ATC run failed, Please check the detail log, Try ‘atc --help’ for more information
E40021: 2025-10-27-22:03:36.029.084 Failed to compile Op [186Add]. (oppath: [Pre-compile /usr/local/Ascend/ascend-toolkit/8.0.RC2.alpha002/opp/built-in/op_impl/ai_core/tbe/impl/dynamic/add.py failed with errormsg/stack: File “/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/tbe/common/utils/shape_util.py”, line 187, in unify_broadcast_shapes
raise RuntimeError(
RuntimeError: ({‘errCode’: ‘E80013’, ‘op_name’: ‘add’, ‘input1_shape’: ‘80,40’, ‘input2_shape’: ‘1,16,80,80,16’}, ‘In op[add], the inputs[80,40] could not be broadcast together with shapes[1,16,80,80,16].’)
], optype: [Add])
Solution: See the host log for details, and then check the Python stack where the error log is reported.
TraceBack (most recent call last):
Pre-compile op[186Add] failed, oppath[/usr/local/Ascend/ascend-toolkit/8.0.RC2.alpha002/opp/built-in/op_impl/ai_core/tbe/impl/dynamic/add.py], optype[Add], taskID[19]. Please check op’s compilation error message.[FUNC:ReportBuildErrMessage][FILE:fusion_manager.cc][LINE:744]
[SubGraphOpt][Pre-Comp][Node 186Add] Failed to pre-compile. Tid is [255083383933376], TaskId is [19] [FUNC:ProcessFailPreCompTask][FILE:tbe_op_store_adapter.cc][LINE:190]
[SubGraphOpt][Pre-Comp]Failed to process failed task. Thread_id is [255083383933376].[FUNC:ParallelPreCompileOp][FILE:tbe_op_store_adapter.cc][LINE:532]
[SubGraphOpt][Pre-Comp]Failed to pre-compile graph [partition0_rank1_new_sub_graph1][FUNC:PreCompileOp][FILE:op_compiler.cc][LINE:732]
Call OptimizeFusedGraph failed, ret:-1, engine_name:AIcoreEngine, graph_name:partition0_rank1_new_sub_graph1[FUNC:OptimizeSubGraph][FILE:graph_optimize.cc][LINE:126]
subgraph 0 optimize failed[FUNC:OptimizeSubGraphWithMultiThreads][FILE:graph_manager.cc][LINE:1024]
build graph failed, graph id:0, ret:-1[FUNC:BuildModelWithGraphId][FILE:ge_generator.cc][LINE:1615]
GenerateOfflineModel execute failed.
您好,请将详细的环境信息补充完整,方便分析问题~
‘op_name’: ‘add’, ‘input1_shape’: ‘80,40’, ‘input2_shape’: ‘1,16,80,80,16’}, ‘In op[add], the inputs[80,40] could not be broadcast together with shapes[1,16,80,80,16].’
报错很明显,add算子的两个输入shape不一致且无法广播.
提供模型或源代码才能看是否是问题.
"""Network."""
'''这里封装的类 函数在后面主要会调用RetinaFace, RetinaFaceWithLossCell, TrainingWrapper, resnet50这几部分
RetinaFaceWithLossCell, TrainingWrapper只在训练过程调用
resnet50网络模型用于放到retinaface中做backbone,
这里之所以没有将resnet50直接封装为retinaface作为backbone为了便于后面灵活修改backbone类型
RetinaFace(网络)输出候选框 + 对应分类概率 + 关键点坐标的网络 都是相对于priors预测框的偏移量
│
▼
RetinaFaceWithLossCell(加上损失计算)输出总损失的网络
│
▼
TrainingWrapper(计算梯度 + 优化器更新)输出总损失的网络
│
▼
参数更新完成'''
import math
from functools import reduce
import numpy as np
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor
from mindspore.parallel._auto_parallel_context import auto_parallel_context
from mindspore.communication.management import get_group_size
# ResNet
def _weight_variable(shape, factor=0.01):
init_value = np.random.randn(*shape).astype(np.float32) * factor
return Tensor(init_value)
def _conv3x3(in_channel, out_channel, stride=1):
weight_shape = (out_channel, in_channel, 3, 3)
weight = _weight_variable(weight_shape)
return nn.Conv2d(in_channel, out_channel,
kernel_size=3, stride=stride, padding=1, pad_mode='pad', weight_init=weight)
def _conv1x1(in_channel, out_channel, stride=1):
weight_shape = (out_channel, in_channel, 1, 1)
weight = _weight_variable(weight_shape)
return nn.Conv2d(in_channel, out_channel,
kernel_size=1, stride=stride, padding=0, pad_mode='pad', weight_init=weight)
def _conv7x7(in_channel, out_channel, stride=1):
