1 系统环境
硬件环境(Ascend/GPU/CPU): Ascend
MindSpore版本: mindspore=2.2.10
执行模式(PyNative/ Graph):PyNative/ Graph
Python版本: Python=3.8.15
操作系统平台: linux
2 报错信息
MTP跑sft大模型过程中遇到任务卡死,无脚本报错,只有平台日志。
The parse job starts. Please wait.
['ROOT_CLUSTER', 'NODE_ANOMALY'] job failed. Please check the detail log.
The parse job is complete.
grep: /home/ma-user/modelarts/log/failure_analysis_result.json: No such file or directory
3 根因分析
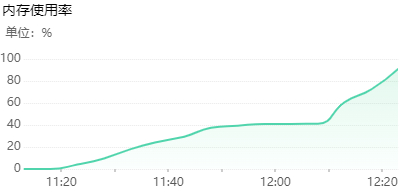
联系平台确认,ModelArt日志打印信息为host内存oom报错,报错信息如下:
['ROOT_CLUSTER'] job failed.
- 可以通过psutil工具打印Host内存利用率,监控内存信息:
import psutil
memory_info = psutil.virtual_memory()
print("总容量:{} GB".format(round(memory_info.total / 1024 / 1024 / 1024, 2)), flush=True)
print("已用容量:{} GB".format(round(memory_info.used / 1024 / 1024 / 1024, 2)), flush=True)
print("可用容量:{} GB".format(round(memory_info.free / 1024 / 1024 / 1024, 2)), flush=True)
print("使用率:{} %".format(memory_info.percent), flush=True)
4 解决方案
确认host内存溢出之后,通过打印日志判断是模型加载数据集过程中,缓存持续飙升导致oom
- 减小数据处理操作的缓冲队列大小(默认值:16)
mindspore.dataset.config.set_prefetch_size(size)
- 设置流水线中各个数据处理操作的缓冲队列大小。
- 缓冲队列的存在使得当前操作在下一操作取走数据前就能开始处理后续数据,各操作异步并发地执行。
- 更大的缓冲队列大小能够减少相邻操作吞吐速率不平衡时的整体处理时延,但也会消耗更大的系统内存。
- 减少数据集处理过程中的map函数的使用也可以降低内存消耗。