1024 \
--use-rotary-position-embeddings \
--num-attention-heads 16 \
--ffn-hidden-size 3072 \
--max-position-embeddings 32768 \
--seq-length ${SEQ_LENGTH} \
--train-iters ${TRAIN_ITERS} \
--micro-batch-size ${MBS} \
--global-batch-size ${GBS} \
--make-vocab-size-divisible-by 1 \
--padded-vocab-size 151936 \
--rotary-base 1000000 \
--disable-bias-linear \
--swiglu \
--tokenizer-type PretrainedFromHF \
--tokenizer-name-or-path ${TOKENIZER_PATH} \
--normalization RMSNorm \
--position-embedding-type rope \
--norm-epsilon 1e-6 \
--hidden-dropout 0 \
--attention-dropout 0 \
--no-gradient-accumulation-fusion \
--attention-softmax-in-fp32 \
--exit-on-missing-checkpoint \
--no-masked-softmax-fusion \
--group-query-attention \
--num-query-groups 8 \
--seed 42 \
--bf16 \
--min-lr 1.25e-7 \
--weight-decay 1e-1 \
--lr-warmup-fraction 0.01 \
--clip-grad 1.0 \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--no-load-optim \
--no-load-rng \
--lr 1.25e-5 \
"
DATA_ARGS="
--data-path $DATA_PATH \
--split 100,0,0
"
OUTPUT_ARGS="
--log-interval 1 \
--save-interval 5000 \
--eval-interval ${TRAIN_ITERS} \
--eval-iters 0 \
--log-throughput
"
# --is-instruction-dataset \
TUNE_ARGS="
--finetune \
--stage sft \
--tokenizer-not-use-fast \
--prompt-type qwen \
--no-pad-to-seq-lengths \
--lora-r 16 \
--lora-alpha 32 \
--lora-fusion \
--lora-target-modules linear_qkv linear_proj linear_fc1 linear_fc2
"
torchrun $DISTRIBUTED_ARGS posttrain_gpt.py \
$GPT_ARGS \
$DATA_ARGS \
$OUTPUT_ARGS \
$TUNE_ARGS \
--distributed-backend nccl \
--load ${CKPT_LOAD_DIR} \
--save ${CKPT_SAVE_DIR} \
| tee ./logs/tune_qwen3_0.6b_lora.log
该如何去解决呢