weight_shape = (out_channel, in_channel, 7, 7)
weight = _weight_variable(weight_shape)
return nn.Conv2d(in_channel, out_channel,
kernel_size=7, stride=stride, padding=3, pad_mode='pad', weight_init=weight)
def _bn(channel):
return nn.BatchNorm2d(channel)
def _bn_last(channel):
return nn.BatchNorm2d(channel)
def _fc(in_channel, out_channel):
weight_shape = (out_channel, in_channel)
weight = _weight_variable(weight_shape)
return nn.Dense(in_channel, out_channel, has_bias=True, weight_init=weight, bias_init=0)
class ResidualBlock(nn.Cell):
expansion = 4
def __init__(self,
in_channel,
out_channel,
stride=1):
super(ResidualBlock, self).__init__()
channel = out_channel // self.expansion
self.conv1 = _conv1x1(in_channel, channel, stride=1)
self.bn1 = _bn(channel)
self.conv2 = _conv3x3(channel, channel, stride=stride)
self.bn2 = _bn(channel)
self.conv3 = _conv1x1(channel, out_channel, stride=1)
self.bn3 = _bn_last(out_channel)
self.relu = nn.ReLU()
self.down_sample = False
if stride != 1 or in_channel != out_channel:
self.down_sample = True
self.down_sample_layer = None
if self.down_sample:
self.down_sample_layer = nn.SequentialCell([_conv1x1(in_channel, out_channel, stride),
_bn(out_channel)])
self.add = ops.Add()
def construct(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.down_sample:
identity = self.down_sample_layer(identity)
out = self.add(out, identity)
out = self.relu(out)
return out
class ResNet(nn.Cell):
def __init__(self,
block,
layer_nums,
in_channels,
out_channels,
strides,
num_classes):
super(ResNet, self).__init__()
if not len(layer_nums) == len(in_channels) == len(out_channels) == 4:
raise ValueError("the length of layer_num, in_channels, out_channels list must be 4!")
self.conv1 = _conv7x7(3, 64, stride=2)
self.bn1 = _bn(64)
self.relu = ops.ReLU()
self.pad = ops.Pad(((0, 0), (0, 0), (1, 0), (1, 0)))
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode="valid")
self.layer1 = self._make_layer(block,
layer_nums[0],
in_channel=in_channels[0],
out_channel=out_channels[0],
stride=strides[0])
self.layer2 = self._make_layer(block,
layer_nums[1],
in_channel=in_channels[1],
out_channel=out_channels[1],
stride=strides[1])
self.layer3 = self._make_layer(block,
layer_nums[2],
in_channel=in_channels[2],
out_channel=out_channels[2],
stride=strides[2])
self.layer4 = self._make_layer(block,
layer_nums[3],
in_channel=in_channels[3],
out_channel=out_channels[3],
stride=strides[3])
self.mean = ops.ReduceMean(keep_dims=True)
self.flatten = nn.Flatten()
self.end_point = _fc(out_channels[3], num_classes)
def _make_layer(self, block, layer_num, in_channel, out_channel, stride):
layers = []
resnet_block = block(in_channel, out_channel, stride=stride)
layers.append(resnet_block)
for _ in range(1, layer_num):
resnet_block = block(out_channel, out_channel, stride=1)
layers.append(resnet_block)
return nn.SequentialCell(layers)
def construct(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pad(x)
c1 = self.maxpool(x)
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
out = self.mean(c5, (2, 3))
out = self.flatten(out)
out = self.end_point(out)
return c3, c4, c5
def resnet50(class_num=10):
return ResNet(ResidualBlock,
[3, 4, 6, 3],
[64, 256, 512, 1024],
[256, 512, 1024, 2048],
[1, 2, 2, 2],
class_num)
# RetinaFace
def Init_KaimingUniform(arr_shape, a=0, nonlinearity='leaky_relu', has_bias=False):
def _calculate_in_and_out(arr_shape):
dim = len(arr_shape)
if dim < 2:
raise ValueError("If initialize data with xavier uniform, the dimension of data must greater than 1.")
n_in = arr_shape[1]
n_out = arr_shape[0]
if dim > 2:
counter = reduce(lambda x, y: x * y, arr_shape[2:])
n_in *= counter
n_out *= counter
return n_in, n_out
def calculate_gain(nonlinearity, a=None):
linear_fans = ['linear', 'conv1d', 'conv2d', 'conv3d',
'conv_transpose1d', 'conv_transpose2d', 'conv_transpose3d']
if nonlinearity in linear_fans or nonlinearity == 'sigmoid':
return 1
if nonlinearity == 'tanh':
return 5.0 / 3
if nonlinearity == 'relu':
return math.sqrt(2.0)
if nonlinearity == 'leaky_relu':
if a is None:
negative_slope = 0.01
elif not isinstance(a, bool) and isinstance(a, int) or isinstance(a, float):
negative_slope = a
else:
raise ValueError("negative_slope {} not a valid number".format(a))
return math.sqrt(2.0 / (1 + negative_slope ** 2))
raise ValueError("Unsupported nonlinearity {}".format(nonlinearity))
fan_in, _ = _calculate_in_and_out(arr_shape)
gain = calculate_gain(nonlinearity, a)
std = gain / math.sqrt(fan_in)
bound = math.sqrt(3.0) * std
weight = np.random.uniform(-bound, bound, arr_shape).astype(np.float32)
bias = None
if has_bias:
bound_bias = 1 / math.sqrt(fan_in)
bias = np.random.uniform(-bound_bias, bound_bias, arr_shape[0:1]).astype(np.float32)
bias = Tensor(bias)
return Tensor(weight), bias
class ConvBNReLU(nn.SequentialCell):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding, groups, norm_layer, leaky=0):
weight_shape = (out_planes, in_planes, kernel_size, kernel_size)
kaiming_weight, _ = Init_KaimingUniform(weight_shape, a=math.sqrt(5))
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, pad_mode='pad', padding=padding, group=groups,
has_bias=False, weight_init=kaiming_weight),
norm_layer(out_planes),
nn.LeakyReLU(alpha=leaky)
)
class ConvBN(nn.SequentialCell):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding, groups, norm_layer):
weight_shape = (out_planes, in_planes, kernel_size, kernel_size)
kaiming_weight, _ = Init_KaimingUniform(weight_shape, a=math.sqrt(5))
super(ConvBN, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, pad_mode='pad', padding=padding, group=groups,
has_bias=False, weight_init=kaiming_weight),
norm_layer(out_planes),
)
class SSH(nn.Cell):
def __init__(self, in_channel, out_channel):
super(SSH, self).__init__()
assert out_channel % 4 == 0
leaky = 0
if out_channel <= 64:
leaky = 0.1
norm_layer = nn.BatchNorm2d
self.conv3X3 = ConvBN(in_channel, out_channel // 2, kernel_size=3, stride=1, padding=1, groups=1,
norm_layer=norm_layer)
self.conv5X5_1 = ConvBNReLU(in_channel, out_channel // 4, kernel_size=3, stride=1, padding=1, groups=1,
norm_layer=norm_layer, leaky=leaky)
self.conv5X5_2 = ConvBN(out_channel // 4, out_channel // 4, kernel_size=3, stride=1, padding=1, groups=1,
norm_layer=norm_layer)
self.conv7X7_2 = ConvBNReLU(out_channel // 4, out_channel // 4, kernel_size=3, stride=1, padding=1, groups=1,
norm_layer=norm_layer, leaky=leaky)
self.conv7X7_3 = ConvBN(out_channel // 4, out_channel // 4, kernel_size=3, stride=1, padding=1, groups=1,
norm_layer=norm_layer)
self.cat = ops.Concat(axis=1)
self.relu = nn.ReLU()
def construct(self, x):
conv3X3 = self.conv3X3(x)
conv5X5_1 = self.conv5X5_1(x)
conv5X5 = self.conv5X5_2(conv5X5_1)
conv7X7_2 = self.conv7X7_2(conv5X5_1)
conv7X7 = self.conv7X7_3(conv7X7_2)
out = self.cat((conv3X3, conv5X5, conv7X7))
out = self.relu(out)
return out
class FPN(nn.Cell):
def __init__(self):
super(FPN, self).__init__()
out_channels = 256
leaky = 0
if out_channels <= 64:
leaky = 0.1
norm_layer = nn.BatchNorm2d
self.output1 = ConvBNReLU(512, 256, kernel_size=1, stride=1, padding=0, groups=1,
norm_layer=norm_layer, leaky=leaky)
self.output2 = ConvBNReLU(1024, 256, kernel_size=1, stride=1, padding=0, groups=1,
norm_layer=norm_layer, leaky=leaky)
self.output3 = ConvBNReLU(2048, 256, kernel_size=1, stride=1, padding=0, groups=1,
norm_layer=norm_layer, leaky=leaky)
self.merge1 = ConvBNReLU(256, 256, kernel_size=3, stride=1, padding=1, groups=1,
norm_layer=norm_layer, leaky=leaky)
self.merge2 = ConvBNReLU(256, 256, kernel_size=3, stride=1, padding=1, groups=1,
norm_layer=norm_layer, leaky=leaky)
def construct(self, input1, input2, input3):
output1 = self.output1(input1)
output2 = self.output2(input2)
output3 = self.output3(input3)
up3 = ops.ResizeNearestNeighbor([ops.Shape()(output2)[2], ops.Shape()(output2)[3]])(output3)
output2 = up3 + output2
output2 = self.merge2(output2)
up2 = ops.ResizeNearestNeighbor([ops.Shape()(output1)[2], ops.Shape()(output1)[3]])(output2)
output1 = up2 + output1
output1 = self.merge1(output1)
return output1, output2, output3
class ClassHead(nn.Cell):
def __init__(self, inchannels=512, num_anchors=3):
super(ClassHead, self).__init__()
self.num_anchors = num_anchors
weight_shape = (self.num_anchors * 2, inchannels, 1, 1)
kaiming_weight, kaiming_bias = Init_KaimingUniform(weight_shape, a=math.sqrt(5), has_bias=True)
self.conv1x1 = nn.Conv2d(inchannels, self.num_anchors * 2, kernel_size=(1, 1), stride=1, padding=0,
has_bias=True, weight_init=kaiming_weight, bias_init=kaiming_bias)
self.permute = ops.Transpose()
self.reshape = ops.Reshape()
def construct(self, x):
out = self.conv1x1(x)
out = self.permute(out, (0, 2, 3, 1))
return self.reshape(out, (ops.Shape()(out)[0], -1, 2))
class BboxHead(nn.Cell):
def __init__(self, inchannels=512, num_anchors=3):
super(BboxHead, self).__init__()
weight_shape = (num_anchors * 4, inchannels, 1, 1)
kaiming_weight, kaiming_bias = Init_KaimingUniform(weight_shape, a=math.sqrt(5), has_bias=True)
self.conv1x1 = nn.Conv2d(inchannels, num_anchors * 4, kernel_size=(1, 1), stride=1, padding=0, has_bias=True,
weight_init=kaiming_weight, bias_init=kaiming_bias)
self.permute = ops.Transpose()
self.reshape = ops.Reshape()
def construct(self, x):
out = self.conv1x1(x)
out = self.permute(out, (0, 2, 3, 1))
return self.reshape(out, (ops.Shape()(out)[0], -1, 4))
class LandmarkHead(nn.Cell):
def __init__(self, inchannels=512, num_anchors=3):
super(LandmarkHead, self).__init__()
weight_shape = (num_anchors * 10, inchannels, 1, 1)
kaiming_weight, kaiming_bias = Init_KaimingUniform(weight_shape, a=math.sqrt(5), has_bias=True)
self.conv1x1 = nn.Conv2d(inchannels, num_anchors * 10, kernel_size=(1, 1), stride=1, padding=0, has_bias=True,
weight_init=kaiming_weight, bias_init=kaiming_bias)
self.permute = ops.Transpose()
self.reshape = ops.Reshape()
def construct(self, x):
out = self.conv1x1(x)
out = self.permute(out, (0, 2, 3, 1))
return self.reshape(out, (ops.Shape()(out)[0], -1, 10))
'''retinaface网络模型'''
class RetinaFace(nn.Cell):
def __init__(self, phase='train', backbone=None):
super(RetinaFace, self).__init__()
self.phase = phase
self.base = backbone
self.fpn = FPN()
self.ssh1 = SSH(256, 256)
self.ssh2 = SSH(256, 256)
self.ssh3 = SSH(256, 256)
self.ClassHead = self._make_class_head(fpn_num=3, inchannels=[256, 256, 256], anchor_num=[2, 2, 2])
self.BboxHead = self._make_bbox_head(fpn_num=3, inchannels=[256, 256, 256], anchor_num=[2, 2, 2])
self.LandmarkHead = self._make_landmark_head(fpn_num=3, inchannels=[256, 256, 256], anchor_num=[2, 2, 2])
self.cat = ops.Concat(axis=1)
def _make_class_head(self, fpn_num, inchannels, anchor_num):
classhead = nn.CellList()
for i in range(fpn_num):
classhead.append(ClassHead(inchannels[i], anchor_num[i]))
return classhead
def _make_bbox_head(self, fpn_num, inchannels, anchor_num):
bboxhead = nn.CellList()
for i in range(fpn_num):
bboxhead.append(BboxHead(inchannels[i], anchor_num[i]))
return bboxhead
def _make_landmark_head(self, fpn_num, inchannels, anchor_num):
landmarkhead = nn.CellList()
for i in range(fpn_num):
landmarkhead.append(LandmarkHead(inchannels[i], anchor_num[i]))
return landmarkhead
def construct(self, inputs):
f1, f2, f3 = self.base(inputs)
f1, f2, f3 = self.fpn(f1, f2, f3)
# SSH
f1 = self.ssh1(f1)
f2 = self.ssh2(f2)
f3 = self.ssh3(f3)
features = [f1, f2, f3]
bbox = ()
for i, feature in enumerate(features):
bbox = bbox + (self.BboxHead[i](feature),)
bbox_regressions = self.cat(bbox)
cls = ()
for i, feature in enumerate(features):
cls = cls + (self.ClassHead[i](feature),)
classifications = self.cat(cls)
landm = ()
for i, feature in enumerate(features):
landm = landm + (self.LandmarkHead[i](feature),)
ldm_regressions = self.cat(landm)
if self.phase == 'train':
output = (bbox_regressions, classifications, ldm_regressions)
else:
output = (bbox_regressions, ops.Softmax(-1)(classifications), ldm_regressions)
#测试阶段利用Softmax输出的是每个类别的置信度分布,用于后续判断或 NMS 阶段过滤低置信度框
return output
''''
把 RetinaFace 网络输出和多任务损失函数结合起来,返回一个“加权后的总损失
RetinaFaceWithLossCell 的核心作用是:
1.把 网络输出 与 真实标签 对齐。
2.调用 多任务 loss(边框 + 分类 + 关键点)。
3.根据权重 loc_weight、class_weight、landm_weight 合并成一个总损失。
4.返回给训练 wrapper 或 Model,直接用于 梯度计算和优化。
RetinaFaceWithLossCell 返回的是总 loss,但它依然是 nn.Cell,所以可以像普通网络一样训练,只不过前向输出就是 loss,而不是预测值。
network:就是传入的 RetinaFace 网络(backbone+FPN+SSH+heads)
multibox_loss → 多任务损失函数,用于计算:
loss_loc → 边框回归损失
loss_conf → 分类损失
loss_landm → 人脸关键点损失
config → 用来给三个任务的 loss 分配权重:'''
class RetinaFaceWithLossCell(nn.Cell):
def __init__(self, network, multibox_loss, config):
super(RetinaFaceWithLossCell, self).__init__()
self.network = network
self.loc_weight = config['loc_weight']
self.class_weight = config['class_weight']
self.landm_weight = config['landm_weight']
self.multibox_loss = multibox_loss
'''img → 输入图片 batch
loc_t, conf_t, landm_t → 训练时的真实标签(ground truth)
loc_t:真实边框
conf_t:真实分类
landm_t:真实关键点坐标'''
def construct(self, img, loc_t, conf_t, landm_t):
pred_loc, pre_conf, pre_landm = self.network(img)
loss_loc, loss_conf, loss_landm = self.multibox_loss(pred_loc, loc_t, pre_conf, conf_t, pre_landm, landm_t)
return loss_loc * self.loc_weight + loss_conf * self.class_weight + loss_landm * self.landm_weight
'''作用:在 RetinaFaceWithLossCell 的基础上,增加了 训练功能:
调用 network(*args) 计算 loss(这里 network 就是 RetinaFaceWithLossCell)
自动计算 loss 对参数的梯度
多 GPU 梯度归约(可选)
调用 optimizer 更新参数
返回 loss(便于记录)但它依然是 nn.Cell,所以可以像普通网络一样训练,只不过返回值是loss
换句话说,它把 前向 + loss → 反向 → 更新 全流程整合在一个 Cell 中。'''
class TrainingWrapper(nn.Cell):
def __init__(self, network, optimizer, sens=1.0):
super(TrainingWrapper, self).__init__(auto_prefix=False)
self.network = network
self.weights = ms.ParameterTuple(network.trainable_params())
self.optimizer = optimizer
self.grad = ops.GradOperation(get_by_list=True, sens_param=True)
self.sens = sens
self.reducer_flag = False
self.grad_reducer = None
self.parallel_mode = ms.get_auto_parallel_context("parallel_mode")
class_list = [ms.ParallelMode.DATA_PARALLEL, ms.ParallelMode.HYBRID_PARALLEL]
if self.parallel_mode in class_list:
self.reducer_flag = True
if self.reducer_flag:
mean = ms.get_auto_parallel_context("gradients_mean")
if auto_parallel_context().get_device_num_is_set():
degree = ms.get_auto_parallel_context("device_num")
else:
degree = get_group_size()
self.grad_reducer = nn.DistributedGradReducer(optimizer.parameters, mean, degree)
def construct(self, *args):
weights = self.weights
loss = self.network(*args)
sens = ops.Fill()(ops.DType()(loss), ops.Shape()(loss), self.sens)
grads = self.grad(self.network, weights)(*args, sens)
if self.reducer_flag:
# apply grad reducer on grads
grads = self.grad_reducer(grads)
self.optimizer(grads)
return loss
模型用的mindspore格式的retinaface
import mindspore as ms
from mindspore import Tensor, load_checkpoint, load_param_into_net
from retinafacenet import resnet50,RetinaFace
import numpy as np
# 1. 定义推理模型
net=resnet50(1001)
net=RetinaFace(phase='predict',backbone=net)
# 2. 加载训练好的ckpt
param_dict = load_checkpoint(r"RetinaFace-8_737.ckpt")
load_param_into_net(net, param_dict)
# 3. 设置输入张量的shape
input_shape = (1, 3, 640, 640) # batch=1, C,H,W
input_tensor = Tensor(np.zeros(input_shape), ms.float32)
# 4. 编译成 MindIR(.mindir)
from mindspore import export
export(net, input_tensor, file_name="retinaface1", file_format="ONNX")这个是转换脚本
硬件环境(Ascend/GPU/CPU): Ascend310
MindSpore版本: mindspore=2.6
执行模式(PyNative/ Graph):不限
Python版本: Python=3.10
操作系统平台: linux
2.7.0
ascend 910B
用你的代码导出onnx成功,因为没有权重,所以load_checkpoint 被注释了,
RetinaFace-8_737.ckpt是当前网络训练出来的权重吗?先不load试试.
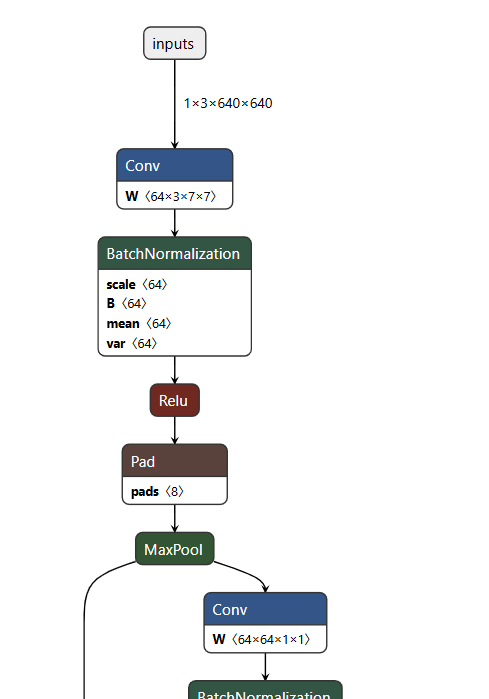
是的,是我训练出来的权重,在ubuntu上gpu训练的,那我现在需要如何解决呢?
可以转换成onnx,但是我用atc转换成om的时候报错,就是这个错误
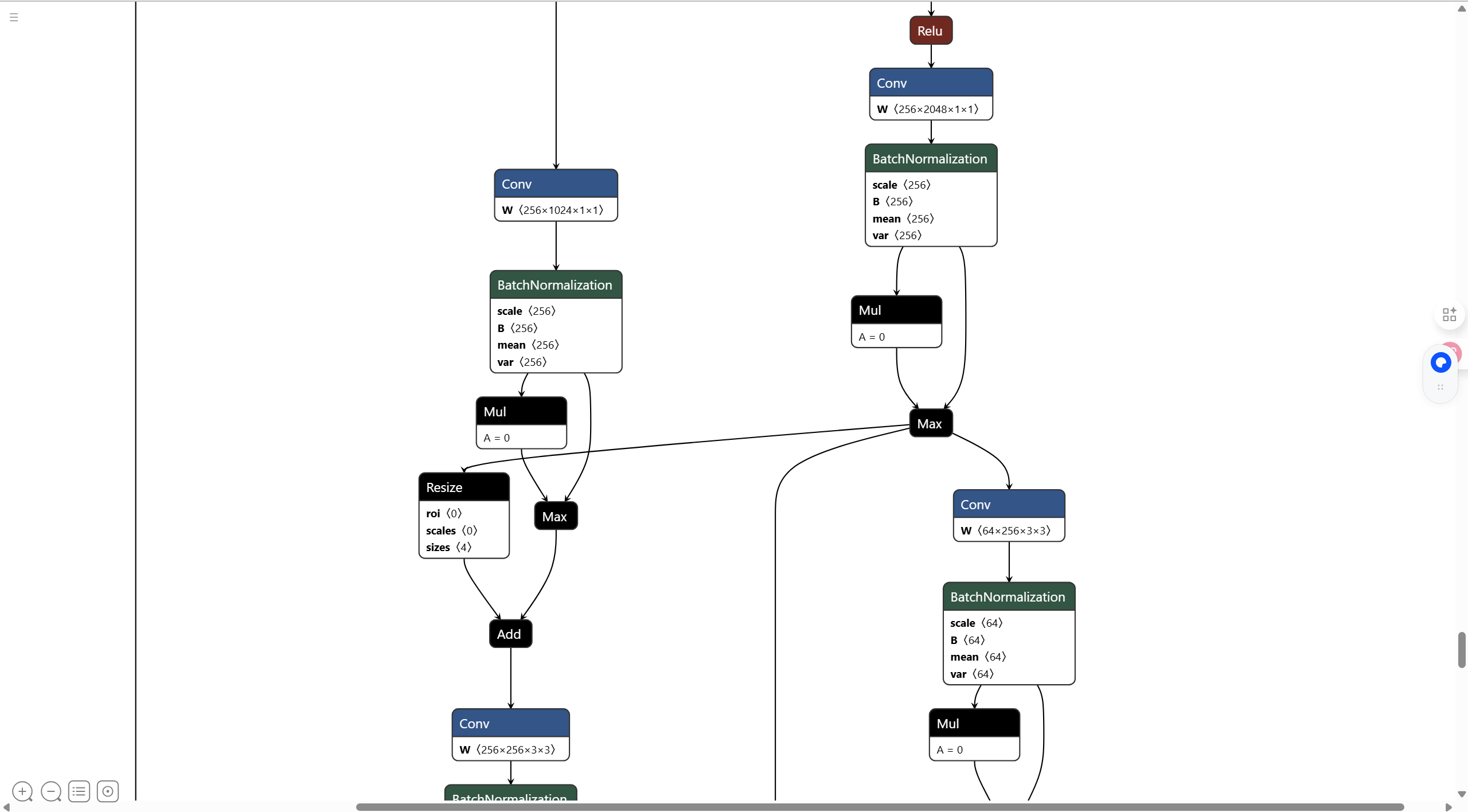
既然你最终要导出ms ,为什么一开始要导出onnx???
因为onnx毕竟是第三方,经过转换会有一些问题存在.
export的时候设置为MINDIR,然后再转换
atc 工具如果有问题需要去cann板块发帖.
atc支持air转换om,我还以为你用的是mindspore lite呢
mindspore导出选 file_format=“AIR”
然后再用atc将air转om吗?
是的
我用8.2.RC1 的atc onnx转换om也成功了.
你的cann版本多少?
啊,你的环境是多少的啊?
cann的版本咋查看,我输入ascend-toolkit –help 找不到命令
/usr/local/Ascend/ascend-toolkit/latest/version.cfg 这个文件
还有/usr/local/Ascend/ascend-toolkit/latest/runtime/version.info